आप अपनी क्वेरी में केवल दो कॉलम मांग रहे हैं, इसलिए इंडेक्स वहां जा सकते हैं/होना चाहिए:
- दिनांक समय
- लोडटाइम
अपनी क्वेरी को गति देने का दूसरा तरीका डेटटाइम फ़ील्ड को दो में विभाजित किया जा सकता है:दिनांक और समय।
इस तरह डीबी DATE(...) की गणना के बजाय सीधे दिनांक फ़ील्ड पर समूह बना सकता है।
संपादित:
यदि आप किसी ट्रिगर का उपयोग करना पसंद करते हैं, तो एक नया कॉलम (DATE) बनाएं और इसे newdate कहें , और इसके साथ प्रयास करें (मैं यह देखने के लिए अभी कोशिश नहीं कर सकता कि क्या यह सही है):
CREATE TRIGGER upd_check BEFORE INSERT ON SpeedMonitor
FOR EACH ROW
BEGIN
SET NEW.newdate=DATE(NEW.DateTime);
END
फिर से संपादित:
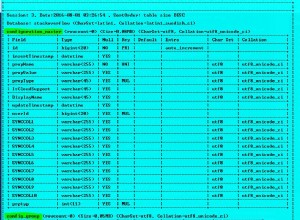
मैंने अभी-अभी लगभग 900,000 रिकॉर्ड्स से भरे समान टेबल स्पीडमॉनिटर के साथ एक db बनाया है।
फिर मैं क्वेरी SELECT newdate,AVG(LoadTime) loadtime FROM speedmonitor GROUP BY newdate और इसमें लगभग 100 का समय लगा !!
newdate फ़ील्ड पर अनुक्रमणिका को निकालना (और RESET QUERY CACHE का उपयोग करके कैश साफ़ करना और फ्लश टेबल ), एक ही क्वेरी में 0.6s लगे!!!
सिर्फ तुलना के लिए:क्वेरी चुनें दिनांक (दिनांक समय), औसत (लोडटाइम) लोडटाइम स्पीडमॉनिटर ग्रुप बाय DATE(DateTime) 0.9s लिया।
तो मुझे लगता है कि नई तारीख पर सूचकांक अच्छा नहीं है:इसे हटा दें।
मैं अब जितने रिकॉर्ड जोड़ सकता हूं और दो प्रश्नों का फिर से परीक्षण करने जा रहा हूं।
अंतिम संपादन:
नए दिनांक और दिनांक समय स्तंभों पर अनुक्रमणिका निकालना, जिसमें 8mln रिकॉर्ड हैं स्पीडमॉनिटर टेबल पर, ये रहे नतीजे:
- नए दिनांक कॉलम पर चयन और समूहीकरण:7.5s
- DATE(DateTime) फ़ील्ड को चुनना और समूहीकृत करना:13.7s
मुझे लगता है कि यह एक अच्छा स्पीडअप है।
mysql कमांड प्रॉम्प्ट के अंदर क्वेरी निष्पादित करने में समय लगता है।