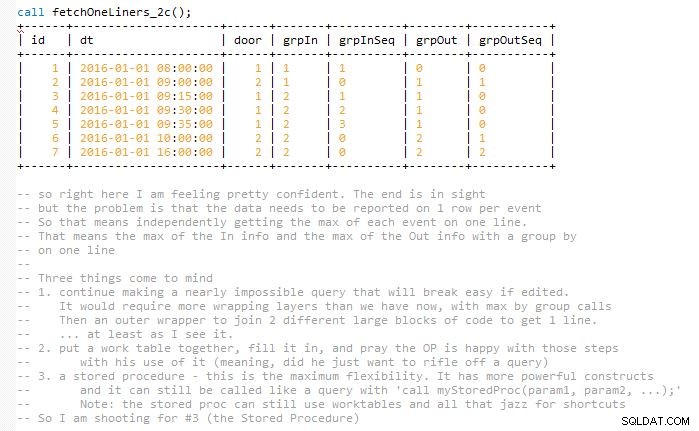
यह अंतिम क्वेरी को एक शॉट में समाप्त किए बिना समाधान को आसानी से बनाए रखने का प्रयास करता है, जो इसके आकार (मेरे दिमाग में) को लगभग दोगुना कर देता। ऐसा इसलिए है क्योंकि परिणामों का मिलान होना चाहिए और मिलान किए गए इन और आउट इवेंट के साथ एक पंक्ति में प्रतिनिधित्व करना चाहिए। तो अंत में, मैं कुछ वर्कटेबल्स का उपयोग करता हूं। इसे एक संग्रहीत कार्यविधि में कार्यान्वित किया जाता है।
संग्रहीत कार्यविधि कई चरों का उपयोग करती है जिन्हें cross join . के साथ लाया जाता है . क्रॉस जॉइन को वेरिएबल्स को इनिशियलाइज़ करने के लिए सिर्फ एक मैकेनिज्म के रूप में सोचें। चर सुरक्षित रूप से बनाए रखा जाता है, इसलिए मेरा मानना है कि इस दस्तावेज़
अक्सर परिवर्तनीय प्रश्नों में संदर्भित। संदर्भ के महत्वपूर्ण भाग एक पंक्ति पर चरों की सुरक्षित हैंडलिंग हैं जो उन्हें अन्य स्तंभों से पहले सेट करने के लिए मजबूर करते हैं। यह greatest() . के माध्यम से प्राप्त किया जाता है और least() उन कार्यों के उपयोग के बिना सेट किए जा रहे चर की तुलना में उच्च प्राथमिकता वाले फ़ंक्शन। यह भी ध्यान दें कि coalesce() अक्सर एक ही उद्देश्य के लिए प्रयोग किया जाता है। यदि उनका उपयोग अजीब लगता है, जैसे कि 0, या 0 से अधिक ज्ञात संख्या का सबसे बड़ा लेना, तो यह जानबूझकर किया गया है। सेट किए जा रहे वेरिएबल्स के वरीयता क्रम को बाध्य करने के लिए जानबूझकर।
क्वेरी के कॉलम में dummy2 . जैसी चीज़ों का नाम दिया गया है आदि ऐसे कॉलम हैं जिनका आउटपुट उपयोग नहीं किया गया था, लेकिन उनका उपयोग greatest() के अंदर वेरिएबल सेट करने के लिए किया गया था। या एक और। यह ऊपर उल्लेख किया गया था। 7777 जैसा आउटपुट तीसरे स्लॉट में प्लेसहोल्डर था, क्योंकि if() के लिए कुछ वैल्यू की जरूरत थी। जिसका इस्तेमाल किया गया था। तो उस सब पर ध्यान न दें।
मैंने कोड के कई स्क्रीन शॉट्स शामिल किए हैं क्योंकि यह आउटपुट की कल्पना करने में आपकी मदद करने के लिए परत दर परत प्रगति करता है। और कैसे विकास के इन पुनरावृत्तियों को धीरे-धीरे अगले चरण में पूर्व चरण में विस्तारित करने के लिए जोड़ दिया जाता है।
मुझे यकीन है कि मेरे साथी इस पर एक प्रश्न में सुधार कर सकते हैं। मैं इसे इस तरह खत्म कर सकता था। लेकिन मेरा मानना है कि इसके परिणामस्वरूप एक भ्रमित करने वाली गड़बड़ी होती है जो छूने पर टूट जाती है।
स्कीमा:
create table attendance2(Id int, DateTime datetime, Door char(20), Active_door char(20));
INSERT INTO attendance2 VALUES
( 1, '2016-01-01 08:00:00', 'In', ''),
( 2, '2016-01-01 09:00:00', 'Out', ''),
( 3, '2016-01-01 09:15:00', 'In', ''),
( 4, '2016-01-01 09:30:00', 'In', ''),
( 5, '2016-01-01 09:35:00', '', 'On'),
( 6, '2016-01-01 10:00:00', 'Out', ''),
( 7, '2016-01-01 16:00:00', '', 'Off');
drop table if exists oneLinersDetail;
create table oneLinersDetail
( -- architect this depending on multi-user concurrency
id int not null,
dt datetime not null,
door int not null,
grpIn int not null,
grpInSeq int not null,
grpOut int not null,
grpOutSeq int not null
);
drop table if exists oneLinersSummary;
create table oneLinersSummary
( -- architect this depending on multi-user concurrency
id int not null,
grpInSeq int null,
grpOutSeq int null,
checkIn datetime null, -- we are hoping in the end it is not null
checkOut datetime null -- ditto
);
संग्रहीत प्रक्रिया:
DROP PROCEDURE IF EXISTS fetchOneLiners;
DELIMITER $$
CREATE PROCEDURE fetchOneLiners()
BEGIN
truncate table oneLinersDetail; -- architect this depending on multi-user concurrency
insert oneLinersDetail(id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq)
select id,dt,door,grpIn,grpInSeq,grpOut,grpOutSeq
from
( select id,dt,door,
if(@lastEvt!=door and door=1,
greatest(@grpIn:example@sqldat.com+1,0),
7777) as dummy2, -- this output column we don't care about (we care about the variable being set)
if(@lastEvt!=door and door=2,
greatest(@grpOut:example@sqldat.com+1,0),
7777) as dummy3, -- this output column we don't care about (we care about the variable being set)
if (@lastEvt!=door,greatest(@flip:=1,0),least(@flip:=0,1)) as flip,
if (door=1 and @flip=1,least(@grpOutSeq:=0,1),7777) as dummy4,
if (door=1 and @flip=1,greatest(@grpInSeq:=1,0),7777) as dummy5,
if (door=1 and @flip!=1,greatest(@grpInSeq:example@sqldat.comnSeq+1,0),7777) as dummy6,
if (door=2 and @flip=1,least(@grpInSeq:=0,1),7777) as dummy7,
if (door=2 and @flip=1,greatest(@grpOutSeq:=1,0),7777) as dummy8,
if (door=2 and @flip!=1,greatest(@grpOutSeq:example@sqldat.com+1,0),7777) as dummy9,
@grpIn as grpIn,
@grpInSeq as grpInSeq,
@grpOut as grpOut,
@grpOutSeq as grpOutSeq,
@lastEvt:=door as lastEvt
from
( select id,`datetime` as dt,
CASE
WHEN Door='in' or Active_door='on' THEN 1
ELSE 2
END as door
from attendance2
order by id
) xD1 -- derived table #1
cross join (select @grpIn:=0,@grpInSeq:=0,@grpOut:=0,@grpOutSeq:=0,@lastEvt:=-1,@flip:=0) xParams
order by id
) xD2 -- derived table #2
order by id;
-- select * from oneLinersDetail;
truncate table oneLinersSummary; -- architect this depending on multi-user concurrency
insert oneLinersSummary (id,grpInSeq,grpOutSeq,checkIn,checkOut)
select distinct grpIn,null,null,null,null
from oneLinersDetail
order by grpIn;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpIn,max(grpInSeq) m
from oneLinersDetail
where door=1
group by grpIn
) d1
on d1.grpIn=ols.id
set ols.grpInSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join
( select grpOut,max(grpOutSeq) m
from oneLinersDetail
where door=2
group by grpOut
) d1
on d1.grpOut=ols.id
set ols.grpOutSeq=d1.m;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=1 and old.grpIn=ols.id and old.grpInSeq=ols.grpInSeq
set ols.checkIn=old.dt;
-- select * from oneLinersSummary;
update oneLinersSummary ols
join oneLinersDetail old
on old.door=2 and old.grpOut=ols.id and old.grpOutSeq=ols.grpOutSeq
set ols.checkOut=old.dt;
-- select * from oneLinersSummary;
-- dump out the results
select id,checkIn,checkOut
from oneLinersSummary
order by id;
-- rows are left in those two tables (oneLinersDetail,oneLinersSummary)
END$$
DELIMITER ;
परीक्षण:
call fetchOneLiners();
+----+---------------------+---------------------+
| id | checkIn | checkOut |
+----+---------------------+---------------------+
| 1 | 2016-01-01 08:00:00 | 2016-01-01 09:00:00 |
| 2 | 2016-01-01 09:35:00 | 2016-01-01 16:00:00 |
+----+---------------------+---------------------+
यह उत्तर का अंत है। नीचे एक डेवलपर के उन चरणों के विज़ुअलाइज़ेशन के लिए है जो संग्रहीत प्रक्रिया को पूरा करने के लिए प्रेरित करते हैं।
विकास के संस्करण जो अंत तक चलते रहे। उम्मीद है कि यह केवल एक मध्यम आकार के भ्रामक कोड को छोड़ने के विरोध में विज़ुअलाइज़ेशन में सहायता करता है।
चरण ए
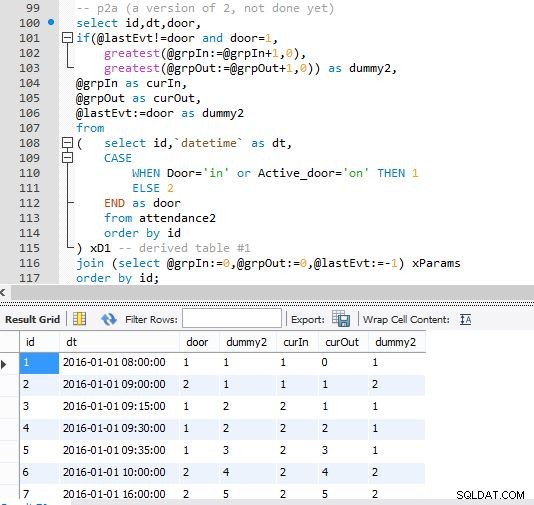
चरण बी
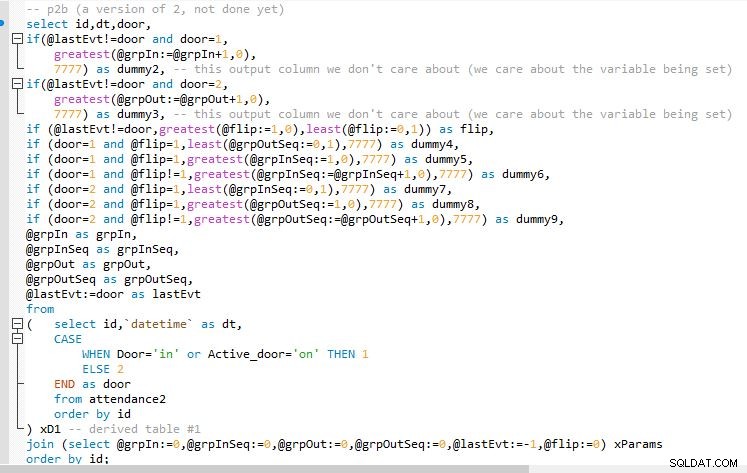
चरण B आउटपुट

चरण सी
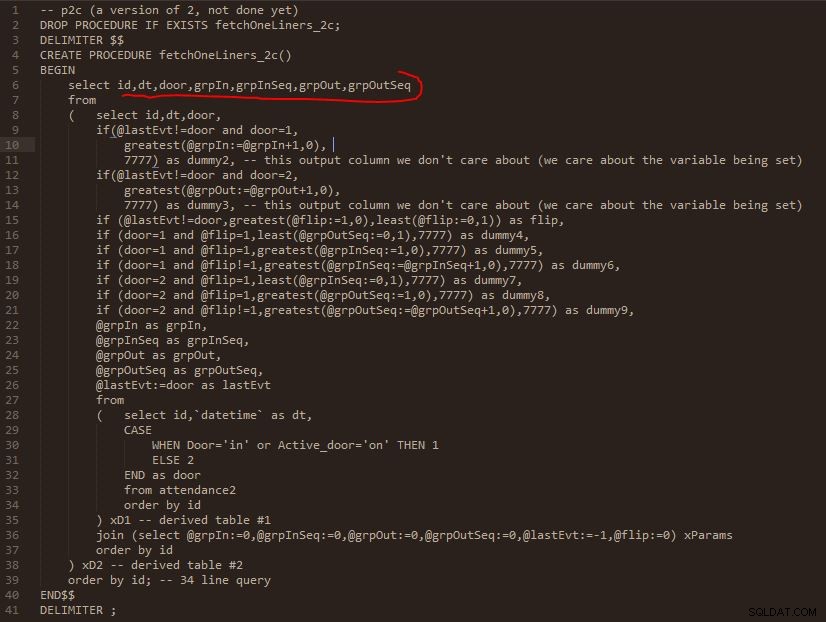
चरण C आउटपुट