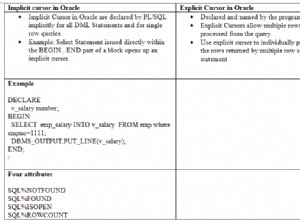
आरंभ करने के लिए, आइए हम आपकी तालिका में प्रति घंटा प्रविष्टियों की संख्या को संक्षेप में प्रस्तुत करें।
SELECT CAST(DATE_FORMAT(entry_time,'%Y-%m-%d %k:00:00') AS DATETIME) hour,
COUNT(*) samplecount
FROM table
GROUP BY CAST(DATE_FORMAT(entry_time,'%Y-%m-%d %k:00:00') AS DATETIME)
अब, यदि आप हर छह मिनट (एक घंटे में दस बार) कुछ लॉग करते हैं, तो आपके सभी नमूना गणना मान दस होने चाहिए। यह व्यंजक:CAST(DATE_FORMAT(entry_time,'%Y-%m-%d %k:00:00') AS DATETIME) बालों वाला दिखता है लेकिन यह आपके टाइमस्टैम्प को उस घंटे तक छोटा कर देता है जिसमें वे मिनट और सेकंड को शून्य कर देते हैं।
यह यथोचित रूप से कुशल है, और आपको आरंभ कर देगा। यदि आप अपने entry_time कॉलम पर एक इंडेक्स डाल सकते हैं और अपनी क्वेरी को कल के नमूने तक सीमित कर सकते हैं, तो यह बहुत कुशल है।
SELECT CAST(DATE_FORMAT(entry_time,'%Y-%m-%d %k:00:00') AS DATETIME) hour,
COUNT(*) samplecount
FROM table
WHERE entry_time >= CURRENT_DATE - INTERVAL 1 DAY
AND entry_time < CURRENT_DATE
GROUP BY CAST(DATE_FORMAT(entry_time,'%Y-%m-%d %k:00:00') AS DATETIME)
लेकिन लापता नमूनों के साथ पूरे घंटे का पता लगाने में यह बहुत अच्छा नहीं है। यह आपके नमूने में घबराहट के प्रति भी थोड़ा संवेदनशील है। यानी, यदि आपका टॉप-ऑफ-द-घंटे नमूना कभी-कभी आधा सेकंड जल्दी (10:59:30) और कभी-कभी आधा सेकंड देर से (11:00:30) होता है, तो आपकी प्रति घंटा सारांश गणना बंद हो जाएगी। तो, यह घंटे सारांश बात (या दिन सारांश, या मिनट सारांश, आदि) बुलेटप्रूफ नहीं है।
सामान को पूरी तरह से ठीक करने के लिए आपको एक सेल्फ-जॉइन क्वेरी की आवश्यकता है; यह हेयरबॉल का थोड़ा अधिक है और लगभग उतना कुशल नहीं है।
आइए क्रमांकित नमूनों के साथ स्वयं को इस तरह एक वर्चुअल टेबल (सबक्वायरी) बनाकर शुरू करें। (यह MySQL में एक दर्द है; कुछ अन्य महंगे DBMS इसे आसान बनाते हैं। कोई बात नहीं।)
SELECT @sample:example@sqldat.com+1 AS entry_num, c.entry_time, c.value
FROM (
SELECT entry_time, value
FROM table
ORDER BY entry_time
) C,
(SELECT @sample:=0) s
यह छोटी आभासी तालिका entry_num, entry_time, मान देती है।
अगला कदम, हम इसे खुद से जोड़ते हैं।
SELECT one.entry_num, one.entry_time, one.value,
TIMEDIFF(two.value, one.value) interval
FROM (
/* virtual table */
) ONE
JOIN (
/* same virtual table */
) TWO ON (TWO.entry_num - 1 = ONE.entry_num)
यह जॉइन के ON क्लॉज द्वारा शासित एक एकल प्रविष्टि द्वारा एक-दूसरे को ऑफसेट करने वाली अगली दो तालिकाओं को पंक्तिबद्ध करता है।
अंत में हम इस तालिका से interval . के साथ मान चुनते हैं आपकी दहलीज से बड़ा है, और नमूने के समय लापता लोगों के ठीक पहले हैं।
ओवरऑल सेल्फ जॉइन क्वेरी यह है। मैंने तुमसे कहा था कि यह एक हेयरबॉल था।
SELECT one.entry_num, one.entry_time, one.value,
TIMEDIFF(two.value, one.value) interval
FROM (
SELECT @sample:example@sqldat.com+1 AS entry_num, c.entry_time, c.value
FROM (
SELECT entry_time, value
FROM table
ORDER BY entry_time
) C,
(SELECT @sample:=0) s
) ONE
JOIN (
SELECT @sample2:example@sqldat.com+1 AS entry_num, c.entry_time, c.value
FROM (
SELECT entry_time, value
FROM table
ORDER BY entry_time
) C,
(SELECT @sample2:=0) s
) TWO ON (TWO.entry_num - 1 = ONE.entry_num)
यदि आपको इसे बड़े टेबल पर उत्पादन में करना है तो आप इसे अपने डेटा के सबसेट के लिए करना चाहेंगे। उदाहरण के लिए, आप इसे पिछले दो दिनों के नमूनों के लिए प्रत्येक दिन कर सकते हैं। यह शालीनता से कुशल होगा, और यह भी सुनिश्चित करेगा कि आपने आधी रात को किसी भी लापता नमूने की अनदेखी नहीं की। ऐसा करने के लिए आपकी छोटी पंक्तिबद्ध वर्चुअल टेबल इस तरह दिखेगी।
SELECT @sample:example@sqldat.com+1 AS entry_num, c.entry_time, c.value
FROM (
SELECT entry_time, value
FROM table
ORDER BY entry_time
WHERE entry_time >= CURRENT_DATE - INTERVAL 2 DAY
AND entry_time < CURRENT_DATE /*yesterday but not today*/
) C,
(SELECT @sample:=0) s