आजकल कई बादलों में फैले डेटाबेस काफी आम हैं। वे उच्च उपलब्धता और आपदा वसूली प्रक्रियाओं को आसानी से लागू करने की संभावना का वादा करते हैं। वे विक्रेता लॉक-इन से बचने का एक तरीका भी हैं:यदि आप अपने डेटाबेस वातावरण को डिज़ाइन करते हैं ताकि यह कई क्लाउड प्रदाताओं में काम कर सके, तो सबसे अधिक संभावना है कि आप एक विशेष प्रदाता के लिए विशिष्ट सुविधाओं और कार्यान्वयन से बंधे नहीं हैं। इससे आपके लिए अपने परिवेश में किसी अन्य अवसंरचना प्रदाता को जोड़ना आसान हो जाता है, चाहे वह कोई अन्य क्लाउड हो या ऑन-प्रिमाइसेस सेटअप। ऐसा लचीलापन बहुत महत्वपूर्ण है क्योंकि क्लाउड प्रदाताओं के बीच भयंकर प्रतिस्पर्धा है और एक से दूसरे में माइग्रेट करना काफी संभव हो सकता है यदि इसे खर्चों को कम करके समर्थित किया जाए।
कई डेटासेंटर में अपने बुनियादी ढांचे को फैलाना (एक ही प्रदाता से या नहीं, यह वास्तव में कोई फर्क नहीं पड़ता) हल करने के लिए गंभीर समस्याएं लाता है। कोई पूरे बुनियादी ढांचे को इस तरह से कैसे डिजाइन कर सकता है कि डेटा सुरक्षित रहे? एक बहु-क्लाउड वातावरण में काम करते समय आपको जिन चुनौतियों का सामना करना पड़ता है, उनसे कैसे निपटें? इस ब्लॉग में हम एक पर एक नज़र डालेंगे, लेकिन यकीनन सबसे गंभीर - एक विभाजित मस्तिष्क की क्षमता। इसका क्या मतलब है? आइए थोड़ा विस्तार से जानें कि स्प्लिट-ब्रेन क्या है।
“स्प्लिट-ब्रेन” क्या है?
स्प्लिट-ब्रेन एक ऐसी स्थिति है जिसमें एक ऐसा वातावरण जिसमें कई नोड्स होते हैं, नेटवर्क विभाजन से ग्रस्त होता है और कई खंडों में विभाजित हो जाता है जिनका एक दूसरे से संपर्क नहीं होता है। सबसे सरल मामला इस तरह दिखेगा:
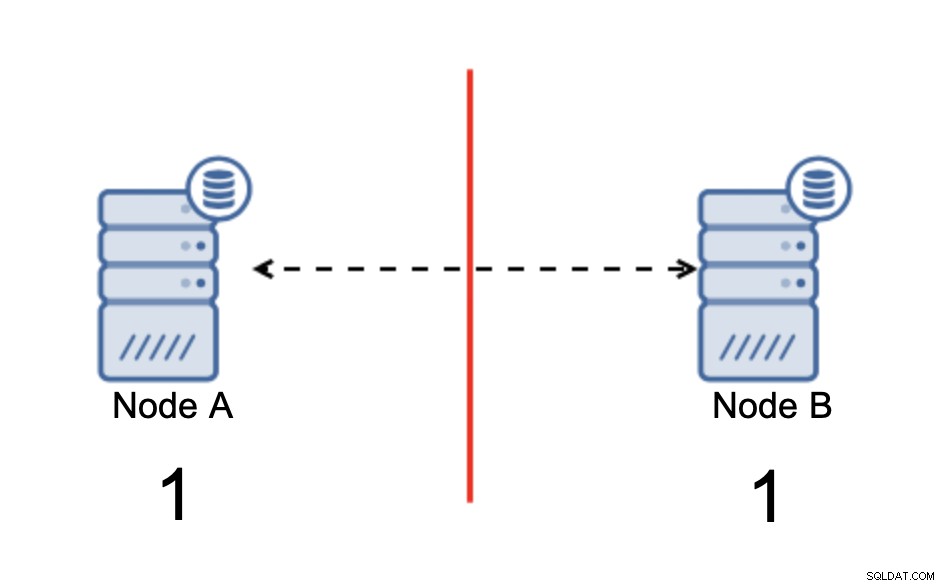
हमारे पास दो नोड, ए और बी हैं, जो द्वि का उपयोग करके एक नेटवर्क से जुड़े हैं। -दिशात्मक अतुल्यकालिक प्रतिकृति। फिर उन नोड्स के बीच नेटवर्क कनेक्शन काट दिया जाता है। नतीजतन, दोनों नोड्स एक दूसरे से कनेक्ट नहीं हो सकते हैं और नोड ए पर किए गए किसी भी परिवर्तन को नोड बी और इसके विपरीत प्रेषित नहीं किया जा सकता है। दोनों नोड्स, ए और बी, ऊपर हैं और कनेक्शन स्वीकार कर रहे हैं, वे सिर्फ डेटा का आदान-प्रदान नहीं कर सकते हैं। यह गंभीर मुद्दों को जन्म दे सकता है क्योंकि एप्लिकेशन डेटाबेस की पूर्ण स्थिति को देखने की अपेक्षा दोनों नोड्स पर परिवर्तन कर सकता है, जबकि वास्तव में, यह केवल आंशिक रूप से ज्ञात डेटा स्थिति पर संचालित होता है। परिणामस्वरूप, एप्लिकेशन द्वारा गलत कार्रवाई की जा सकती है, उपयोगकर्ता को गलत परिणाम प्रस्तुत किए जा सकते हैं और इसी तरह। हमें लगता है कि यह स्पष्ट है कि स्प्लिट-ब्रेन संभावित रूप से एक बहुत ही खतरनाक स्थिति है और प्राथमिकताओं में से एक कुछ हद तक इससे निपटना होगा। इसके बारे में क्या किया जा सकता है?
स्प्लिट-ब्रेन से कैसे बचें
संक्षेप में, यह निर्भर करता है। निपटने के लिए मुख्य मुद्दा यह है कि नोड्स ऊपर और चल रहे हैं लेकिन उनके बीच कनेक्टिविटी नहीं है इसलिए वे दूसरे नोड की स्थिति से अनजान हैं। सामान्य तौर पर, MySQL अतुल्यकालिक प्रतिकृति में किसी भी प्रकार का तंत्र नहीं होता है जो आंतरिक रूप से विभाजित-मस्तिष्क की समस्या को हल करेगा। आप कुछ समाधानों को लागू करने का प्रयास कर सकते हैं जो आपको विभाजित मस्तिष्क से बचने में मदद करते हैं लेकिन वे सीमाओं के साथ आते हैं या वे अभी भी पूरी तरह से समस्या का समाधान नहीं करते हैं।
जब हम एसिंक्रोनस प्रतिकृति से दूर हो जाते हैं, तो चीजें अलग दिख रही हैं। MySQL समूह प्रतिकृति और MySQL गैलेरा क्लस्टर ऐसी प्रौद्योगिकियां हैं जो बिल्ड-इट क्लस्टर जागरूकता से लाभान्वित होती हैं। वे दोनों समाधान नोड्स में संचार बनाए रखते हैं और यह सुनिश्चित करते हैं कि क्लस्टर नोड्स की स्थिति से अवगत है। वे एक कोरम तंत्र लागू करते हैं जो यह नियंत्रित करता है कि क्लस्टर चालू हो सकते हैं या नहीं।
आइए उन दो समाधानों (एसिंक्रोनस प्रतिकृति और कोरम-आधारित क्लस्टर) पर अधिक विस्तार से चर्चा करें।
कोरम-आधारित क्लस्टरिंग
हम MySQL Galera Cluster और MySQL Group Replication के बीच कार्यान्वयन के अंतर पर चर्चा नहीं करने जा रहे हैं, हम कोरम-आधारित दृष्टिकोण के पीछे मूल विचार पर ध्यान केंद्रित करेंगे और यह कैसे की समस्या को हल करने के लिए डिज़ाइन किया गया है। आपके क्लस्टर में विभाजित-मस्तिष्क।
लब्बोलुआब यह है कि:क्लस्टर को संचालित करने के लिए, इसके अधिकांश नोड्स उपलब्ध होने की आवश्यकता होती है। इस आवश्यकता के साथ हम यह सुनिश्चित कर सकते हैं कि अल्पसंख्यक वास्तव में शेष समूह को प्रभावित नहीं कर सकते क्योंकि अल्पसंख्यक को कोई कार्य करने में सक्षम नहीं होना चाहिए। इसका अर्थ यह भी है कि, एक नोड की विफलता को संभालने में सक्षम होने के लिए, एक क्लस्टर में कम से कम तीन नोड होने चाहिए। यदि आपके पास केवल दो नोड हैं:
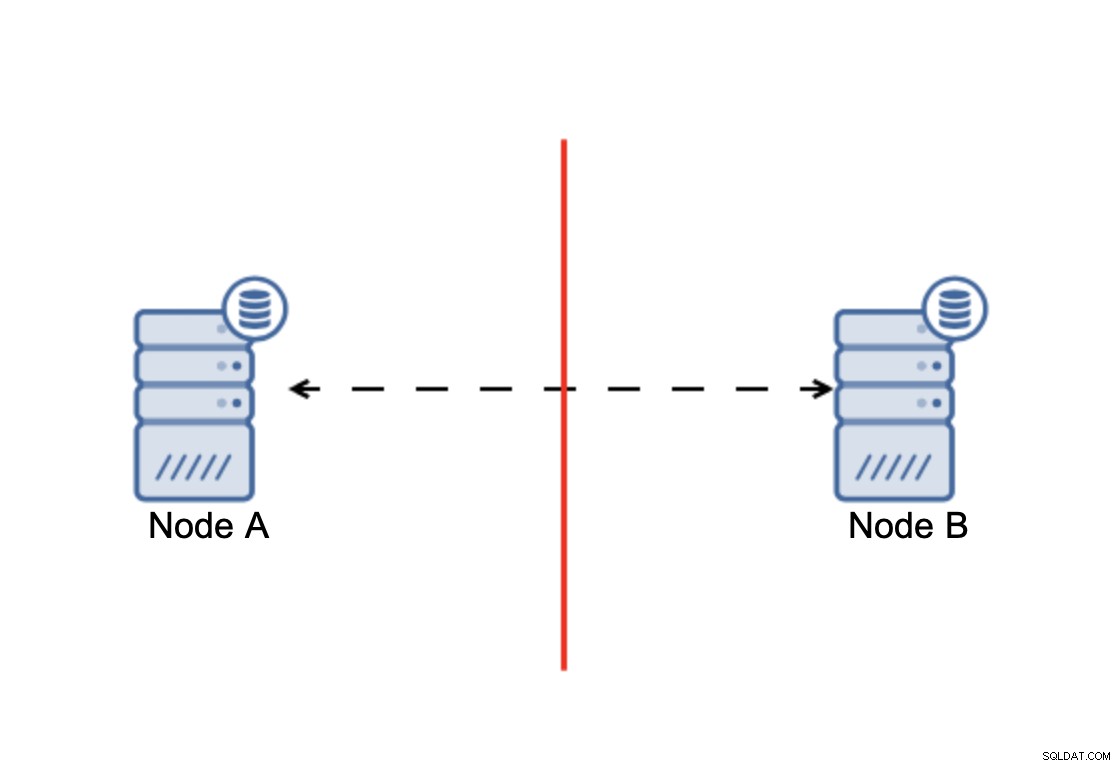
जब नेटवर्क विभाजन होता है, तो आप के दो भाग होते हैं क्लस्टर, प्रत्येक क्लस्टर में कुल नोड्स के ठीक 50% से मिलकर बनता है। इनमें से किसी भी हिस्से के पास बहुमत नहीं है। यदि आपके पास तीन नोड हैं, हालांकि, चीजें अलग हैं:
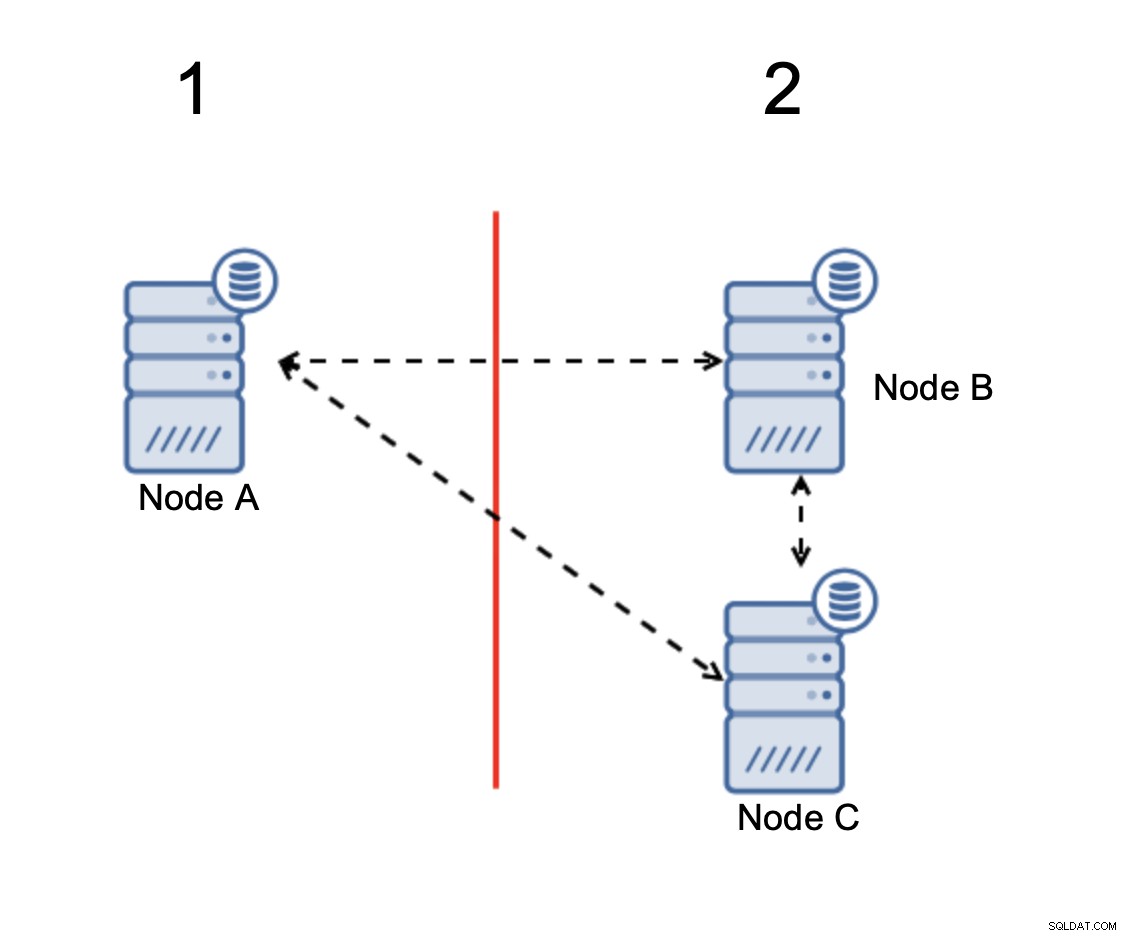
नोड्स B और C में बहुसंख्यक हैं:उस भाग में दो नोड होते हैं। तीन में से यह काम करना जारी रख सकता है। दूसरी ओर, नोड A क्लस्टर में केवल 33% नोड्स का प्रतिनिधित्व करता है, इसलिए इसमें बहुमत नहीं है और यह विभाजित मस्तिष्क से बचने के लिए ट्रैफ़िक को संभालना बंद कर देगा।
इस तरह के कार्यान्वयन के साथ, स्प्लिट-ब्रेन होने की संभावना बहुत कम है (इसे कुछ अजीब और अप्रत्याशित नेटवर्क राज्यों, दौड़ की स्थिति या क्लस्टरिंग कोड में स्पष्ट रूप से बग के माध्यम से पेश करना होगा। हालांकि मुठभेड़ करना असंभव नहीं है ऐसी स्थितियों में, कोरम-आधारित समाधानों में से किसी एक का उपयोग करना इस समय मौजूद विभाजित-मस्तिष्क से बचने का सबसे अच्छा विकल्प है।
अतुल्यकालिक प्रतिकृति
जबकि स्प्लिट-ब्रेन से निपटने के लिए आदर्श विकल्प नहीं है, एसिंक्रोनस प्रतिकृति अभी भी एक व्यवहार्य विकल्प है। एसिंक्रोनस प्रतिकृति के साथ एक बहु-क्लाउड डेटाबेस को लागू करने से पहले आपको कई बातों पर विचार करना चाहिए।
पहला, फेलओवर। अतुल्यकालिक प्रतिकृति एक लेखक के साथ आती है - केवल मास्टर को लिखने योग्य होना चाहिए और अन्य नोड्स को केवल-पढ़ने के लिए यातायात की सेवा करनी चाहिए। चुनौती यह है कि मास्टर विफलता से कैसे निपटा जाए?
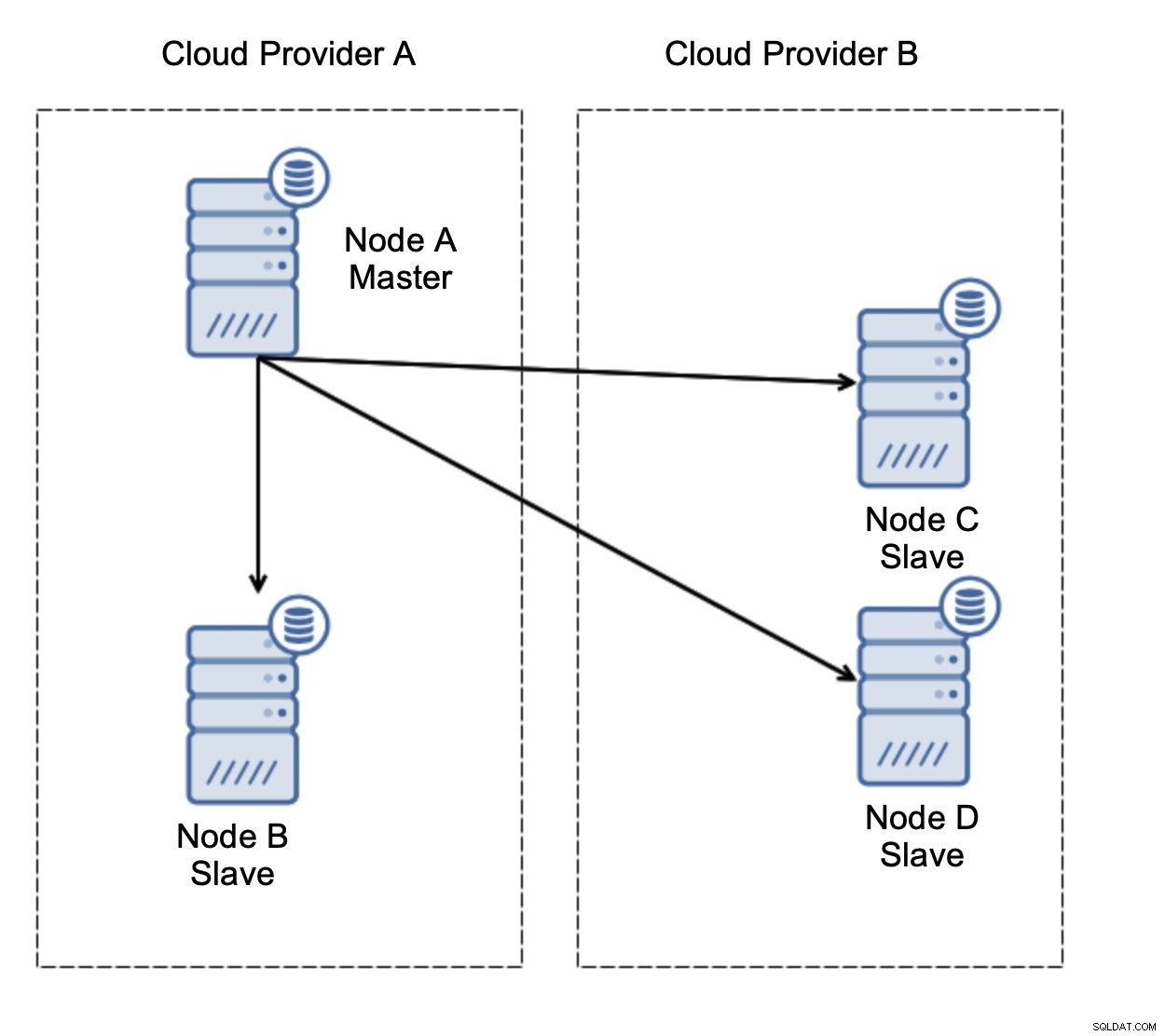
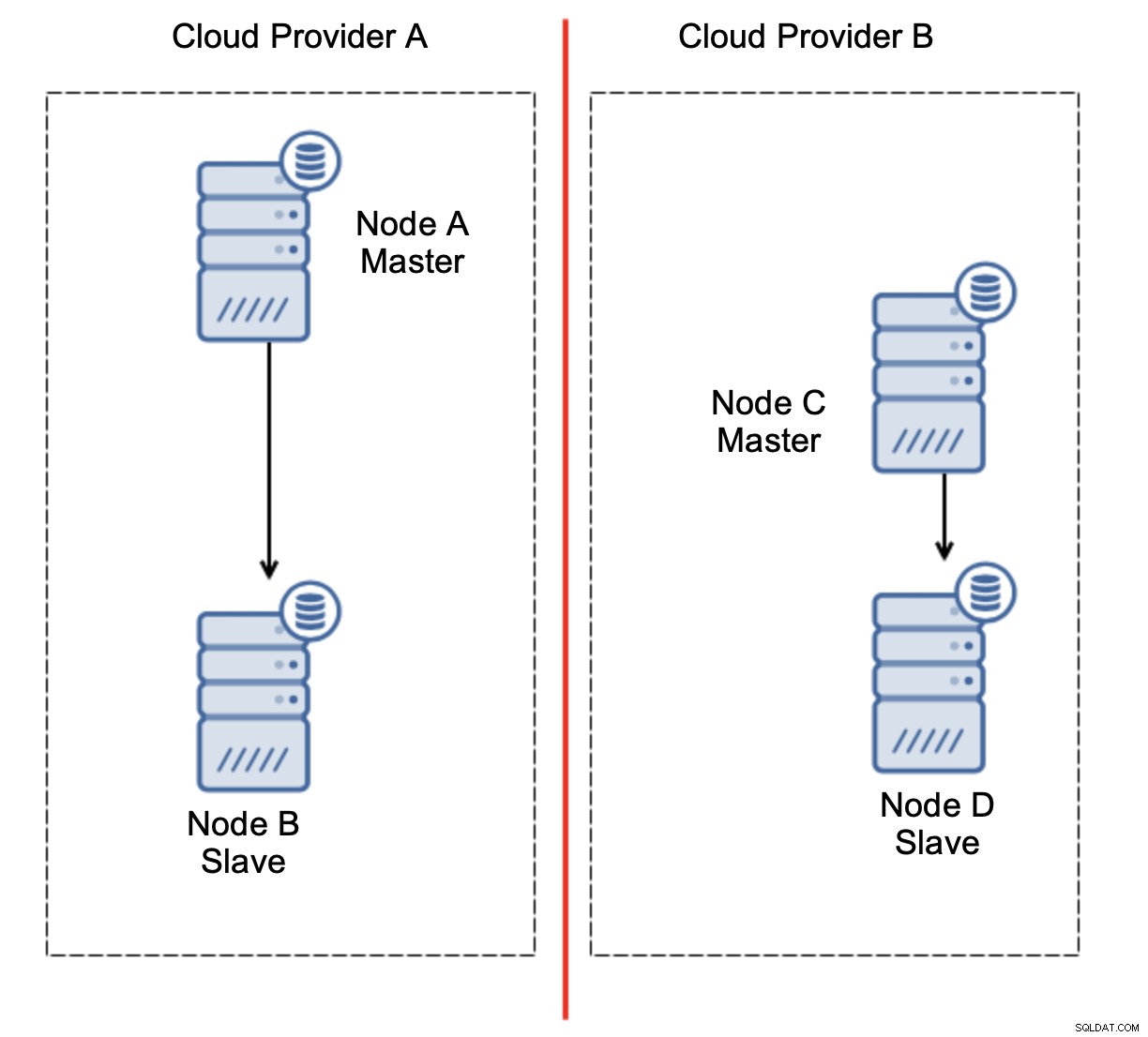
आइए ऊपर दिए गए आरेख के अनुसार सेटअप पर विचार करें। हमारे पास दो क्लाउड प्रदाता हैं, प्रत्येक में दो नोड हैं। प्रदाता ए मास्टर भी होस्ट करता है। अगर गुरु फेल हो जाए तो क्या होगा? दासों में से एक को यह सुनिश्चित करने के लिए प्रोत्साहित किया जाना चाहिए कि डेटाबेस चालू रहेगा। आदर्श रूप से, डेटाबेस को परिचालन स्थिति में लाने के लिए आवश्यक समय को कम करने के लिए यह एक स्वचालित प्रक्रिया होनी चाहिए। हालाँकि, यदि नेटवर्क विभाजन होता तो क्या होता? हम कैसे क्लस्टर की स्थिति को सत्यापित करने की उम्मीद कर रहे हैं?
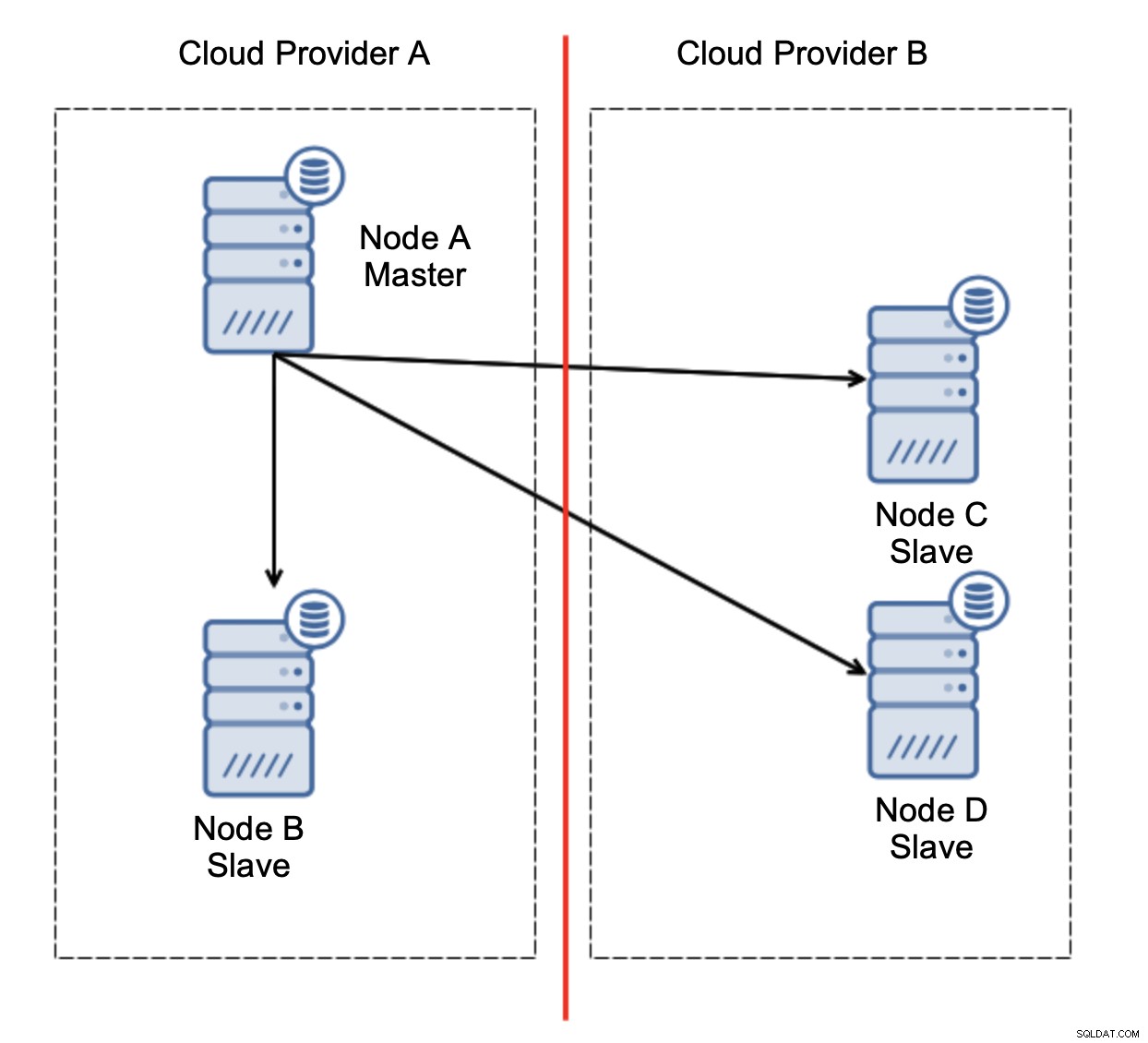
ये है चुनौती। दो क्लाउड प्रदाताओं के बीच नेटवर्क कनेक्टिविटी खो जाती है। नोड सी और डी दोनों नोड बी और मास्टर के दृष्टिकोण से, नोड ए ऑफ़लाइन हैं। क्या नोड सी या डी को मास्टर बनने के लिए पदोन्नत किया जाना चाहिए? लेकिन पुराना मास्टर अभी भी ऊपर है - यह दुर्घटनाग्रस्त नहीं हुआ, यह नेटवर्क पर उपलब्ध नहीं है। अगर हम प्रदाता बी में स्थित नोड्स में से एक को बढ़ावा देंगे, तो हम दो लिखने योग्य मास्टर्स, दो डेटा सेट और विभाजित मस्तिष्क के साथ समाप्त होंगे:
यह निश्चित रूप से ऐसा कुछ नहीं है जो हम चाहते हैं। यहां कुछ विकल्प हैं। सबसे पहले, हम फ़ेलओवर नियमों को इस तरह परिभाषित कर सकते हैं कि फ़ेलओवर केवल एक नेटवर्क सेगमेंट में हो सकता है, जहाँ मास्टर स्थित है। हमारे मामले में इसका मतलब यह होगा कि केवल नोड बी को मास्टर बनने के लिए स्वचालित रूप से पदोन्नत किया जा सकता है। इस तरह हम यह सुनिश्चित कर सकते हैं कि नोड ए डाउन होने पर स्वचालित विफलता होगी लेकिन नेटवर्क विभाजन होने पर कोई कार्रवाई नहीं की जाएगी। कुछ उपकरण जो स्वचालित विफलताओं को संभालने में आपकी सहायता कर सकते हैं (जैसे ClusterControl) श्वेत और काली सूची का समर्थन करते हैं, जिससे उपयोगकर्ता यह परिभाषित कर सकते हैं कि किन नोड्स को विफल होने के लिए एक उम्मीदवार के रूप में माना जा सकता है और जिनका उपयोग कभी भी मास्टर्स के रूप में नहीं किया जाना चाहिए।
एक अन्य विकल्प यह होगा कि किसी प्रकार के "टोपोलॉजी जागरूकता" समाधान को लागू किया जाए। उदाहरण के लिए, कोई बाहरी सेवाओं जैसे लोड बैलेंसर्स का उपयोग करके मास्टर स्थिति की जांच करने का प्रयास कर सकता है।
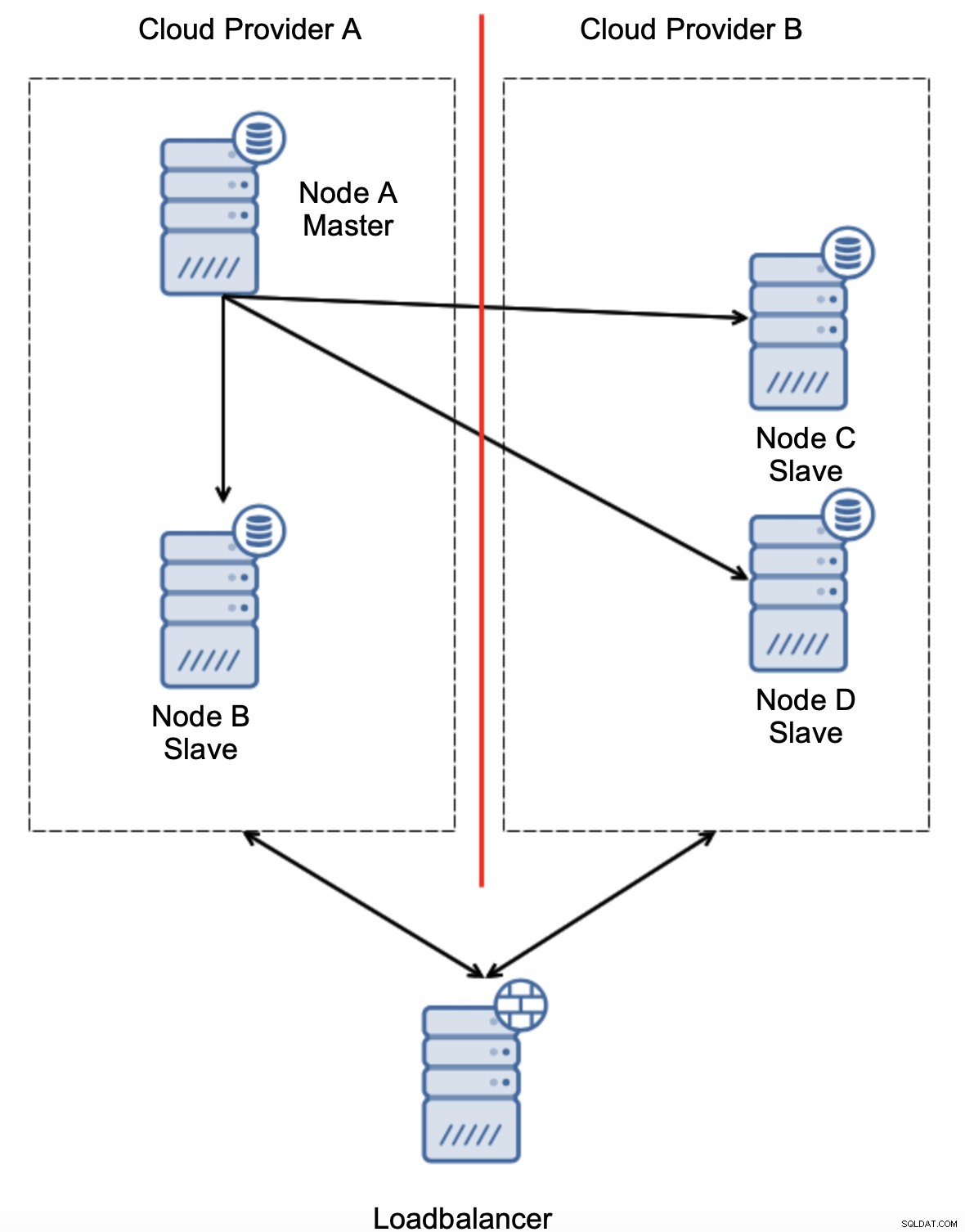
अगर फेलओवर ऑटोमेशन टोपोलॉजी की स्थिति की जांच कर सकता है, जैसा कि इसके द्वारा देखा गया है लोड बैलेंसर, हो सकता है कि लोड बैलेंसर, तीसरे स्थान पर स्थित हो, वास्तव में दोनों डेटासेंटर तक पहुंच सकता है और यह स्पष्ट कर सकता है कि क्लाउड प्रदाता ए में नोड्स डाउन नहीं हैं, उन्हें क्लाउड प्रदाता बी से नहीं पहुंचा जा सकता है। ClusterControl में जाँच की एक अतिरिक्त परत लागू की गई है।
आखिरकार, स्वचालित विफलता को लागू करने के लिए आप जो भी उपकरण का उपयोग करते हैं, उसे भी डिजाइन किया जा सकता है ताकि यह कोरम-जागरूक हो। फिर, तीन स्थानों पर तीन नोड्स के साथ, आप आसानी से बता सकते हैं कि बुनियादी ढांचे के किस हिस्से को जीवित रखा जाना चाहिए और कौन सा नहीं।
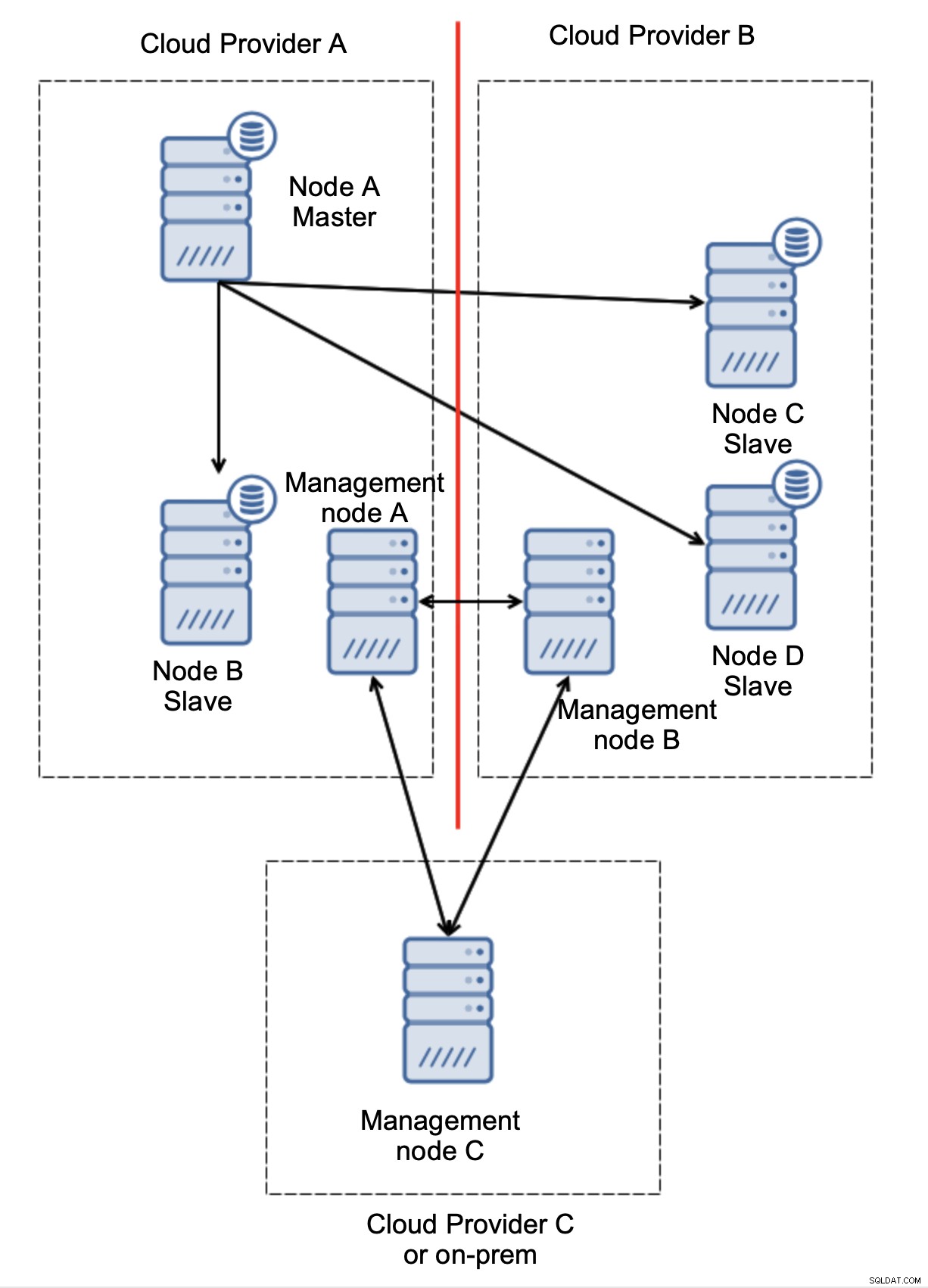
यहां, हम स्पष्ट रूप से देख सकते हैं कि समस्या केवल कनेक्टिविटी से संबंधित है प्रदाताओं ए और बी के बीच। प्रबंधन नोड सी एक रिले के रूप में कार्य करेगा और परिणामस्वरूप, कोई विफलता शुरू नहीं होनी चाहिए। दूसरी ओर, यदि एक डाटासेंटर पूरी तरह से कट जाता है:

यह भी स्पष्ट है कि क्या हुआ था। प्रबंधन नोड ए रिपोर्ट करेगा कि यह क्लस्टर के बहुमत तक नहीं पहुंच सकता है जबकि प्रबंधन नोड बी और सी बहुमत बनाएंगे। इस पर निर्माण करना संभव है और, उदाहरण के लिए, स्क्रिप्ट लिखना जो प्रबंधन नोड की स्थिति के अनुसार टोपोलॉजी का प्रबंधन करेगा। इसका मतलब यह हो सकता है कि क्लाउड प्रदाता ए में निष्पादित स्क्रिप्ट यह पता लगाएगी कि प्रबंधन नोड ए बहुमत नहीं बनाता है और वे सभी डेटाबेस नोड्स को रोक देंगे ताकि यह सुनिश्चित हो सके कि विभाजित क्लाउड प्रदाता में कोई लेखन नहीं होगा।
ClusterControl, जब उच्च उपलब्धता मोड में तैनात किया जाता है तो इसे प्रबंधन नोड के रूप में माना जा सकता है जिसका उपयोग हमने अपने उदाहरणों में किया था। RAFT प्रोटोकॉल के शीर्ष पर तीन ClusterControl नोड्स, यह निर्धारित करने में आपकी सहायता कर सकते हैं कि किसी दिए गए नेटवर्क सेगमेंट को विभाजित किया गया है या नहीं।
निष्कर्ष
हमें उम्मीद है कि यह ब्लॉग पोस्ट आपको स्प्लिट-ब्रेन परिदृश्यों के बारे में कुछ विचार देता है जो कई क्लाउड प्लेटफॉर्म पर फैले MySQL परिनियोजन के लिए हो सकता है।