व्यक्तियों के नामों के साथ काम करने में, और उन पर अस्पष्ट लुकअप करने में, मेरे लिए जो काम आया, वह था शब्दों की दूसरी तालिका बनाना। एक तीसरी तालिका भी बनाएं जो टेक्स्ट वाली तालिका और शब्द तालिका के बीच कई से कई संबंधों के लिए एक प्रतिच्छेद तालिका है। जब टेक्स्ट टेबल में एक पंक्ति जोड़ी जाती है, तो आप टेक्स्ट को शब्दों में विभाजित करते हैं और जरूरत पड़ने पर शब्द तालिका में नए शब्द जोड़ते हुए, इंटरसेक्ट टेबल को उचित रूप से पॉप्युलेट करते हैं। एक बार जब यह संरचना हो जाती है, तो आप थोड़ी तेजी से लुकअप कर सकते हैं, क्योंकि आपको केवल अद्वितीय शब्दों की तालिका पर अपना डैमलेव फ़ंक्शन करने की आवश्यकता होती है। एक साधारण जुड़ाव आपको मेल खाने वाले शब्दों वाला पाठ देता है। 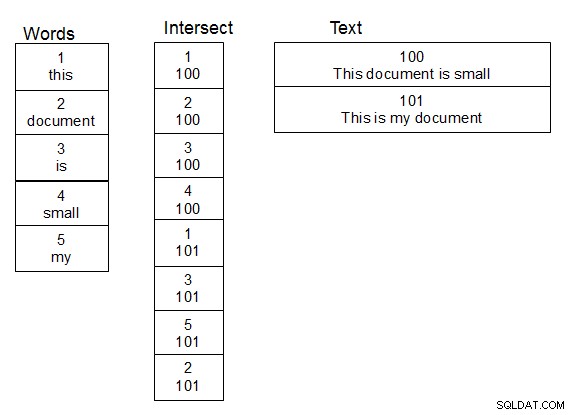
एक शब्द मिलान के लिए एक क्वेरी कुछ इस तरह दिखाई देगी:
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
और दो शब्द इस तरह दिखाई देंगे (मेरे सिर के ऊपर से, इसलिए बिल्कुल सही नहीं हो सकता है):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
कुछ डेटाबेस स्थान की कीमत पर, यहाँ लाभ यह है कि आपको केवल समय-महंगे damlev फ़ंक्शन को अद्वितीय शब्दों पर लागू करना होगा, जो संभवतः आपके टेक्स्ट की तालिका के आकार की परवाह किए बिना केवल 10 में से 10 की संख्या में होगा। यह मायने रखता है, क्योंकि डैमलेव यूडीएफ इंडेक्स का उपयोग नहीं करेगा - यह पूरी तालिका को स्कैन करेगा, जिस पर इसे हर पंक्ति के लिए एक मान की गणना करने के लिए लागू किया गया है। केवल अद्वितीय शब्दों को स्कैन करना बहुत तेज़ होना चाहिए। दूसरा लाभ यह है कि damlev शब्द स्तर पर लागू होता है, जो कि आप जो मांग रहे हैं वह प्रतीत होता है। एक और फायदा यह है कि आप कई शब्दों पर खोज का समर्थन करने के लिए क्वेरी का विस्तार कर सकते हैं, और टेक्स्ट आईडी पर मिलान करने वाली इंटरसेक्ट पंक्तियों को समूहीकृत करके और मैचों की गिनती पर रैंकिंग करके परिणामों को रैंक कर सकते हैं।