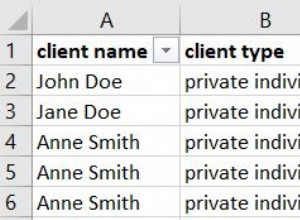
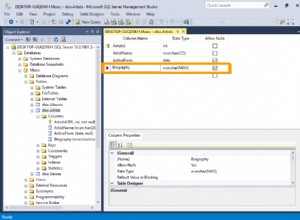
यदि आप एकाधिक स्तंभों के बीच डुप्लीकेट गिनना चाहते हैं, तो group by . का उपयोग करें :
select ColumnA, ColumnB, ColumnC, count(*) as NumDuplicates
from table
group by ColumnA, ColumnB, ColumnC
यदि आप केवल डुप्लिकेट किए गए मान चाहते हैं, तो गिनती 1 से बड़ी है। आप इसे having का उपयोग करके प्राप्त करते हैं खंड:
select ColumnA, ColumnB, ColumnC, count(*) as NumDuplicates
from table
group by ColumnA, ColumnB, ColumnC
having NumDuplicates > 1
यदि आप वास्तव में चाहते हैं कि सभी डुप्लिकेट पंक्तियाँ वापस आ जाएँ, तो अंतिम क्वेरी को मूल डेटा में वापस शामिल करें:
select t.*
from table t join
(select ColumnA, ColumnB, ColumnC, count(*) as NumDuplicates
from table
group by ColumnA, ColumnB, ColumnC
having NumDuplicates > 1
) tsum
on t.ColumnA = tsum.ColumnA and t.ColumnB = tsum.ColumnB and t.ColumnC = tsum.ColumnC
यह काम करेगा, मान लीजिए कि कॉलम मानों में से कोई भी न्यूल नहीं है। अगर ऐसा है, तो कोशिश करें:
on (t.ColumnA = tsum.ColumnA or t.ColumnA is null and tsum.ColumnA is null) and
(t.ColumnB = tsum.ColumnB or t.ColumnB is null and tsum.ColumnB is null) and
(t.ColumnC = tsum.ColumnC or t.ColumnC is null and tsum.ColumnC is null)
संपादित करें:
अगर आपके पास NULL है मान, आप NULL . का भी उपयोग कर सकते हैं -सुरक्षित ऑपरेटर:
on t.ColumnA <=> tsum.ColumnA and
t.ColumnB <=> tsum.ColumnB and
t.ColumnC <=> tsum.ColumnC