मैंने एक नमूना ट्रांसफॉर्मेशन (राइट क्लिक करें और सेव लिंक चुनें) को एक साथ रखा है आपने जो प्रदान किया उसके आधार पर। एकमात्र कदम जो मुझे थोड़ा अनिश्चित लगता है वह है अंतिम तालिका इनपुट। मैं मूल रूप से तालिका में शामिल होने का डेटा लिख रहा हूं और यदि कोई विशिष्ट संबंध पहले से मौजूद है तो इसे विफल होने दे रहा हूं।
नोट:
यह समाधान वास्तव में पूरा नहीं करता है "सभी दृष्टिकोणों में सत्यापन से कुछ शामिल होना चाहिए और एक रोलबैक रणनीति को एक सम्मिलित विफल होना चाहिए, या संदर्भात्मक अखंडता बनाए रखने में विफल होना चाहिए।" मानदंड, हालांकि यह शायद विफल नहीं होगा। यदि आप वास्तव में कुछ जटिल सेटअप करना चाहते हैं तो हम कर सकते हैं लेकिन यह निश्चित रूप से आपको इन परिवर्तनों के साथ आगे बढ़ना चाहिए।

डेटा प्रवाह चरण के अनुसार
1. हम आपकी फाइल में पढ़ने के साथ शुरू करते हैं। मेरे मामले में मैंने इसे सीएसवी में बदल दिया लेकिन टैब भी ठीक है। 
2. अब हम combination lookup/update का उपयोग करके कर्मचारी नाम को कर्मचारी तालिका में सम्मिलित करने जा रहे हैं डालने के बाद हम कर्मचारी_आईडी को हमारे डेटास्ट्रीम में id . के रूप में जोड़ते हैं और EmployeeName हटा दें डेटा स्ट्रीम से।

3. यहां हम id . का नाम बदलने के लिए केवल मान चुनें चरण का उपयोग कर रहे हैं कर्मचारी_आईडी . के लिए फ़ील्ड 
4. जैसे हमने कर्मचारियों को किया था वैसे ही जॉब टाइटल डालें और शीर्षक आईडी को हमारे डेटास्ट्रीम में जोड़ें JobLevelHistory को भी हटा दें डेटास्ट्रीम से।

5. शीर्षक आईडी का सरल नाम बदलकर title_id कर दें (चरण 3 देखें) 
6. कार्यालय सम्मिलित करें, आईडी प्राप्त करें, OfficeHistory को स्ट्रीम से निकालें।

7. ऑफिस आईडी का साधारण नाम बदलकर office_id कर दें (चरण 3 देखें)

8. employee_id,office_id मानों के साथ अंतिम चरण से डेटा को दो स्ट्रीम में कॉपी करें और employee_id,title_id क्रमशः।

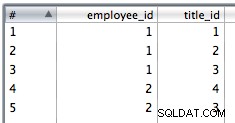
9. जॉइन डेटा डालने के लिए टेबल इंसर्ट का इस्तेमाल करें। मैंने इसे सम्मिलित त्रुटियों को अनदेखा करने के लिए चुना है क्योंकि डुप्लिकेट हो सकते हैं और पीके बाधाएं कुछ पंक्तियों को विफल कर देंगी।
आउटपुट टेबल