कई उपभोक्ता उत्पादों जैसे ई-कॉमर्स, भुगतान प्रणाली, गेमिंग, परिवहन ऐप आदि में प्रदर्शन अत्यंत महत्वपूर्ण है। हालांकि आधुनिक दुनिया में डेटाबेस को उनकी प्रदर्शन आवश्यकताओं को पूरा करने के लिए कई तंत्रों के माध्यम से आंतरिक रूप से अनुकूलित किया जाता है, बहुत कुछ एप्लिकेशन डेवलपर पर भी निर्भर करता है - आखिरकार, केवल एक डेवलपर ही जानता है कि एप्लिकेशन को कौन से प्रश्न करने हैं।
रिलेशनल डेटाबेस से निपटने वाले डेवलपर्स ने इंडेक्सिंग के बारे में उपयोग किया है या कम से कम सुना है, और यह डेटाबेस की दुनिया में एक बहुत ही सामान्य अवधारणा है। हालांकि, सबसे महत्वपूर्ण हिस्सा यह समझना है कि क्या इंडेक्स करना है और कैसे इंडेक्सिंग क्वेरी प्रतिक्रिया समय को बढ़ावा देने वाला है। ऐसा करने के लिए आपको यह समझने की जरूरत है कि आप अपने डेटाबेस टेबल को कैसे क्वेरी करने जा रहे हैं। एक उचित इंडेक्स तभी बनाया जा सकता है जब आपको पता हो कि आपकी क्वेरी और डेटा एक्सेस पैटर्न कैसा दिखता है।
सरल शब्दावली में, एक इंडेक्स विभिन्न इन-मेमोरी और ऑन-डिस्क डेटा संरचनाओं का उपयोग करके डिस्क पर संबंधित डेटा के लिए खोज कुंजी को मैप करता है। खोजे जाने वाले अभिलेखों की संख्या को कम करके खोज को तेज करने के लिए अनुक्रमणिका का उपयोग किया जाता है।
अधिकतर एक इंडेक्स WHERE . में निर्दिष्ट कॉलम पर बनाया जाता है डेटाबेस के रूप में एक क्वेरी का खंड उन स्तंभों के आधार पर तालिकाओं से डेटा पुनर्प्राप्त और फ़िल्टर करता है। यदि आप एक इंडेक्स नहीं बनाते हैं, तो डेटाबेस सभी पंक्तियों को स्कैन करता है, मेल खाने वाली पंक्तियों को फ़िल्टर करता है और परिणाम देता है। लाखों रिकॉर्ड के साथ, इस स्कैन ऑपरेशन में कई सेकंड लग सकते हैं और यह उच्च प्रतिक्रिया समय एपीआई और एप्लिकेशन को धीमा और अनुपयोगी बनाता है। आइए एक उदाहरण देखें —
हम एक डिफ़ॉल्ट InnoDB डेटाबेस इंजन के साथ MySQL का उपयोग करेंगे, हालांकि इस आलेख में वर्णित अवधारणाएं अन्य डेटाबेस सर्वरों के साथ-साथ Oracle, MSSQL आदि में भी कमोबेश समान हैं।
index_demo . नाम की एक टेबल बनाएं निम्न स्कीमा के साथ:
CREATE TABLE index_demo (
name VARCHAR(20) NOT NULL,
age INT,
pan_no VARCHAR(20),
phone_no VARCHAR(20)
);हम कैसे सत्यापित करते हैं कि हम InnoDB इंजन का उपयोग कर रहे हैं?
निम्न आदेश चलाएँ:
SHOW TABLE STATUS WHERE name = 'index_demo' \G;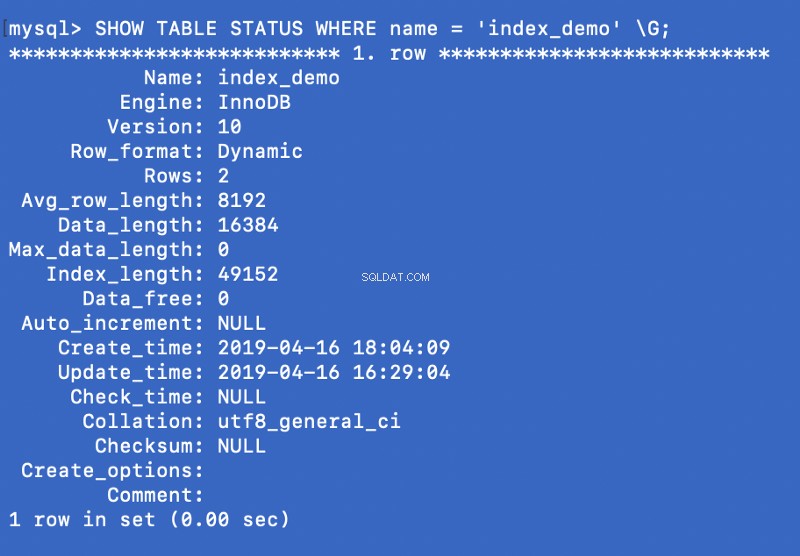
Engine उपरोक्त स्क्रीन शॉट में कॉलम उस इंजन का प्रतिनिधित्व करता है जिसका उपयोग तालिका बनाने के लिए किया जाता है। यहां InnoDB उपयोग किया जाता है।
अब तालिका में कुछ यादृच्छिक डेटा डालें, 5 पंक्तियों वाली मेरी तालिका निम्न की तरह दिखती है:
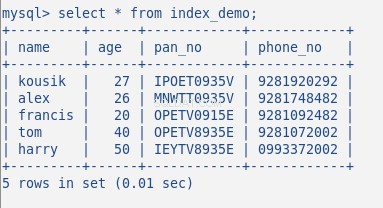
मैंने इस टेबल पर अब तक कोई इंडेक्स नहीं बनाया है। आइए इसे कमांड द्वारा सत्यापित करें:SHOW INDEX . यह 0 परिणाम देता है।

इस समय, यदि हम एक साधारण SELECT चलाते हैं क्वेरी, चूंकि कोई उपयोगकर्ता परिभाषित अनुक्रमणिका नहीं है, परिणाम जानने के लिए क्वेरी पूरी तालिका को स्कैन करेगी:
EXPLAIN SELECT * FROM index_demo WHERE name = 'alex';
EXPLAIN दिखाता है कि क्वेरी इंजन क्वेरी को निष्पादित करने की योजना कैसे बनाता है। ऊपर दिए गए स्क्रीनशॉट में, आप देख सकते हैं कि rows कॉलम रिटर्न 5 &possible_keys रिटर्न null . possible_keys प्रतिनिधित्व करता है कि सभी उपलब्ध सूचकांक क्या हैं जिनका उपयोग इस क्वेरी में किया जा सकता है। key कॉलम दर्शाता है कि इस क्वेरी में सभी संभावित सूचकांकों में से वास्तव में किस इंडेक्स का उपयोग किया जा रहा है।
प्राथमिक कुंजी:
उपरोक्त क्वेरी बहुत अक्षम है। आइए इस क्वेरी को ऑप्टिमाइज़ करें। हम phone_no बना देंगे कॉलम ए PRIMARY KEY यह मानते हुए कि एक ही फोन नंबर के साथ हमारे सिस्टम में कोई भी दो उपयोगकर्ता मौजूद नहीं हो सकते हैं। प्राथमिक कुंजी बनाते समय निम्नलिखित बातों का ध्यान रखें:
- प्राथमिक कुंजी आपके आवेदन में कई महत्वपूर्ण प्रश्नों का हिस्सा होनी चाहिए।
- प्राथमिक कुंजी एक बाधा है जो एक तालिका में प्रत्येक पंक्ति को विशिष्ट रूप से पहचानती है। यदि एकाधिक स्तंभ प्राथमिक कुंजी का हिस्सा हैं, तो वह संयोजन प्रत्येक पंक्ति के लिए अद्वितीय होना चाहिए।
- प्राथमिक कुंजी गैर-शून्य होनी चाहिए। कभी भी अशक्त क्षेत्रों को अपनी प्राथमिक कुंजी न बनाएं। एएनएसआई एसक्यूएल मानकों के अनुसार, प्राथमिक कुंजी एक दूसरे के साथ तुलनीय होनी चाहिए, और आपको निश्चित रूप से यह बताने में सक्षम होना चाहिए कि किसी विशेष पंक्ति के लिए प्राथमिक कुंजी कॉलम मान दूसरी पंक्ति से अधिक, छोटा या बराबर है या नहीं। चूंकि
NULLSQL मानकों में एक अपरिभाषित मान का अर्थ है, आप निश्चित रूप सेNULL. की तुलना नहीं कर सकते किसी अन्य मान के साथ, इसलिए तार्किक रूप सेNULLअनुमति नहीं है। - आदर्श प्राथमिक कुंजी प्रकार एक संख्या होनी चाहिए जैसे
INTयाBIGINTक्योंकि पूर्णांक तुलना तेज़ होती है, इसलिए अनुक्रमणिका को पार करना बहुत तेज़ होगा।
अक्सर हम एक id . परिभाषित करते हैं AUTO INCREMENT . के रूप में फ़ील्ड तालिकाओं में और इसे प्राथमिक कुंजी के रूप में उपयोग करें, लेकिन प्राथमिक कुंजी का चुनाव डेवलपर्स पर निर्भर करता है।
क्या होगा यदि आप स्वयं कोई प्राथमिक कुंजी नहीं बनाते हैं?
प्राथमिक कुंजी स्वयं बनाना अनिवार्य नहीं है। यदि आपने किसी प्राथमिक कुंजी को परिभाषित नहीं किया है, तो InnoDB परोक्ष रूप से आपके लिए एक बनाता है क्योंकि InnoDB डिज़ाइन द्वारा प्रत्येक तालिका में एक प्राथमिक कुंजी होनी चाहिए। तो एक बार जब आप उस तालिका के लिए बाद में प्राथमिक कुंजी बनाते हैं, तो InnoDB पहले से परिभाषित प्राथमिक कुंजी को हटा देता है।
चूंकि हमारे पास अभी तक कोई प्राथमिक कुंजी परिभाषित नहीं है, आइए देखें कि डिफ़ॉल्ट रूप से InnoDB ने हमारे लिए क्या बनाया है:
SHOW EXTENDED INDEX FROM index_demo;
EXTENDED उन सभी सूचकांकों को दिखाता है जो उपयोगकर्ता द्वारा उपयोग करने योग्य नहीं हैं लेकिन पूरी तरह से MySQL द्वारा प्रबंधित हैं।
यहां हम देखते हैं कि MySQL ने DB_ROW_ID पर एक समग्र सूचकांक (हम बाद में मिश्रित सूचकांकों पर चर्चा करेंगे) को परिभाषित किया है , DB_TRX_ID , DB_ROLL_PTR , और तालिका में परिभाषित सभी कॉलम। उपयोगकर्ता परिभाषित प्राथमिक कुंजी की अनुपस्थिति में, इस अनुक्रमणिका का उपयोग विशिष्ट रूप से रिकॉर्ड खोजने के लिए किया जाता है।
की और इंडेक्स में क्या अंतर है?
हालांकि शब्द key &index एक दूसरे के स्थान पर उपयोग किया जाता है, key का अर्थ है स्तंभ के व्यवहार पर थोपी गई बाधा। इस मामले में, बाधा यह है कि प्राथमिक कुंजी गैर-शून्य-सक्षम फ़ील्ड है जो विशिष्ट रूप से प्रत्येक पंक्ति की पहचान करती है। दूसरी ओर, index एक विशेष डेटा संरचना है जो तालिका में डेटा खोज की सुविधा प्रदान करती है।
आइए अब phone_no . पर प्राथमिक अनुक्रमणिका बनाएं और बनाए गए इंडेक्स की जांच करें:
ALTER TABLE index_demo ADD PRIMARY KEY (phone_no);
SHOW INDEXES FROM index_demo;
ध्यान दें कि CREATE INDEX प्राथमिक अनुक्रमणिका बनाने के लिए उपयोग नहीं किया जा सकता है, लेकिन ALTER TABLE उपयोग किया जाता है।

ऊपर दिए गए स्क्रीनशॉट में, हम देखते हैं कि phone_no . कॉलम पर एक प्राथमिक इंडेक्स बनाया गया है . निम्नलिखित छवियों के कॉलम इस प्रकार वर्णित हैं:
Table :वह टेबल जिस पर इंडेक्स बनाया जाता है।
Non_unique :यदि मान 1 है, तो अनुक्रमणिका अद्वितीय नहीं है, यदि मान 0 है, तो अनुक्रमणिका अद्वितीय है।
Key_name :बनाए गए सूचकांक का नाम। प्राइमरी इंडेक्स का नाम हमेशा PRIMARY होता है MySQL में, भले ही आपने इंडेक्स बनाते समय कोई इंडेक्स नाम दिया हो या नहीं।
Seq_in_index :इंडेक्स में कॉलम की अनुक्रम संख्या। यदि एकाधिक कॉलम इंडेक्स का हिस्सा हैं, तो अनुक्रम संख्या को इस आधार पर असाइन किया जाएगा कि इंडेक्स निर्माण समय के दौरान कॉलम कैसे ऑर्डर किए गए थे। क्रम संख्या 1 से शुरू होती है।
Collation :इंडेक्स में कॉलम को कैसे सॉर्ट किया जाता है। A मतलब आरोही, D मतलब अवरोही, NULL मतलब क्रमबद्ध नहीं है।
Cardinality :अनुक्रमणिका में अद्वितीय मानों की अनुमानित संख्या। अधिक कार्डिनैलिटी का अर्थ है उच्च संभावना है कि क्वेरी ऑप्टिमाइज़र प्रश्नों के लिए अनुक्रमणिका चुन लेगा।
Sub_part :सूचकांक उपसर्ग। यह NULL है यदि संपूर्ण कॉलम अनुक्रमित है। अन्यथा, यह कॉलम आंशिक रूप से अनुक्रमित होने की स्थिति में अनुक्रमित बाइट्स की संख्या दिखाता है। हम आंशिक अनुक्रमणिका को बाद में परिभाषित करेंगे।
Packed :इंगित करता है कि कुंजी कैसे पैक की जाती है; null अगर ऐसा नहीं है।
null :YES यदि कॉलम में NULL हो सकता है मान और रिक्त यदि ऐसा नहीं है।
Index_type :इंगित करता है कि इस अनुक्रमणिका के लिए किस अनुक्रमण डेटा संरचना का उपयोग किया गया है। कुछ संभावित उम्मीदवार हैं — BTREE , HASH , RTREE , या FULLTEXT ।
Comment :सूचकांक के बारे में जानकारी अपने स्वयं के कॉलम में वर्णित नहीं है।
Index_comment :जब आपने COMMENT . के साथ अनुक्रमणिका बनाई थी तब निर्दिष्ट अनुक्रमणिका के लिए टिप्पणी विशेषता।
अब देखते हैं कि क्या यह अनुक्रमणिका उन पंक्तियों की संख्या को कम करती है जिन्हें किसी दिए गए phone_no के लिए खोजा जाएगा WHERE . में एक प्रश्न का खंड।
EXPLAIN SELECT * FROM index_demo WHERE phone_no = '9281072002';
इस स्नैपशॉट में, ध्यान दें कि rows कॉलम वापस आ गया है 1 केवल, possible_keys और key दोनों रिटर्न PRIMARY . तो इसका अनिवार्य रूप से मतलब है कि PRIMARY . नामक प्राथमिक अनुक्रमणिका का उपयोग करना (जब आप प्राथमिक कुंजी बनाते हैं तो नाम स्वतः असाइन किया जाता है), क्वेरी ऑप्टिमाइज़र सीधे रिकॉर्ड पर जाता है और उसे प्राप्त करता है। यह बहुत ही कुशल है। यह ठीक उसी के लिए है - अतिरिक्त स्थान की कीमत पर खोज के दायरे को कम करने के लिए।
संकुल अनुक्रमणिका:
एक clustered index एक ही टेबल स्पेस या एक ही डिस्क फाइल में डेटा के साथ कोलोकेटेड किया जाता है। आप मान सकते हैं कि एक संकुल अनुक्रमणिका एक B-Tree है इंडेक्स जिसका लीफ नोड्स डिस्क पर वास्तविक डेटा ब्लॉक हैं, क्योंकि इंडेक्स और डेटा एक साथ रहते हैं। इस प्रकार की अनुक्रमणिका, अनुक्रमणिका कुंजी के तार्किक क्रम के अनुसार डिस्क पर डेटा को भौतिक रूप से व्यवस्थित करती है।
भौतिक डेटा संगठन का क्या अर्थ है?
भौतिक रूप से, डेटा हजारों या लाखों डिस्क/डेटा ब्लॉक में डिस्क पर व्यवस्थित होता है। क्लस्टर्ड इंडेक्स के लिए, यह अनिवार्य नहीं है कि सभी डिस्क ब्लॉक संक्रामक रूप से संग्रहीत हों। जब भी आवश्यक हो, भौतिक डेटा ब्लॉक हर समय ओएस द्वारा इधर-उधर ले जाया जाता है। भौतिक डेटा स्थान को कैसे प्रबंधित किया जाता है, इस पर एक डेटाबेस सिस्टम का कोई पूर्ण नियंत्रण नहीं होता है, लेकिन डेटा ब्लॉक के अंदर, रिकॉर्ड को इंडेक्स कुंजी के तार्किक क्रम में संग्रहीत या प्रबंधित किया जा सकता है। निम्नलिखित सरलीकृत आरेख इसकी व्याख्या करता है:
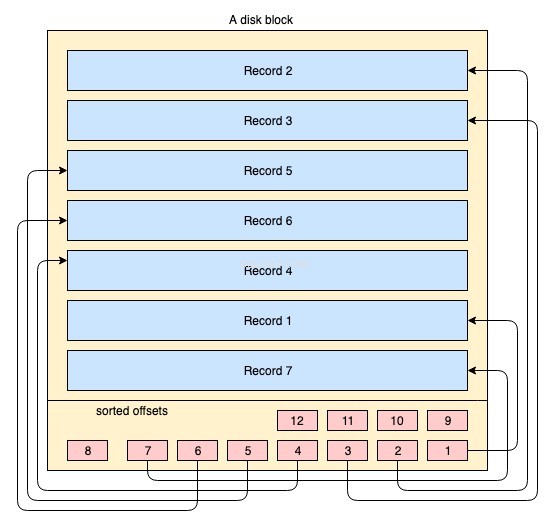
- पीले रंग का बड़ा आयत डिस्क ब्लॉक / डेटा ब्लॉक का प्रतिनिधित्व करता है
- नीले रंग के आयत उस ब्लॉक के अंदर पंक्तियों के रूप में संग्रहीत डेटा का प्रतिनिधित्व करते हैं
- फुटर क्षेत्र उस ब्लॉक के सूचकांक को दर्शाता है जहां लाल रंग के छोटे आयत एक विशेष कुंजी के क्रमबद्ध क्रम में रहते हैं। ये छोटे ब्लॉक रिकॉर्ड के ऑफसेट की ओर इशारा करने वाले पॉइंटर्स के अलावा और कुछ नहीं हैं।
डिस्क ब्लॉक पर किसी भी मनमाने क्रम में रिकॉर्ड संग्रहीत किए जाते हैं। जब भी नए रिकॉर्ड जोड़े जाते हैं, वे अगले उपलब्ध स्थान में जुड़ जाते हैं। जब भी कोई मौजूदा रिकॉर्ड अपडेट किया जाता है, तो OS यह तय करता है कि क्या वह रिकॉर्ड अभी भी उसी स्थिति में फिट हो सकता है या उस रिकॉर्ड के लिए एक नई स्थिति आवंटित करनी होगी।
इसलिए अभिलेखों की स्थिति पूरी तरह से ओएस द्वारा नियंत्रित की जाती है और किन्हीं दो अभिलेखों के क्रम के बीच कोई निश्चित संबंध मौजूद नहीं है। कुंजी के तार्किक क्रम में रिकॉर्ड लाने के लिए, डिस्क पृष्ठों में पाद लेख में एक इंडेक्स सेक्शन होता है, इंडेक्स में कुंजी के क्रम में ऑफ़सेट पॉइंटर्स की एक सूची होती है। हर बार जब कोई रिकॉर्ड बदला या बनाया जाता है, तो अनुक्रमणिका समायोजित हो जाती है।
इस तरह, आपको वास्तव में भौतिक रिकॉर्ड को एक निश्चित क्रम में व्यवस्थित करने की परवाह करने की आवश्यकता नहीं है, बल्कि उस क्रम में एक छोटा अनुक्रमणिका अनुभाग बनाए रखा जाता है और रिकॉर्ड प्राप्त करना या बनाए रखना बहुत आसान हो जाता है।
क्लस्टर इंडेक्स का लाभ:
संबंधित डेटा का यह क्रम या सह-स्थान वास्तव में एक संकुल अनुक्रमणिका को तेज़ बनाता है। जब डिस्क से डेटा प्राप्त किया जाता है, तो डेटा वाले पूरे ब्लॉक को सिस्टम द्वारा पढ़ा जाता है क्योंकि हमारा डिस्क IO सिस्टम ब्लॉक में डेटा लिखता और पढ़ता है। इसलिए श्रेणी प्रश्नों के मामले में, यह बहुत संभव है कि कोलोकेटेड डेटा मेमोरी में बफ़र किया गया हो। मान लें कि आप निम्न क्वेरी को सक्रिय करते हैं:
SELECT * FROM index_demo WHERE phone_no > '9010000000' AND phone_no < '9020000000'
क्वेरी निष्पादित होने पर स्मृति में डेटा ब्लॉक प्राप्त किया जाता है। मान लें कि डेटा ब्लॉक में phone_no है 9010000000 . की सीमा में से 9030000000 . तो आपने क्वेरी में जिस भी श्रेणी का अनुरोध किया है, वह ब्लॉक में मौजूद डेटा का एक सबसेट है। यदि आप अब अगली क्वेरी को सीमा में सभी फ़ोन नंबर प्राप्त करने के लिए सक्रिय करते हैं, तो 9015000000 से कहें करने के लिए 9019000000 , आपको डिस्क से कोई और ब्लॉक लाने की आवश्यकता नहीं है। संपूर्ण डेटा डेटा के वर्तमान ब्लॉक में पाया जा सकता है, इस प्रकार clustered_index एक ही डेटा ब्लॉक में जितना संभव हो सके संबंधित डेटा को समेट कर डिस्क IO की संख्या को कम करता है। यह घटी हुई डिस्क IO प्रदर्शन में सुधार लाती है।
इसलिए यदि आपके पास प्राथमिक कुंजी के बारे में अच्छी तरह से सोचा गया है और आपके प्रश्न प्राथमिक कुंजी पर आधारित हैं, तो प्रदर्शन बहुत तेज़ होगा।
क्लस्टर इंडेक्स की बाधाएं:
चूंकि क्लस्टर इंडेक्स डेटा के भौतिक संगठन को प्रभावित करता है, इसलिए प्रति टेबल केवल एक क्लस्टर इंडेक्स हो सकता है।
प्राथमिक कुंजी और क्लस्टर इंडेक्स के बीच संबंध:
आप MySQL में InnoDB का उपयोग करके मैन्युअल रूप से क्लस्टर इंडेक्स नहीं बना सकते। MySQL इसे आपके लिए चुनता है। लेकिन यह कैसे चुनता है? निम्नलिखित अंश MySQL दस्तावेज़ीकरण से हैं:
जब आप एकPRIMARY KEYपरिभाषित करते हैं आपकी टेबल पर,InnoDBइसे संकुल सूचकांक के रूप में उपयोग करता है। आपके द्वारा बनाई जाने वाली प्रत्येक तालिका के लिए प्राथमिक कुंजी परिभाषित करें। यदि कोई लॉजिकल यूनिक और नॉन-नल कॉलम या कॉलम का सेट नहीं है, तो एक नया ऑटो-इंक्रीमेंट कॉलम जोड़ें, जिसका मान अपने आप भर जाता है।
यदि आपPRIMARY KEYपरिभाषित नहीं करते हैं आपकी तालिका के लिए, MySQL पहलेUNIQUE. का पता लगाता है इंडेक्स जहां सभी प्रमुख कॉलमNOT NULL. हैं औरInnoDBइसे संकुल सूचकांक के रूप में उपयोग करता है।
यदि तालिका में कोईPRIMARY KEYनहीं है या उपयुक्तUNIQUEअनुक्रमणिका,InnoDBआंतरिक रूप सेGEN_CLUST_INDEX. नामक एक छिपी हुई क्लस्टर अनुक्रमणिका उत्पन्न करता है पंक्ति आईडी मान वाले सिंथेटिक कॉलम पर। पंक्तियों को आईडी द्वारा आदेश दिया जाता है किInnoDBऐसी तालिका में पंक्तियों को असाइन करता है। पंक्ति आईडी एक 6-बाइट फ़ील्ड है जो नई पंक्तियों को सम्मिलित करते ही एकरस रूप से बढ़ जाती है। इस प्रकार, पंक्ति आईडी द्वारा क्रमबद्ध पंक्तियाँ भौतिक रूप से सम्मिलन क्रम में हैं।
संक्षेप में, MySQL InnoDB इंजन वास्तव में प्रदर्शन में सुधार के लिए प्राथमिक इंडेक्स को क्लस्टर इंडेक्स के रूप में प्रबंधित करता है, इसलिए डिस्क पर प्राथमिक कुंजी और वास्तविक रिकॉर्ड एक साथ क्लस्टर किए जाते हैं।
प्राथमिक कुंजी (क्लस्टर) इंडेक्स की संरचना:
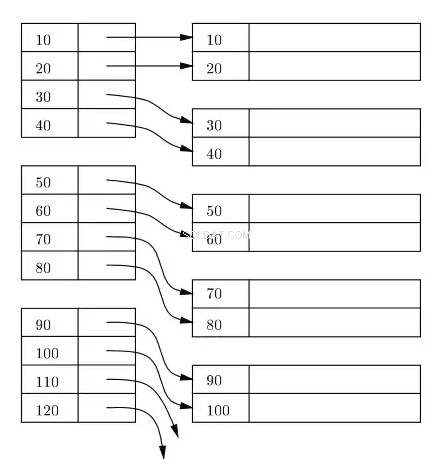
एक इंडेक्स को आमतौर पर डिस्क और इन-मेमोरी पर बी + ट्री के रूप में बनाए रखा जाता है, और किसी भी इंडेक्स को डिस्क पर ब्लॉक में स्टोर किया जाता है। इन ब्लॉकों को इंडेक्स ब्लॉक कहा जाता है। अनुक्रमणिका ब्लॉक में प्रविष्टियाँ हमेशा अनुक्रमणिका/खोज कुंजी पर क्रमबद्ध की जाती हैं। इंडेक्स के लीफ इंडेक्स ब्लॉक में एक रो लोकेटर होता है। प्राथमिक इंडेक्स के लिए, रो लोकेटर डिस्क पर डेटा ब्लॉक के संबंधित भौतिक स्थान के वर्चुअल एड्रेस को संदर्भित करता है जहां पंक्तियों को इंडेक्स की के अनुसार सॉर्ट किया जाता है।
निम्नलिखित आरेख में, बाईं ओर के आयत पत्ती स्तर सूचकांक ब्लॉक का प्रतिनिधित्व करते हैं, और दाईं ओर के आयत डेटा ब्लॉक का प्रतिनिधित्व करते हैं। तार्किक रूप से डेटा ब्लॉक एक क्रमबद्ध क्रम में संरेखित प्रतीत होते हैं, लेकिन जैसा कि पहले ही बताया जा चुका है, वास्तविक भौतिक स्थान इधर-उधर बिखरे हो सकते हैं।
क्या गैर-प्राथमिक कुंजी पर प्राथमिक अनुक्रमणिका बनाना संभव है?
MySQL में, एक प्राथमिक अनुक्रमणिका स्वचालित रूप से बनाई जाती है, और हम पहले ही ऊपर बता चुके हैं कि MySQL प्राथमिक अनुक्रमणिका को कैसे चुनता है। लेकिन डेटाबेस की दुनिया में, प्राथमिक कुंजी कॉलम पर एक इंडेक्स बनाना वास्तव में जरूरी नहीं है - प्राथमिक इंडेक्स किसी भी गैर प्राथमिक कुंजी कॉलम पर भी बनाया जा सकता है। लेकिन जब प्राथमिक कुंजी पर बनाया जाता है, तो सभी प्रमुख प्रविष्टियां अनुक्रमणिका में अद्वितीय होती हैं, जबकि अन्य मामले में, प्राथमिक अनुक्रमणिका में डुप्लीकेट कुंजी भी हो सकती है।
क्या प्राथमिक कुंजी को हटाना संभव है?
प्राथमिक कुंजी को हटाना संभव है। जब आप प्राथमिक कुंजी हटाते हैं, तो संबंधित क्लस्टर इंडेक्स और साथ ही उस कॉलम की विशिष्टता संपत्ति खो जाती है।
ALTER TABLE `index_demo` DROP PRIMARY KEY;
- If the primary key does not exist, you get the following error:
"ERROR 1091 (42000): Can't DROP 'PRIMARY'; check that column/key exists"प्राथमिक अनुक्रमणिका के लाभ:
- प्राथमिक अनुक्रमणिका आधारित श्रेणी क्वेरी बहुत कुशल हैं। ऐसी संभावना हो सकती है कि डिस्क से डेटाबेस ने जो डिस्क ब्लॉक पढ़ा है, उसमें क्वेरी से संबंधित सभी डेटा शामिल हैं, क्योंकि प्राथमिक इंडेक्स क्लस्टर किया गया है और रिकॉर्ड भौतिक रूप से ऑर्डर किए गए हैं। तो डेटा का स्थान प्राथमिक सूचकांक द्वारा प्रदान किया जा सकता है।
- प्राथमिक कुंजी का लाभ उठाने वाली कोई भी क्वेरी बहुत तेज़ है।
प्राथमिक अनुक्रमणिका के नुकसान:
- चूंकि प्राइमरी इंडेक्स में वर्चुअल एड्रेस स्पेस के माध्यम से डेटा ब्लॉक एड्रेस का सीधा संदर्भ होता है और डिस्क ब्लॉक को इंडेक्स की के क्रम में भौतिक रूप से व्यवस्थित किया जाता है, हर बार ओएस कुछ डिस्क पेज को विभाजित करता है
DMLसंचालन जैसेINSERT/UPDATE/DELETE, प्राथमिक सूचकांक को भी अद्यतन करने की आवश्यकता है। तोDMLसंचालन प्राथमिक सूचकांक के प्रदर्शन पर कुछ दबाव डालता है।
सेकेंडरी इंडेक्स:
क्लस्टर्ड इंडेक्स के अलावा कोई भी इंडेक्स सेकेंडरी इंडेक्स कहलाता है। द्वितीयक सूचकांक प्राथमिक सूचकांकों के विपरीत भौतिक भंडारण स्थानों को प्रभावित नहीं करते हैं।
आपको सेकेंडरी इंडेक्स की आवश्यकता कब पड़ती है?
आपके एप्लिकेशन में कई उपयोग के मामले हो सकते हैं जहां आप प्राथमिक कुंजी के साथ डेटाबेस से पूछताछ नहीं करते हैं। हमारे उदाहरण में phone_no प्राथमिक कुंजी है लेकिन हमें डेटाबेस को pan_no . के साथ क्वेरी करने की आवश्यकता हो सकती है , या name . ऐसे मामलों में यदि इस तरह के प्रश्नों की आवृत्ति बहुत अधिक है, तो आपको इन स्तंभों पर द्वितीयक सूचकांकों की आवश्यकता है।
MySQL में सेकेंडरी इंडेक्स कैसे बनाएं?
निम्न कमांड name . में एक सेकेंडरी इंडेक्स बनाता है index_demo . में कॉलम टेबल।
CREATE INDEX secondary_idx_1 ON index_demo (name);
सेकेंडरी इंडेक्स की संरचना:
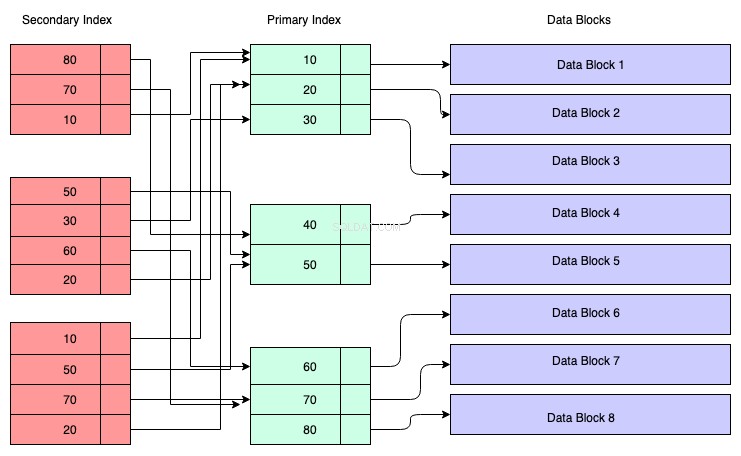
नीचे दिए गए आरेख में, लाल रंग के आयत द्वितीयक सूचकांक ब्लॉकों का प्रतिनिधित्व करते हैं। सेकेंडरी इंडेक्स को बी+ ट्री में भी मेंटेन किया जाता है और इसे उस की के अनुसार सॉर्ट किया जाता है जिस पर इंडेक्स बनाया गया था। लीफ नोड्स में प्राथमिक सूचकांक में संबंधित डेटा की कुंजी की एक प्रति होती है।
तो समझने के लिए, आप मान सकते हैं कि सेकेंडरी इंडेक्स में प्राथमिक कुंजी के पते का संदर्भ है, हालांकि ऐसा नहीं है। द्वितीयक अनुक्रमणिका के माध्यम से डेटा पुनर्प्राप्त करने का अर्थ है कि आपको दो B+ वृक्षों को पार करना होगा - एक स्वयं द्वितीयक अनुक्रमणिका B+ वृक्ष है, और दूसरा प्राथमिक अनुक्रमणिका B+ वृक्ष है।
एक सेकेंडरी इंडेक्स के फायदे:
तार्किक रूप से आप जितने चाहें उतने द्वितीयक सूचकांक बना सकते हैं। लेकिन वास्तव में कितने सूचकांकों की वास्तव में आवश्यकता है एक गंभीर विचार प्रक्रिया की आवश्यकता है क्योंकि प्रत्येक सूचकांक का अपना दंड होता है।
एक सेकेंडरी इंडेक्स के नुकसान:
DML के साथ ऑपरेशन जैसे DELETE / INSERT , सेकेंडरी इंडेक्स को भी अपडेट करने की जरूरत है ताकि प्राइमरी की कॉलम की कॉपी को डिलीट / इन्सर्ट किया जा सके। ऐसे मामलों में, बहुत सारे सेकेंडरी इंडेक्स का अस्तित्व समस्याएँ पैदा कर सकता है।
साथ ही, यदि प्राथमिक कुंजी URL जैसी बहुत बड़ी है तो , चूंकि द्वितीयक अनुक्रमणिका में प्राथमिक कुंजी स्तंभ मान की एक प्रति होती है, यह भंडारण के मामले में अक्षम हो सकता है। अधिक द्वितीयक कुंजियों का अर्थ है प्राथमिक कुंजी स्तंभ मान की अधिक संख्या में डुप्लिकेट प्रतियाँ, इसलिए बड़ी प्राथमिक कुंजी के मामले में अधिक संग्रहण। साथ ही प्राथमिक कुंजी स्वयं कुंजियों को संग्रहीत करती है, इसलिए संग्रहण पर संयुक्त प्रभाव बहुत अधिक होगा।
प्राथमिक अनुक्रमणिका हटाने से पहले विचार:
MySQL में, आप प्राथमिक कुंजी को छोड़ कर प्राथमिक अनुक्रमणिका को हटा सकते हैं। हम पहले ही देख चुके हैं कि द्वितीयक सूचकांक प्राथमिक सूचकांक पर निर्भर करता है। इसलिए यदि आप एक प्राथमिक अनुक्रमणिका को हटाते हैं, तो सभी द्वितीयक सूचकांकों को अद्यतन करना होगा ताकि नई प्राथमिक अनुक्रमणिका कुंजी की एक प्रति शामिल हो, जिसे MySQL स्वतः समायोजित करता है।
यह प्रक्रिया महंगी होती है जब कई माध्यमिक सूचकांक मौजूद होते हैं। साथ ही अन्य तालिकाओं में प्राथमिक कुंजी के लिए एक विदेशी कुंजी संदर्भ हो सकता है, इसलिए प्राथमिक कुंजी को हटाने से पहले आपको उन विदेशी कुंजी संदर्भों को हटाना होगा।
जब एक प्राथमिक कुंजी हटा दी जाती है, तो MySQL स्वचालित रूप से आंतरिक रूप से एक और प्राथमिक कुंजी बनाता है, और यह एक महंगा ऑपरेशन है।
UNIQUE Key Index:
प्राथमिक कुंजियों की तरह, अद्वितीय कुंजियाँ भी एक अंतर के साथ विशिष्ट रूप से रिकॉर्ड की पहचान कर सकती हैं - अद्वितीय कुंजी कॉलम में null हो सकता है मान।
अन्य डेटाबेस सर्वरों के विपरीत, MySQL में एक अद्वितीय कुंजी कॉलम में कई null हो सकते हैं संभव के रूप में मूल्य। SQL मानक में, null मतलब एक अपरिभाषित मूल्य। तो अगर MySQL में केवल एक null होना चाहिए एक अद्वितीय कुंजी कॉलम में मान, यह मान लेना चाहिए कि सभी शून्य मान समान हैं।
लेकिन तार्किक रूप से यह सही नहीं है क्योंकि null अपरिभाषित का अर्थ है - और अपरिभाषित मूल्यों की एक दूसरे के साथ तुलना नहीं की जा सकती है, यह null की प्रकृति है . चूंकि MySQL यह दावा नहीं कर सकता कि क्या सभी null s का मतलब वही है, यह कई null . की अनुमति देता है कॉलम में मान।
निम्न कमांड दिखाता है कि MySQL में एक अद्वितीय कुंजी इंडेक्स कैसे बनाया जाता है:
CREATE UNIQUE INDEX unique_idx_1 ON index_demo (pan_no);
समग्र अनुक्रमणिका:
MySQL आपको 16 कॉलम तक कई कॉलम पर इंडेक्स परिभाषित करने देता है। इस इंडेक्स को मल्टी-कॉलम/कंपोजिट/कंपाउंड इंडेक्स कहा जाता है।
मान लें कि हमारे पास 4 कॉलम पर परिभाषित एक इंडेक्स है - col1 , col2 , col3 , col4 . समग्र अनुक्रमणिका के साथ, हमारे पास col1 . पर खोज क्षमता है , (col1, col2) , (col1, col2, col3) , (col1, col2, col3, col4) . इसलिए हम अनुक्रमित कॉलम के किसी भी बाईं ओर उपसर्ग का उपयोग कर सकते हैं, लेकिन हम बीच से एक कॉलम को नहीं छोड़ सकते हैं और इसका उपयोग कर सकते हैं जैसे - (col1, col3) या (col1, col2, col4) या col3 या col4 आदि। ये अमान्य संयोजन हैं।
निम्न आदेश हमारी तालिका में 2 समग्र अनुक्रमणिका बनाते हैं:
CREATE INDEX composite_index_1 ON index_demo (phone_no, name, age);
CREATE INDEX composite_index_2 ON index_demo (pan_no, name, age);
यदि आपकी कोई क्वेरी है जिसमें WHERE . है कई कॉलम पर क्लॉज, कंपोजिट इंडेक्स के कॉलम के क्रम में क्लॉज लिखें। सूचकांक उस क्वेरी को लाभान्वित करेगा। वास्तव में, एक संयुक्त सूचकांक के लिए कॉलम तय करते समय, आप अपने सिस्टम के विभिन्न उपयोग मामलों का विश्लेषण कर सकते हैं और कॉलम के क्रम के साथ आने का प्रयास कर सकते हैं जो आपके अधिकांश उपयोग मामलों को लाभान्वित करेगा।
कम्पोजिट इंडेक्स JOIN में आपकी मदद कर सकते हैं &SELECT प्रश्न भी। उदाहरण:निम्नलिखित में SELECT * क्वेरी, composite_index_2 उपयोग किया जाता है।

जब कई इंडेक्स परिभाषित किए जाते हैं, तो MySQL क्वेरी ऑप्टिमाइज़र उस इंडेक्स को चुनता है जो बेहतर दक्षता के लिए सबसे बड़ी संख्या में पंक्तियों को हटा देता है या यथासंभव कम पंक्तियों को स्कैन करता है।
हम समग्र सूचकांकों का उपयोग क्यों करते हैं ? हम जिन स्तंभों में रुचि रखते हैं, उन पर एकाधिक द्वितीयक सूचकांकों को परिभाषित क्यों न करें?
MySQL UNION को छोड़कर प्रति क्वेरी प्रति तालिका केवल एक अनुक्रमणिका का उपयोग करता है। (यूनियन में, प्रत्येक तार्किक क्वेरी को अलग से चलाया जाता है, और परिणाम मर्ज किए जाते हैं।) इसलिए कई स्तंभों पर कई सूचकांकों को परिभाषित करने की गारंटी नहीं है कि उन सूचकांकों का उपयोग किया जाएगा, भले ही वे क्वेरी का हिस्सा हों।
MySQL इंडेक्स स्टैटिस्टिक्स नामक कुछ रखता है जो MySQL को यह अनुमान लगाने में मदद करता है कि सिस्टम में डेटा कैसा दिखता है। इंडेक्स आंकड़े हालांकि एक सामान्यीकरण है, लेकिन इस मेटा डेटा के आधार पर, MySQL यह तय करता है कि वर्तमान क्वेरी के लिए कौन सा इंडेक्स उपयुक्त है।
कंपोजिट इंडेक्स कैसे काम करता है?
कंपोजिट इंडेक्स में उपयोग किए जाने वाले कॉलम को एक साथ जोड़ दिया जाता है, और उन संयोजित कुंजियों को बी + ट्री का उपयोग करके क्रमबद्ध क्रम में संग्रहीत किया जाता है। जब आप कोई खोज करते हैं, तो आपकी खोज कुंजियों के संयोजन का मिलान संयुक्त अनुक्रमणिका की कुंजियों से किया जाता है। फिर यदि आपकी खोज कुंजियों के क्रम और समग्र अनुक्रमणिका स्तंभों के क्रम के बीच कोई बेमेल है, तो अनुक्रमणिका का उपयोग नहीं किया जा सकता है।
हमारे उदाहरण में, निम्न रिकॉर्ड के लिए, pan_no को जोड़कर एक समग्र अनुक्रमणिका कुंजी बनाई गई है , name , age — HJKXS9086Wkousik28 ।
+--------+------+------------+------------+
name
age
pan_no
phone_no
+--------+------+------------+------------+
kousik
28
HJKXS9086W
9090909090कैसे पहचानें कि आपको कंपोजिट इंडेक्स की जरूरत है:
- अपने उपयोग के मामलों के अनुसार पहले अपने प्रश्नों का विश्लेषण करें। यदि आप देखते हैं कि कुछ फ़ील्ड कई प्रश्नों में एक साथ दिखाई दे रहे हैं, तो आप एक संयुक्त अनुक्रमणिका बनाने पर विचार कर सकते हैं।
- अगर आप
col1में एक इंडेक्स बना रहे हैं और एक समग्र अनुक्रमणिका (col1. में ,col2), तब ही कंपोजिट इंडेक्स ठीक होना चाहिए।col1अकेले कंपोजिट इंडेक्स द्वारा ही परोसा जा सकता है क्योंकि यह इंडेक्स का लेफ्ट साइड प्रीफिक्स है। - कार्डिनैलिटी पर विचार करें। अगर कंपोजिट इंडेक्स में इस्तेमाल किए गए कॉलम एक साथ उच्च कार्डिनैलिटी रखते हैं, तो वे कंपोजिट इंडेक्स के लिए अच्छे उम्मीदवार हैं।
कवरिंग इंडेक्स:
कवरिंग इंडेक्स एक विशेष प्रकार का कंपोजिट इंडेक्स होता है, जहां क्वेरी में निर्दिष्ट सभी कॉलम इंडेक्स में कहीं मौजूद होते हैं। इसलिए क्वेरी ऑप्टिमाइज़र को डेटा प्राप्त करने के लिए डेटाबेस को हिट करने की आवश्यकता नहीं है - बल्कि यह इंडेक्स से ही परिणाम प्राप्त करता है। उदाहरण:हमने पहले से ही (pan_no, name, age) . पर एक समग्र अनुक्रमणिका परिभाषित की है , तो अब निम्नलिखित प्रश्न पर विचार करें:
SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = 'kousik'
SELECT . में उल्लिखित कॉलम &WHERE खंड समग्र सूचकांक का हिस्सा हैं। तो इस मामले में, हम वास्तव में age . का मान प्राप्त कर सकते हैं कंपोजिट इंडेक्स से ही कॉलम। आइए देखें कि EXPLAIN क्या है इस क्वेरी के लिए कमांड शो:
EXPLAIN FORMAT=JSON SELECT age FROM index_demo WHERE pan_no = 'HJKXS9086W' AND name = '111kousik1';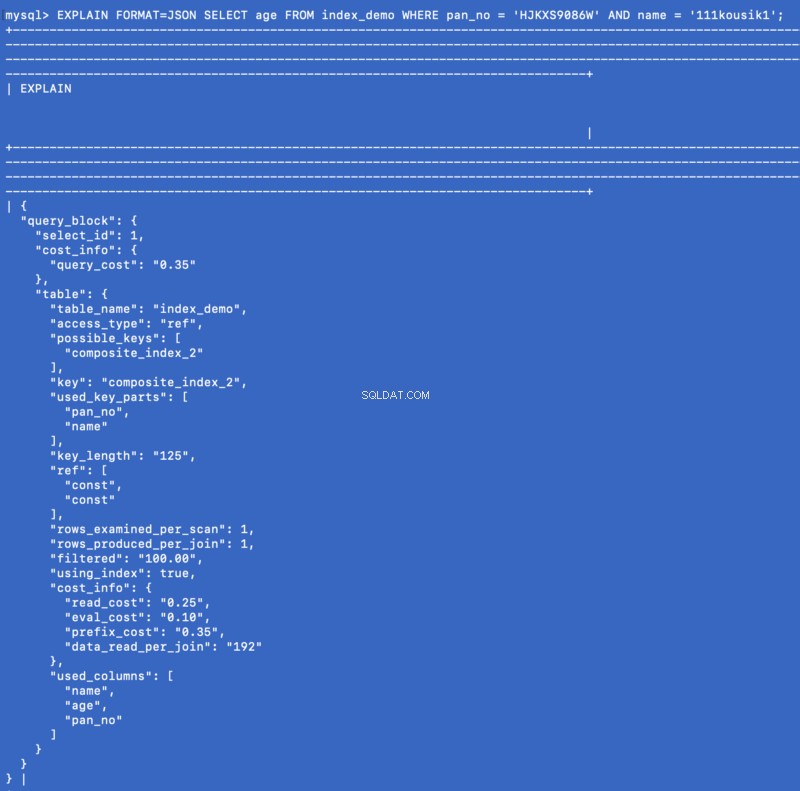
उपरोक्त प्रतिक्रिया में, ध्यान दें कि एक कुंजी है - using_index जो true . पर सेट है जो दर्शाता है कि प्रश्न का उत्तर देने के लिए कवरिंग इंडेक्स का उपयोग किया गया है।
मुझे नहीं पता कि उत्पादन वातावरण में कवरिंग इंडेक्स की कितनी सराहना की जाती है, लेकिन स्पष्ट रूप से यह एक अच्छा अनुकूलन प्रतीत होता है यदि क्वेरी बिल के अनुकूल हो।
आंशिक इंडेक्स:
हम पहले से ही जानते हैं कि सूचकांक अंतरिक्ष की कीमत पर हमारे प्रश्नों को गति देते हैं। आपके पास जितने अधिक सूचकांक होंगे, भंडारण की आवश्यकता उतनी ही अधिक होगी। हमने पहले ही secondary_idx_1 . नामक एक अनुक्रमणिका बना ली है कॉलम पर name . कॉलम name किसी भी लम्बाई के बड़े मान हो सकते हैं। साथ ही इंडेक्स में, रो लोकेटर या रो पॉइंटर्स के मेटाडेटा का अपना आकार होता है। तो कुल मिलाकर, एक इंडेक्स में उच्च स्टोरेज और मेमोरी लोड हो सकता है।
MySQL में, डेटा के पहले कुछ बाइट्स पर भी एक इंडेक्स बनाना संभव है। उदाहरण:निम्न कमांड नाम के पहले 4 बाइट्स पर एक इंडेक्स बनाता है। हालांकि यह विधि मेमोरी ओवरहेड को एक निश्चित राशि से कम कर देती है, इंडेक्स कई पंक्तियों को समाप्त नहीं कर सकता है, क्योंकि इस उदाहरण में पहले 4 बाइट्स कई नामों में सामान्य हो सकते हैं। आमतौर पर इस प्रकार के उपसर्ग अनुक्रमण CHAR . पर समर्थित होते हैं ,VARCHAR , BINARY , VARBINARY कॉलम का प्रकार।
CREATE INDEX secondary_index_1 ON index_demo (name(4));इंडेक्स को परिभाषित करने पर क्या होता है?
आइए SHOW EXTENDED चलाएं फिर से आदेश दें:
SHOW EXTENDED INDEXES FROM index_demo;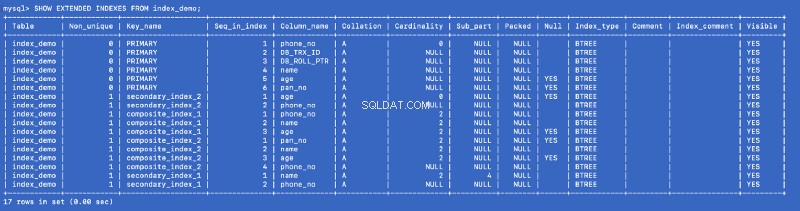
हमने secondary_index_1 . को परिभाषित किया है name . पर , लेकिन MySQL ने (name . पर एक कंपोजिट इंडेक्स बनाया है , phone_no ) जहां phone_no प्राथमिक कुंजी स्तंभ है। हमने secondary_index_2 . बनाया है age . पर &MySQL ने (age . पर एक समग्र अनुक्रमणिका बनाई है , phone_no ) हमने composite_index_2 . बनाया है चालू (pan_no , name , age ) और MySQL ने (pan_no . पर एक कंपोजिट इंडेक्स बनाया है , name , age , phone_no ) कंपोजिट इंडेक्स composite_index_1 पहले से ही phone_no है इसके हिस्से के रूप में।
इसलिए हम जो भी इंडेक्स बनाते हैं, बैकग्राउंड में MySQL एक बैकिंग कंपोजिट इंडेक्स बनाता है जो प्राथमिक कुंजी की ओर इशारा करता है। इसका मतलब है कि प्राथमिक कुंजी MySQL अनुक्रमण दुनिया में प्रथम श्रेणी का नागरिक है। It also proves that all the indexes are backed by a copy of the primary index —but I am not sure whether a single copy of the primary index is shared or different copies are used for different indexes.
There are many other indices as well like Spatial index and Full Text Search index offered by MySQL. I have not yet experimented with those indices, so I’m not discussing them in this post.
General Indexing guidelines:
- Since indices consume extra memory, carefully decide how many &what type of index will suffice your need.
- With
DMLoperations, indices are updated, so write operations are quite costly with indexes. The more indices you have, the greater the cost. Indexes are used to make read operations faster. So if you have a system that is write heavy but not read heavy, think hard about whether you need an index or not. - Cardinality is important — cardinality means the number of distinct values in a column. If you create an index in a column that has low cardinality, that’s not going to be beneficial since the index should reduce search space. Low cardinality does not significantly reduce search space.
Example:if you create an index on a boolean (int1or0only ) type column, the index will be very skewed since cardinality is less (cardinality is 2 here). But if this boolean field can be combined with other columns to produce high cardinality, go for that index when necessary. - Indices might need some maintenance as well if old data still remains in the index. They need to be deleted otherwise memory will be hogged, so try to have a monitoring plan for your indices.
In the end, it’s extremely important to understand the different aspects of database indexing. It will help while doing low level system designing. Many real-life optimizations of our applications depend on knowledge of such intricate details. A carefully chosen index will surely help you boost up your application’s performance.
Please do clap &share with your friends &on social media if you like this article. :)
References:
- https://dev.mysql.com/doc/refman/5.7/en/innodb-index-types.html
- https://www.quora.com/What-is-difference-between-primary-index-and-secondary-index-exactly-And-whats-advantage-of-one-over-another
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html
- https://www.oreilly.com/library/view/high-performance-mysql/0596003064/ch04.html
- https://www.unofficialmysqlguide.com/covering-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/multiple-column-indexes.html
- https://dev.mysql.com/doc/refman/8.0/en/show-index.html
- https://dev.mysql.com/doc/refman/8.0/en/create-index.html