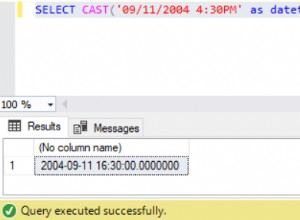
आपका डेटा बुरी तरह से है ।
InnoDB शारीरिक रूप से एक साथ "करीबी" PK के साथ पंक्तियों को संग्रहीत करेगा। चूंकि आपके चाइल्ड टेबल सरोगेट पीके का उपयोग करते हैं, इसलिए उनकी पंक्तियों को बेतरतीब ढंग से संग्रहीत किया जाएगा। जब "मास्टर" तालिका में दी गई पंक्ति के लिए गणना करने का समय आता है, तो डीबीएमएस को चाइल्ड टेबल से संबंधित पंक्तियों को इकट्ठा करने के लिए सभी जगह कूदना चाहिए।
सरोगेट कुंजियों के बजाय, अधिक "प्राकृतिक" कुंजियों का उपयोग करने का प्रयास करें, जिसमें माता-पिता का पीके अग्रणी किनारे पर है:
score_adjustments:
entry_id: INT(11), FOREIGN KEY (entries.id)
created: DATETIME
amount: INT(4)
PRIMARY KEY (entry_id, created)
rating_adjustments:
entry_id: INT(11), FOREIGN KEY (entries.id)
rating_no: INT(11)
rating: DOUBLE
PRIMARY KEY (entry_id, rating_no)
नोट:यह मानता है कि created का रिज़ॉल्यूशन काफी अच्छा है और rating_no प्रति entry_id . के लिए एकाधिक रेटिंग की अनुमति देने के लिए जोड़ा गया था . यह सिर्फ एक उदाहरण है - आप अपनी आवश्यकताओं के अनुसार पीके बदल सकते हैं।
यह समान entry_id . से संबंधित पंक्तियों को "बल" देगा भौतिक रूप से एक साथ संग्रहीत किया जाना है, इसलिए एक एसयूएम या एवीजी की गणना पीके/क्लस्टरिंग कुंजी पर केवल एक रेंज स्कैन द्वारा और बहुत कम I/Os के साथ की जा सकती है।
वैकल्पिक रूप से (उदाहरण के लिए यदि आप MyISAM का उपयोग कर रहे हैं जो क्लस्टरिंग का समर्थन नहीं करता है), कवर इंडेक्स के साथ क्वेरी ताकि क्वेरी के दौरान चाइल्ड टेबल को बिल्कुल भी छुआ न जाए।
उसके ऊपर, आप अपने डिज़ाइन को असामान्य बना सकते हैं, और वर्तमान परिणामों को मूल तालिका में कैश कर सकते हैं:
- SUM(score_adjustments.amount) को एक भौतिक फ़ील्ड के रूप में संग्रहीत करें और हर बार
score_adjustmentsसे कोई पंक्ति डालने, अपडेट करने या हटाने पर ट्रिगर के माध्यम से इसे समायोजित करें । - SUM(rating_adjustments.rating) को "S" और के रूप में स्टोर करें COUNT(rating_adjustments.rating) "सी" के रूप में। जब
rating_adjustmentsमें एक पंक्ति जोड़ी जाती है , इसे S में जोड़ें और C को बढ़ाएँ। औसत प्राप्त करने के लिए रन-टाइम पर S/C की गणना करें। इसी तरह अपडेट को हैंडल करें और डिलीट करें।