पिछले कुछ ब्लॉगों में, हमने कवर किया कि डॉकर पर गैलेरा क्लस्टर कैसे चलाया जाए, चाहे वह स्टैंडअलोन डॉकर पर हो या ओवरले नेटवर्क के साथ मल्टी-होस्ट डॉकर झुंड पर। इस ब्लॉग पोस्ट में, हम कुबेरनेट्स पर गैलेरा क्लस्टर चलाने पर विचार करेंगे, जो बड़े पैमाने पर कंटेनरों को चलाने के लिए एक ऑर्केस्ट्रेशन टूल है। कुछ भाग अलग हैं, जैसे कि एप्लिकेशन को क्लस्टर से कैसे कनेक्ट होना चाहिए, कुबेरनेट्स विफलता को कैसे संभालता है और कुबेरनेट्स में लोड संतुलन कैसे काम करता है।
कुबेरनेट्स बनाम डॉकर झुंड
हमारा अंतिम लक्ष्य यह सुनिश्चित करना है कि गैलेरा क्लस्टर एक कंटेनर वातावरण में मज़बूती से चलता है। हमने पहले डॉकर झुंड को कवर किया था, और यह पता चला कि इस पर गैलेरा क्लस्टर चलाने में कई अवरोधक हैं, जो इसे उत्पादन के लिए तैयार होने से रोकते हैं। हमारी यात्रा अब कुबेरनेट्स के साथ जारी है, जो एक प्रोडक्शन-ग्रेड कंटेनर ऑर्केस्ट्रेशन टूल है। आइए देखें कि गैलेरा क्लस्टर जैसी स्टेटफुल सेवा चलाते समय यह किस स्तर की "उत्पादन-तैयारी" का समर्थन कर सकता है।
आगे बढ़ने से पहले, आइए हम कंटेनरों पर गैलेरा क्लस्टर चलाते समय कुबेरनेट्स (1.6) और डॉकर झुंड (17.03) के बीच कुछ प्रमुख अंतरों को उजागर करें:
- कुबेरनेट्स दो स्वास्थ्य जांच जांचों का समर्थन करता है - जीवंतता और तत्परता। कंटेनरों पर गैलेरा क्लस्टर चलाते समय यह महत्वपूर्ण है, क्योंकि एक जीवित गैलेरा कंटेनर का मतलब यह नहीं है कि यह सेवा के लिए तैयार है और इसे लोड बैलेंसिंग सेट (एक योजक/दाता राज्य के बारे में सोचें) में शामिल किया जाना चाहिए। डॉकर झुंड कुबेरनेट्स की जीवंतता के समान केवल एक स्वास्थ्य जांच जांच का समर्थन करता है, एक कंटेनर या तो स्वस्थ होता है और चलता रहता है या अस्वस्थ रहता है और पुनर्निर्धारित हो जाता है। विवरण के लिए यहां पढ़ें।
- कुबेरनेट्स में एक UI डैशबोर्ड है जिसे "kubectl प्रॉक्सी" के माध्यम से एक्सेस किया जा सकता है।
- डॉकर झुंड केवल राउंड-रॉबिन लोड संतुलन (प्रवेश) का समर्थन करता है, जबकि कुबेरनेट्स कम से कम कनेक्शन का उपयोग करता है।
- डॉकर झुंड बाहरी नेटवर्क पर एक सेवा प्रकाशित करने के लिए रूटिंग जाल का समर्थन करता है, जबकि कुबेरनेट्स नोडपोर्ट नामक कुछ समान का समर्थन करता है, साथ ही बाहरी लोड बैलेंसर्स (जीसीई जीएलबी/एडब्ल्यूएस ईएलबी) और बाहरी डीएनएस नाम (v1.7 के लिए)
कुबेदम का उपयोग करके कुबेरनेट्स स्थापित करना
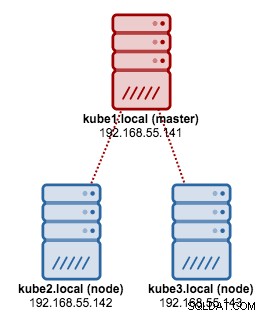
हम CentOS 7 पर 3-नोड Kubernetes क्लस्टर स्थापित करने के लिए kubeadm का उपयोग करने जा रहे हैं। इसमें 1 मास्टर और 2 नोड्स (मिनियन) होते हैं। हमारी भौतिक वास्तुकला इस तरह दिखती है:
1. सभी नोड्स पर क्यूबलेट और डॉकर स्थापित करें:
$ ARCH=x86_64
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://packages.cloud.google.com/yum/repos/kubernetes-el7-${ARCH}
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://packages.cloud.google.com/yum/doc/yum-key.gpg
https://packages.cloud.google.com/yum/doc/rpm-package-key.gpg
EOF
$ setenforce 0
$ yum install -y docker kubelet kubeadm kubectl kubernetes-cni
$ systemctl enable docker && systemctl start docker
$ systemctl enable kubelet && systemctl start kubelet2. मास्टर पर, मास्टर को इनिशियलाइज़ करें, कॉन्फ़िगरेशन फ़ाइल को कॉपी करें, वीव का उपयोग करके पॉड नेटवर्क को सेटअप करें और कुबेरनेट्स डैशबोर्ड स्थापित करें:
$ kubeadm init
$ cp /etc/kubernetes/admin.conf $HOME/
$ export KUBECONFIG=$HOME/admin.conf
$ kubectl apply -f https://git.io/weave-kube-1.6
$ kubectl create -f https://git.io/kube-dashboard3. फिर अन्य शेष नोड्स पर:
$ kubeadm join --token 091d2a.e4862a6224454fd6 192.168.55.140:64434. सत्यापित करें कि नोड तैयार हैं:
$ kubectl get nodes
NAME STATUS AGE VERSION
kube1.local Ready 1h v1.6.3
kube2.local Ready 1h v1.6.3
kube3.local Ready 1h v1.6.3अब हमारे पास गैलेरा क्लस्टर परिनियोजन के लिए कुबेरनेट्स क्लस्टर है।
कुबेरनेट्स पर गैलेरा क्लस्टर
इस उदाहरण में, हम अपने DockerHub रिपॉजिटरी से खींची गई Docker इमेज का उपयोग करके एक MariaDB Galera क्लस्टर 10.1 को तैनात करने जा रहे हैं। इस परिनियोजन में उपयोग की जाने वाली YAML परिभाषा फ़ाइलें जीथब रिपॉजिटरी में उदाहरण-कुबेरनेट्स निर्देशिका के अंतर्गत पाई जा सकती हैं।
Kubernetes कई परिनियोजन नियंत्रकों का समर्थन करता है। गैलेरा क्लस्टर को परिनियोजित करने के लिए, कोई इसका उपयोग कर सकता है:
- प्रतिकृति सेट
- स्टेटफुलसेट
उनमें से प्रत्येक के अपने पेशेवरों और विपक्ष हैं। हम उनमें से प्रत्येक पर गौर करेंगे और देखेंगे कि क्या अंतर है।
आवश्यकताएं
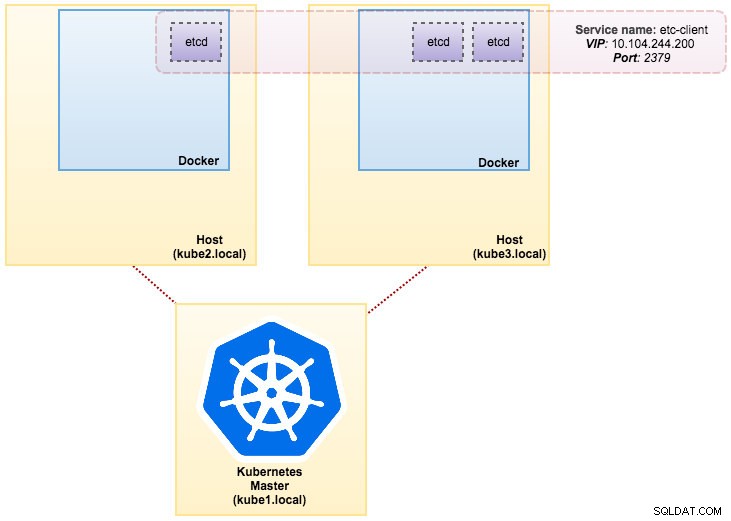
हमारे द्वारा बनाई गई छवि को सेवा खोज के लिए एक आदि (स्टैंडअलोन या क्लस्टर) की आवश्यकता होती है। एक etcd क्लस्टर चलाने के लिए प्रत्येक etcd इंस्टेंस को अलग-अलग कमांड के साथ चलाने की आवश्यकता होती है, इसलिए हम डिप्लॉयमेंट के बजाय पॉड्स कंट्रोलर का उपयोग करने जा रहे हैं और "etcd-client" नामक एक सर्विस को etcd पॉड्स के एंडपॉइंट के रूप में बनाते हैं। etcd-cluster.yaml परिभाषा फ़ाइल यह सब बताती है।
3-पॉड वगैरह क्लस्टर को परिनियोजित करने के लिए, बस चलाएँ:
$ kubectl create -f etcd-cluster.yamlसत्यापित करें कि क्या वगैरह क्लस्टर तैयार है:
$ kubectl get po,svc
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1dहमारा आर्किटेक्चर अब कुछ इस तरह दिख रहा है:
 डॉकर पर कई MySQL:अपने डेटाबेस को कंटेनरीकृत कैसे करें, इस पर MySQL सेवा चलाने के बारे में विचार करते समय आपको जो कुछ भी समझने की आवश्यकता है उसे खोजें डॉकर कंटेनर वर्चुअलाइजेशन का शीर्ष श्वेत पत्र डाउनलोड करें
डॉकर पर कई MySQL:अपने डेटाबेस को कंटेनरीकृत कैसे करें, इस पर MySQL सेवा चलाने के बारे में विचार करते समय आपको जो कुछ भी समझने की आवश्यकता है उसे खोजें डॉकर कंटेनर वर्चुअलाइजेशन का शीर्ष श्वेत पत्र डाउनलोड करें रेप्लिकासेट का उपयोग करना
एक रेप्लिकासेट यह सुनिश्चित करता है कि किसी भी समय पॉड "प्रतिकृति" की एक निर्दिष्ट संख्या चल रही हो। हालाँकि, एक परिनियोजन एक उच्च-स्तरीय अवधारणा है जो रेप्लिकासेट्स का प्रबंधन करती है और कई अन्य उपयोगी सुविधाओं के साथ पॉड्स को घोषणात्मक अपडेट प्रदान करती है। इसलिए, जब तक आपको कस्टम अपडेट ऑर्केस्ट्रेशन की आवश्यकता न हो या आपको अपडेट की आवश्यकता न हो, तब तक सीधे रेप्लिकासेट्स का उपयोग करने के बजाय परिनियोजन का उपयोग करने की अनुशंसा की जाती है। जब आप परिनियोजन का उपयोग करते हैं, तो आपको उनके द्वारा बनाए गए रेप्लिकासेट के प्रबंधन के बारे में चिंता करने की आवश्यकता नहीं है। डिप्लॉयमेंट अपने रेप्लिकासेट्स के मालिक हैं और उनका प्रबंधन करते हैं।
हमारे मामले में, हम कार्यभार नियंत्रक के रूप में परिनियोजन का उपयोग करने जा रहे हैं, जैसा कि इस YAML परिभाषा में दिखाया गया है। हम निम्नलिखित कमांड चलाकर सीधे गैलेरा क्लस्टर रेप्लिकासेट और सर्विस बना सकते हैं:
$ kubectl create -f mariadb-rs.ymlरेप्लिकासेट (आरएस), पॉड्स (पीओ) और सेवाओं (एसवीसी) को देखकर पुष्टि करें कि क्लस्टर तैयार है या नहीं:
$ kubectl get rs,po,svc
NAME DESIRED CURRENT READY AGE
rs/galera-251551564 3 3 3 5h
NAME READY STATUS RESTARTS AGE
po/etcd0 1/1 Running 0 1d
po/etcd1 1/1 Running 0 1d
po/etcd2 1/1 Running 0 1d
po/galera-251551564-8c238 1/1 Running 0 5h
po/galera-251551564-swjjl 1/1 Running 1 5h
po/galera-251551564-z4sgx 1/1 Running 1 5h
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE
svc/etcd-client 10.104.244.200 <none> 2379/TCP 1d
svc/etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d
svc/etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d
svc/etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d
svc/galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 5h
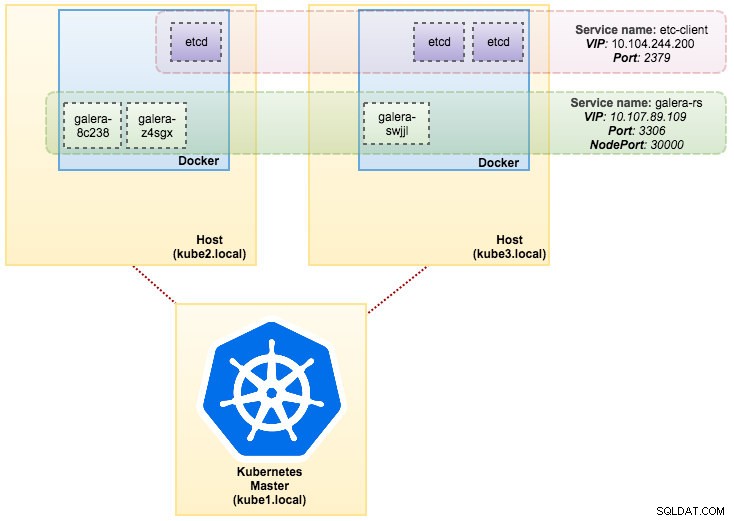
svc/kubernetes 10.96.0.1 <none> 443/TCP 1dऊपर दिए गए आउटपुट से, हम अपने पॉड्स और सर्विस को नीचे दर्शा सकते हैं:
रेप्लिकासेट पर गैलेरा क्लस्टर चलाना एक स्टेटलेस एप्लिकेशन के रूप में व्यवहार करने के समान है। यह पॉड निर्माण, विलोपन और अद्यतनों को व्यवस्थित करता है और क्षैतिज पॉड ऑटोस्केल्स (एचपीए) के लिए लक्षित किया जा सकता है, यानी एक प्रतिकृति सेट को ऑटो-स्केल किया जा सकता है यदि यह कुछ थ्रेसहोल्ड या लक्ष्य (सीपीयू उपयोग, पैकेट-प्रति-सेकंड, अनुरोध-प्रति-सेकंड) को पूरा करता है। आदि)।
यदि कुबेरनेट्स नोड्स में से एक नीचे चला जाता है, तो वांछित प्रतिकृतियों को पूरा करने के लिए उपलब्ध नोड पर नए पॉड्स शेड्यूल किए जाएंगे। यदि पॉड को हटा दिया जाता है या फिर से शेड्यूल किया जाता है, तो पॉड से जुड़े वॉल्यूम हटा दिए जाएंगे। पॉड होस्टनाम बेतरतीब ढंग से उत्पन्न होगा, जिससे यह ट्रैक करना कठिन हो जाता है कि कंटेनर कहाँ से संबंधित है, केवल होस्टनाम को देखकर।
यह सब परीक्षण और स्टेजिंग वातावरण में बहुत अच्छी तरह से काम करता है, जहां आप बिना किसी निर्भरता के एक पूर्ण कंटेनर जीवनचक्र जैसे तैनाती, स्केल, अपडेट और नष्ट कर सकते हैं। YAML फ़ाइल को अपडेट करके और इसे Kubernetes क्लस्टर में पोस्ट करके या स्केल कमांड का उपयोग करके ऊपर और नीचे स्केलिंग करना आसान है:
$ kubectl scale replicaset galera-rs --replicas=5स्टेटफुलसेट का उपयोग करना
1.6 पूर्व संस्करण पर पेटसेट के रूप में जाना जाता है, स्टेटफुलसेट उत्पादन में गैलेरा क्लस्टर को तैनात करने का सबसे अच्छा तरीका है, क्योंकि:
- स्टेटफुलसेट को हटाने और/या स्केलिंग करने से स्टेटफुलसेट से जुड़े वॉल्यूम नहीं हटेंगे। यह डेटा सुरक्षा सुनिश्चित करने के लिए किया जाता है, जो आम तौर पर सभी संबंधित स्टेटफुलसेट संसाधनों के स्वत:शुद्धिकरण से अधिक मूल्यवान होता है।
- एन प्रतिकृतियों के साथ स्टेटफुलसेट के लिए, जब पॉड्स तैनात किए जा रहे होते हैं, तो उन्हें क्रमिक रूप से {0 .. N-1 के क्रम में बनाया जाता है। }.
- जब पॉड्स हटाए जा रहे हैं, तो उन्हें {N-1 से उल्टे क्रम में समाप्त कर दिया जाता है .. 0}.
- पॉड पर स्केलिंग ऑपरेशन लागू करने से पहले, उसके सभी पूर्ववर्ती चालू और तैयार होने चाहिए।
- पॉड के समाप्त होने से पहले, उसके सभी उत्तराधिकारियों को पूरी तरह से बंद कर देना चाहिए।
स्टेटफुलसेट स्टेटफुल कंटेनरों के लिए प्रथम श्रेणी का समर्थन प्रदान करता है। यह एक परिनियोजन और स्केलिंग गारंटी प्रदान करता है। जब तीन-नोड गैलेरा क्लस्टर बनाया जाता है, तो तीन पॉड्स को db-0, db-1, db-2 क्रम में तैनात किया जाएगा। db-1 को db-0 के "रनिंग एंड रेडी" से पहले तैनात नहीं किया जाएगा, और db-2 को तब तक तैनात नहीं किया जाएगा जब तक कि db-1 "रनिंग एंड रेडी" न हो जाए। यदि db-0 विफल होना चाहिए, db-1 के बाद "रनिंग एंड रेडी" है, लेकिन db-2 लॉन्च होने से पहले, db-2 तब तक लॉन्च नहीं होगा जब तक कि db-0 सफलतापूर्वक पुन:लॉन्च नहीं हो जाता और "रनिंग एंड रेडी" नहीं हो जाता।
हम PersistentVolume और PersistentVolumeClaim नामक लगातार स्टोरेज के Kubernetes कार्यान्वयन का उपयोग करने जा रहे हैं। यह डेटा निरंतरता सुनिश्चित करने के लिए है यदि पॉड को दूसरे नोड में पुनर्निर्धारित किया गया है। भले ही गैलेरा क्लस्टर प्रत्येक प्रतिकृति पर डेटा की सटीक प्रतिलिपि प्रदान करता है, फिर भी प्रत्येक पॉड में डेटा का स्थिर रहना समस्या निवारण और पुनर्प्राप्ति उद्देश्यों के लिए अच्छा है।
एक स्थायी भंडारण बनाने के लिए, पहले हमें प्रत्येक पॉड के लिए PersistentVolume बनाना होगा। पीवी वॉल्यूम प्लगइन्स हैं जैसे डॉकर में वॉल्यूम, लेकिन किसी भी व्यक्तिगत पॉड से स्वतंत्र जीवनचक्र होता है जो पीवी का उपयोग करता है। चूंकि हम 3-नोड गैलेरा क्लस्टर को तैनात करने जा रहे हैं, इसलिए हमें 3 पीवी बनाने की जरूरत है:
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-0
labels:
app: galera-ss
podindex: "0"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-0/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-1
labels:
app: galera-ss
podindex: "1"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-1/datadir
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: datadir-galera-2
labels:
app: galera-ss
podindex: "2"
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 10Gi
hostPath:
path: /data/pods/galera-2/datadirउपरोक्त परिभाषा से पता चलता है कि हम 3 पीवी बनाने जा रहे हैं, जिसे कुबेरनेट्स नोड्स के भौतिक पथ में 10GB स्टोरेज स्पेस के साथ मैप किया गया है। हमने ReadWriteOnce को परिभाषित किया है, जिसका अर्थ है कि वॉल्यूम को केवल एक नोड द्वारा रीड-राइट के रूप में माउंट किया जा सकता है। उपरोक्त पंक्तियों को mariadb-pv.yml में सहेजें और इसे Kubernetes पर पोस्ट करें:
$ kubectl create -f mariadb-pv.yml
persistentvolume "datadir-galera-0" created
persistentvolume "datadir-galera-1" created
persistentvolume "datadir-galera-2" createdइसके बाद, PersistentVolumeClaim संसाधनों को परिभाषित करें:
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-0
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "0"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-1
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "1"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: mysql-datadir-galera-ss-2
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
selector:
matchLabels:
app: galera-ss
podindex: "2"उपरोक्त परिभाषा से पता चलता है कि हम पीवी संसाधनों का दावा करना चाहते हैं और spec.selector.matchLabels का उपयोग करना चाहते हैं हमारे पीवी को देखने के लिए (metadata.labels.app:galera-ss ) संबंधित पॉड इंडेक्स पर आधारित (metadata.labels.podindex ) कुबेरनेट्स द्वारा सौंपा गया। metadata.name संसाधन को spec.templates.containers के अंतर्गत परिभाषित प्रारूप “{volumeMounts.name}-{pod}-{ordinal index}” का उपयोग करना चाहिए इसलिए कुबेरनेट्स जानता है कि पॉड में दावे को मैप करने के लिए कौन सा माउंट पॉइंट है।
उपरोक्त पंक्तियों को mariadb-pvc.yml में सहेजें और इसे Kubernetes पर पोस्ट करें:
$ kubectl create -f mariadb-pvc.yml
persistentvolumeclaim "mysql-datadir-galera-ss-0" created
persistentvolumeclaim "mysql-datadir-galera-ss-1" created
persistentvolumeclaim "mysql-datadir-galera-ss-2" createdहमारा लगातार भंडारण अब तैयार है। फिर हम mariadb-ss.yml में दिखाए गए अनुसार हेडलेस सेवा संसाधन के साथ स्टेटफुलसेट संसाधन बनाकर गैलेरा क्लस्टर परिनियोजन शुरू कर सकते हैं:
$ kubectl create -f mariadb-ss.yml
service "galera-ss" created
statefulset "galera-ss" createdअब, हमारे स्टेटफुलसेट परिनियोजन का सारांश प्राप्त करें:
$ kubectl get statefulsets,po,pv,pvc -o wide
NAME DESIRED CURRENT AGE
statefulsets/galera-ss 3 3 1d galera severalnines/mariadb:10.1 app=galera-ss
NAME READY STATUS RESTARTS AGE IP NODE
po/etcd0 1/1 Running 0 7d 10.36.0.1 kube3.local
po/etcd1 1/1 Running 0 7d 10.44.0.2 kube2.local
po/etcd2 1/1 Running 0 7d 10.36.0.2 kube3.local
po/galera-ss-0 1/1 Running 0 1d 10.44.0.4 kube2.local
po/galera-ss-1 1/1 Running 1 1d 10.36.0.5 kube3.local
po/galera-ss-2 1/1 Running 0 1d 10.44.0.5 kube2.local
NAME CAPACITY ACCESSMODES RECLAIMPOLICY STATUS CLAIM STORAGECLASS REASON AGE
pv/datadir-galera-0 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-0 4d
pv/datadir-galera-1 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-1 4d
pv/datadir-galera-2 10Gi RWO Retain Bound default/mysql-datadir-galera-ss-2 4d
NAME STATUS VOLUME CAPACITY ACCESSMODES STORAGECLASS AGE
pvc/mysql-datadir-galera-ss-0 Bound datadir-galera-0 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-1 Bound datadir-galera-1 10Gi RWO 4d
pvc/mysql-datadir-galera-ss-2 Bound datadir-galera-2 10Gi RWO 4dइस बिंदु पर, स्टेटफुलसेट पर चल रहे हमारे गैलेरा क्लस्टर को निम्न आरेख में दिखाया जा सकता है:
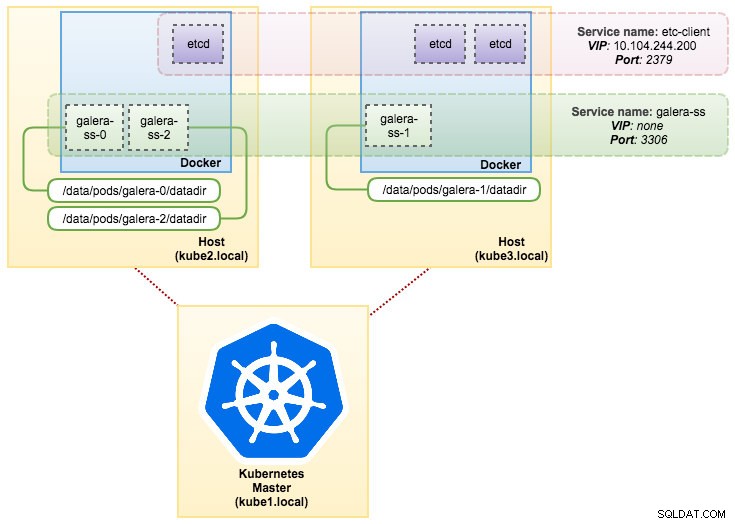
स्टेटफुलसेट पर चलने से लगातार पहचानकर्ता जैसे होस्टनाम, आईपी एड्रेस, नेटवर्क आईडी, क्लस्टर डोमेन, पॉड डीएनएस और स्टोरेज की गारंटी मिलती है। यह पॉड को पॉड्स के समूह में दूसरों से आसानी से अलग करने की अनुमति देता है। वॉल्यूम को होस्ट पर बरकरार रखा जाएगा और अगर पॉड को हटा दिया जाता है या किसी अन्य नोड पर फिर से शेड्यूल किया जाता है तो यह डिलीट नहीं होगा। यह डेटा पुनर्प्राप्ति की अनुमति देता है और कुल डेटा हानि के जोखिम को कम करता है।
नकारात्मक पक्ष पर, परिनियोजन समय N-1 होगा समय (एन =प्रतिकृतियां) लंबे समय तक क्योंकि कुबेरनेट्स संसाधनों को तैनात, पुनर्निर्धारण या हटाते समय क्रमिक अनुक्रम का पालन करेंगे। अपने क्लस्टर को बढ़ाने के बारे में सोचने से पहले पीवी और दावों को तैयार करने में थोड़ी परेशानी होगी। ध्यान दें कि मौजूदा स्टेटफुलसेट को अपडेट करना वर्तमान में एक मैन्युअल प्रक्रिया है, जहां आप केवल spec.replicas अपडेट कर सकते हैं। इस समय।
गैलेरा क्लस्टर सेवा और पॉड्स से कनेक्ट करना
डेटाबेस क्लस्टर से कनेक्ट करने के कुछ तरीके हैं। आप सीधे पोर्ट से जुड़ सकते हैं। "गैलेरा-आरएस" सेवा उदाहरण में, हम नोडपोर्ट का उपयोग करते हैं, एक स्थिर बंदरगाह (नोडपोर्ट) पर प्रत्येक नोड के आईपी पर सेवा को उजागर करते हैं। एक ClusterIP सेवा, जिस पर NodePort सेवा रूट करेगी, स्वचालित रूप से बन जाती है। आप {NodeIP}:{NodePort} का अनुरोध करके, क्लस्टर के बाहर से, NodePort सेवा से संपर्क करने में सक्षम होंगे। ।
गैलेरा क्लस्टर से बाहरी रूप से जुड़ने का उदाहरण:
(external)$ mysql -udb_user -ppassword -h192.168.55.141 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.142 -P30000
(external)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000कुबेरनेट्स नेटवर्क स्पेस के भीतर, पॉड्स क्लस्टर आईपी या सेवा नाम के माध्यम से आंतरिक रूप से जुड़ सकते हैं जो निम्न कमांड का उपयोग करके पुनर्प्राप्त करने योग्य है:
$ kubectl get services -o wide
NAME CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
etcd-client 10.104.244.200 <none> 2379/TCP 1d app=etcd
etcd0 10.100.24.171 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd0
etcd1 10.108.207.7 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd1
etcd2 10.101.9.115 <none> 2379/TCP,2380/TCP 1d etcd_node=etcd2
galera-rs 10.107.89.109 <nodes> 3306:30000/TCP 4h app=galera-rs
galera-ss None <none> 3306/TCP 3m app=galera-ss
kubernetes 10.96.0.1 <none> 443/TCP 1d <none>सेवा सूची से, हम देख सकते हैं कि गैलेरा क्लस्टर रेप्लिकासेट क्लस्टर-आईपी 10.107.89.109 है। आंतरिक रूप से, एक अन्य पॉड एक्सपोज़्ड पोर्ट, 3306:
का उपयोग करके इस आईपी पते या सेवा नाम के माध्यम से डेटाबेस तक पहुंच सकता है।(etcd0 pod)$ mysql -udb_user -ppassword -hgalera-rs -P3306 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+आप पोर्ट 30000 पर किसी भी पॉड के अंदर से बाहरी नोडपोर्ट से भी जुड़ सकते हैं:
(etcd0 pod)$ mysql -udb_user -ppassword -h192.168.55.143 -P30000 -e 'select @@hostname'
+------------------------+
| @@hostname |
+------------------------+
| galera-251551564-z4sgx |
+------------------------+बैकएंड पॉड्स से कनेक्शन कम से कम कनेक्शन एल्गोरिथम के आधार पर संतुलित लोड किया जाएगा।
सारांश
इस समय, उत्पादन में कुबेरनेट्स पर गैलेरा क्लस्टर चलाना डॉकर झुंड की तुलना में बहुत अधिक आशाजनक लगता है। जैसा कि पिछले ब्लॉग पोस्ट में चर्चा की गई थी, जिस तरह से कुबेरनेट्स स्टेटफुलसेट में कंटेनरों को ऑर्केस्ट्रेट करता है, (हालांकि यह अभी भी v1.6 में एक बीटा फीचर है) के साथ उठाई गई चिंताओं को अलग तरह से निपटाया जाता है। हम आशा करते हैं कि सुझाए गए दृष्टिकोण से गैलेरा क्लस्टर को बड़े पैमाने पर उत्पादन में कंटेनरों पर चलाने में मदद मिलेगी।