यह संभव है लेकिन रखरखाव के बहुत सारे प्रयास करने पड़ते हैं, स्पष्टीकरण -
डेटा की लंबवत स्केलिंग (एसक्यूएल डेटाबेस में सामान्यीकरण का पर्यायवाची) अंतरिक्ष अतिरेक को कम करने के लिए डेटा कॉलम वार को कई तालिकाओं में विभाजित करने के रूप में संदर्भित किया जाता है। उपयोगकर्ता तालिका का उदाहरण -
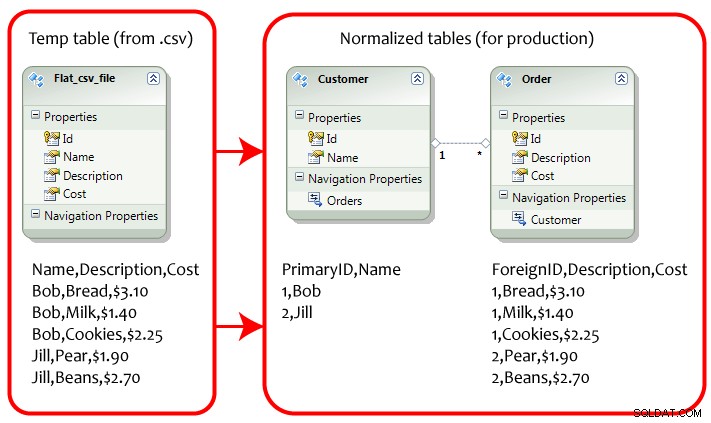
डेटा की क्षैतिज स्केलिंग (शार्डिंग का पर्यायवाची) डेटा लाने में लगने वाले समय को कम करने के लिए पंक्ति के अनुसार कई तालिकाओं में विभाजित करने के रूप में संदर्भित किया जाता है। उपयोगकर्ता तालिका का उदाहरण -
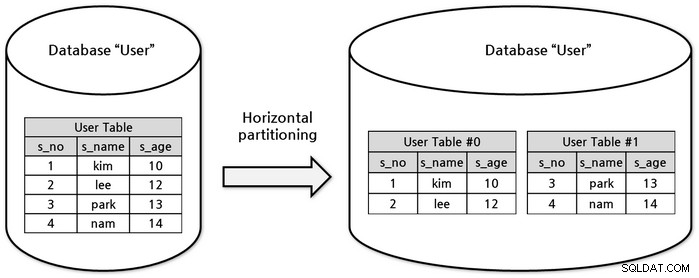
यहां ध्यान देने योग्य मुख्य बिंदु है जैसा कि हम देख सकते हैं कि SQL डेटाबेस में तालिकाओं को संबंधित डेटा की कई तालिकाओं में सामान्यीकृत किया जाता है। कई मशीनों पर ऐसी तालिका के डेटा को शार्प करने के लिए, आपको संबंधित सामान्यीकृत डेटा को तदनुसार शार्प करने की आवश्यकता होगी जो बदले में रखरखाव के प्रयासों को बढ़ाएगा। SQL डेटाबेस के ऊपर प्रस्तुत उदाहरण की तरह,
यदि आप ग्राहक डेटा की कुछ पंक्तियों को अन्य मशीन (शार्डिंग के रूप में संदर्भित) पर ले जाते हैं, तो आपको इसके संबंधित ऑर्डर डेटा को उसी मशीन पर ले जाना होगा जो कई संबंधित तालिकाओं के मामले में परेशानी का काम होगा।
एनओएसक्यूएल डेटाबेस के लिए यह सुविधाजनक है क्योंकि वे फ्लैट टेबल संरचना का पालन करते हैं (डेटा सामान्यीकृत रूप के बजाय एकत्रित रूप में संग्रहीत होता है)।