जब आप किसी ऐसे प्रोजेक्ट पर काम कर रहे होते हैं जिसमें बहुत सारे माइक्रोसर्विसेज होते हैं, तो इसमें कई डेटाबेस भी शामिल हो सकते हैं।
उदाहरण के लिए, आपके पास एक MySQL डेटाबेस और एक PostgreSQL डेटाबेस हो सकता है, दोनों अलग-अलग सर्वर पर चल रहे हैं।
आम तौर पर, दो डेटाबेस से डेटा में शामिल होने के लिए, आपको एक नया माइक्रोसर्विस शुरू करना होगा जो डेटा को एक साथ जोड़ देगा। लेकिन इससे सिस्टम की जटिलता बढ़ जाएगी।
इस ट्यूटोरियल में, हम लाइव मैटेरियलाइज्ड व्यू में MySQL और Postgres से जुड़ने के लिए मटेरियलाइज़ का उपयोग करेंगे। इसके बाद हम सीधे उस पर क्वेरी कर सकेंगे और मानक SQL का उपयोग करके रीयल-टाइम में दोनों डेटाबेस से परिणाम प्राप्त कर सकेंगे।
मटेरियलाइज़ एक स्रोत-उपलब्ध स्ट्रीमिंग डेटाबेस है जो रस्ट में लिखा गया है जो डेटा परिवर्तन के रूप में मेमोरी में SQL क्वेरी (एक भौतिक दृश्य) के परिणामों को बनाए रखता है।
ट्यूटोरियल में एक डेमो प्रोजेक्ट शामिल है जिसे आप docker-compose . का उपयोग करके शुरू कर सकते हैं ।
हम जिस डेमो प्रोजेक्ट का उपयोग करने जा रहे हैं, वह हमारी मॉक वेबसाइट पर ऑर्डर की निगरानी करेगा। यह ऐसे ईवेंट जेनरेट करेगा, जिनका उपयोग बाद में किसी कार्ट को लंबे समय के लिए छोड़ दिए जाने पर सूचनाएं भेजने के लिए किया जा सकता है।
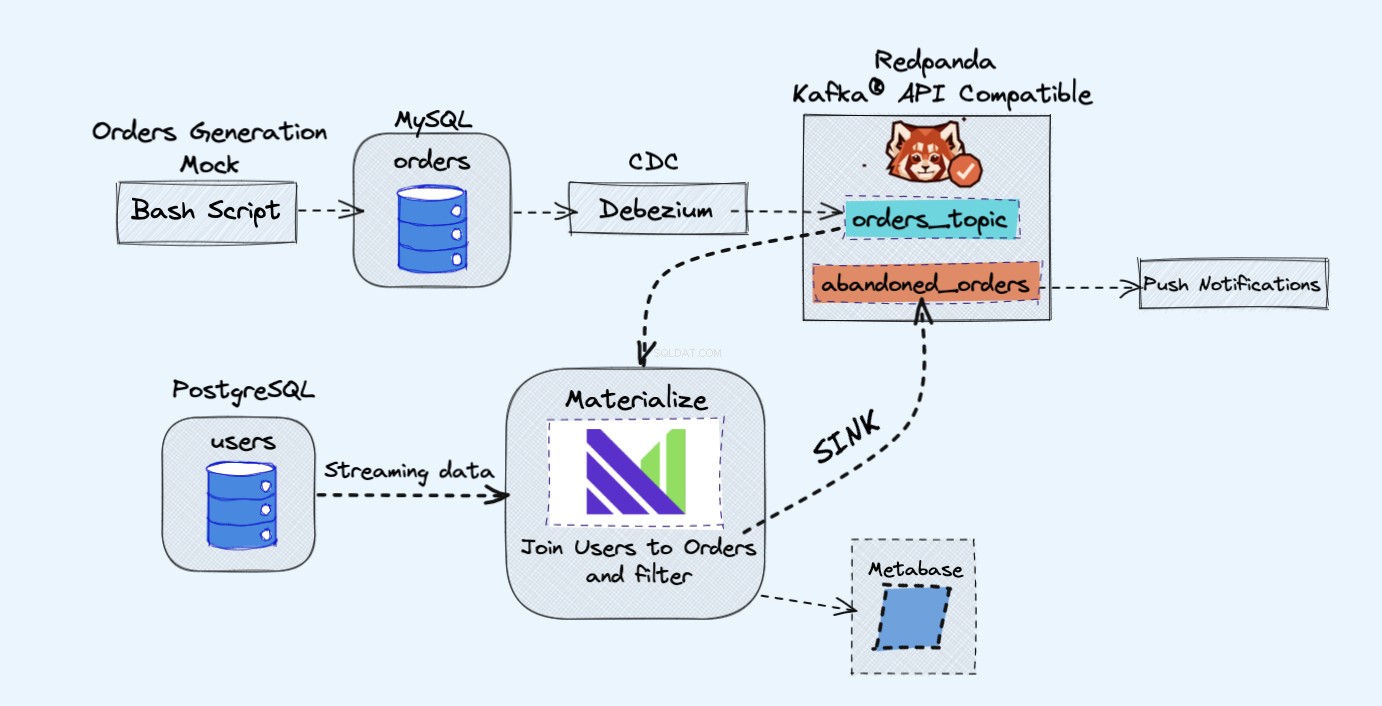
डेमो प्रोजेक्ट की संरचना इस प्रकार है:
आवश्यकताएँ
डेमो में हम जिन सभी सेवाओं का उपयोग करेंगे, वे डॉकर कंटेनरों के अंदर चलेंगी, इस तरह आपको डॉकर और डॉकर कंपोज़ के बजाय अपने लैपटॉप या सर्वर पर कोई अतिरिक्त सेवा स्थापित करने की आवश्यकता नहीं होगी।
यदि आपके पास पहले से डॉकर और डॉकर कंपोज़ स्थापित नहीं है, तो आप इसे यहाँ कैसे करें, इस पर आधिकारिक निर्देशों का पालन कर सकते हैं:
- डॉकर स्थापित करें
- डॉकर कंपोज़ इंस्टॉल करें
अवलोकन
जैसा कि ऊपर दिए गए चित्र में दिखाया गया है, हमारे पास निम्नलिखित घटक होंगे:
- निरंतर ऑर्डर जेनरेट करने के लिए एक नकली सेवा।
- आदेश एक MySQL डेटाबेस में संग्रहीत किया जाएगा ।
- जैसे ही डेटाबेस लिखता है, डेबेज़ियम MySQL के परिवर्तनों को Redpanda . में स्ट्रीम करता है विषय।
- हमारे पास एक पोस्टग्रेज भी होगा डेटाबेस जहां हम अपने उपयोगकर्ता प्राप्त कर सकते हैं।
- फिर हम इस Redpanda विषय को भौतिक रूप से . में शामिल करेंगे सीधे पोस्टग्रेज़ डेटाबेस के उपयोगकर्ताओं के साथ।
- Materialize में हम अपने ऑर्डर और उपयोगकर्ताओं को एक साथ जोड़ेंगे, कुछ फ़िल्टरिंग करेंगे, और एक भौतिक दृश्य बनाएंगे जो छोड़े गए कार्ट की जानकारी दिखाता है।
- फिर हम छोड़े गए कार्ट डेटा को एक नए रेडपांडा विषय पर भेजने के लिए एक सिंक बनाएंगे।
- अंत में हम मेटाबेस . का उपयोग करेंगे डेटा की कल्पना करने के लिए।
- आप बाद में उस नए विषय की जानकारी का उपयोग अपने उपयोगकर्ताओं को सूचनाएं भेजने और उन्हें याद दिलाने के लिए कर सकते हैं कि उनके पास एक परित्यक्त कार्ट है।
यहां एक साइड नोट के रूप में, आप रेडपांडा के बजाय काफ्का का उपयोग करके बिल्कुल ठीक होंगे। मुझे रेडपांडा की मेज पर आने वाली सादगी पसंद है, क्योंकि आप सभी काफ्का घटकों के बजाय एक रेडपांडा इंस्टेंस चला सकते हैं।
डेमो कैसे चलाएं
सबसे पहले, रिपॉजिटरी को क्लोन करके शुरू करें:
git clone https://github.com/bobbyiliev/materialize-tutorials.git
उसके बाद आप निर्देशिका तक पहुँच सकते हैं:
cd materialize-tutorials/mz-join-mysql-and-postgresql
आइए सबसे पहले रेडपांडा कंटेनर को चलाकर शुरू करें:
docker-compose up -d redpanda
चित्र बनाएं:
docker-compose build
अंत में, सभी सेवाएं प्रारंभ करें:
docker-compose up -d
मटेरियलाइज़ सीएलआई लॉन्च करने के लिए, आप निम्न कमांड चला सकते हैं:
docker-compose run mzcli
यह postgres-client . के साथ डॉकर कंटेनर के लिए सिर्फ एक शॉर्टकट है पूर्व-स्थापित। अगर आपके पास पहले से psql है आप चला सकते हैं psql -U materialize -h localhost -p 6875 materialize इसके बजाय।
काफ्का स्रोत कैसे बनाएं
अब जब आप मटेरियलाइज़ सीएलआई में हैं, तो आइए orders को परिभाषित करें mysql.shop में टेबल रेडपांडा स्रोतों के रूप में डेटाबेस:
CREATE SOURCE orders
FROM KAFKA BROKER 'redpanda:9092' TOPIC 'mysql.shop.orders'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081'
ENVELOPE DEBEZIUM;
यदि आपको orders . से उपलब्ध कॉलमों की जांच करनी है निम्नलिखित कथन चलाकर स्रोत:
SHOW COLUMNS FROM orders;
आप यह देखने में सक्षम होंगे कि, चूंकि मैटेरियलाइज़ रेडपांडा रजिस्ट्री से संदेश स्कीमा डेटा खींच रहा है, यह प्रत्येक विशेषता के लिए उपयोग किए जाने वाले कॉलम प्रकारों को जानता है:
name | nullable | type
--------------+----------+-----------
id | f | bigint
user_id | t | bigint
order_status | t | integer
price | t | numeric
created_at | f | text
updated_at | t | timestamp
भौतिकीकृत दृश्य कैसे बनाएं
इसके बाद, हम orders . से सभी डेटा प्राप्त करने के लिए, अपना पहला भौतिकीकृत दृश्य तैयार करेंगे रेडपांडा स्रोत:
CREATE MATERIALIZED VIEW orders_view AS
SELECT * FROM orders;
CREATE MATERIALIZED VIEW abandoned_orders AS
SELECT
user_id,
order_status,
SUM(price) as revenue,
COUNT(id) AS total
FROM orders_view
WHERE order_status=0
GROUP BY 1,2;
अब आप SELECT * FROM abandoned_orders; . का उपयोग कर सकते हैं परिणाम देखने के लिए:
SELECT * FROM abandoned_orders;
भौतिक विचारों को बनाने के बारे में अधिक जानकारी के लिए, भौतिकीकृत दस्तावेज़ीकरण के भौतिकीकृत दृश्य अनुभाग देखें।
पोस्टग्रेज सोर्स कैसे बनाएं
मटेरियलाइज़ में पोस्टग्रेज़ स्रोत बनाने के दो तरीके हैं:
- डेबेज़ियम का उपयोग ठीक वैसे ही जैसे हमने MySQL स्रोत के साथ किया था।
- पोस्टग्रेज़ मैटेरियलाइज़ सोर्स का उपयोग करना, जो आपको मैटेरियलाइज़ को पोस्टग्रेज़ से सीधे कनेक्ट करने की अनुमति देता है ताकि आपको डेबेज़ियम का उपयोग न करना पड़े।
इस डेमो के लिए, हम पोस्टग्रेज़ मटेरियलाइज़ सोर्स का उपयोग केवल एक प्रदर्शन के रूप में करेंगे कि इसका उपयोग कैसे किया जाए, लेकिन इसके बजाय डेबेज़ियम का उपयोग करने के लिए स्वतंत्र महसूस करें।
पोस्टग्रेज़ मटेरियलाइज़ सोर्स बनाने के लिए निम्नलिखित कथन चलाएँ:
CREATE MATERIALIZED SOURCE "mz_source" FROM POSTGRES
CONNECTION 'user=postgres port=5432 host=postgres dbname=postgres password=postgres'
PUBLICATION 'mz_source';
उपरोक्त कथन का एक संक्षिप्त विवरण:
MATERIALIZED:PostgreSQL स्रोत के डेटा को अमल में लाता है। सभी डेटा को मेमोरी में रखा जाता है और स्रोतों को सीधे चयन योग्य बनाता है।mz_source:PostgreSQL स्रोत का नाम।CONNECTION:PostgreSQL कनेक्शन पैरामीटर।PUBLICATION:पोस्टग्रेएसक्यूएल प्रकाशन, जिसमें अमल में लाने के लिए स्ट्रीम की जाने वाली टेबल शामिल हैं।
एक बार जब हम PostgreSQL स्रोत बना लेते हैं, तो PostgreSQL तालिकाओं को क्वेरी करने में सक्षम होने के लिए, हमें ऐसे दृश्य बनाने होंगे जो अपस्ट्रीम प्रकाशन की मूल तालिकाओं का प्रतिनिधित्व करते हों।
हमारे मामले में, हमारे पास केवल एक तालिका है जिसे users . कहा जाता है इसलिए हमें जिस कथन को चलाने की आवश्यकता होगी वह है:
CREATE VIEWS FROM SOURCE mz_source (users);
उपलब्ध दृश्य देखने के लिए निम्नलिखित कथन निष्पादित करें:
SHOW FULL VIEWS;
एक बार ऐसा करने के बाद, आप सीधे नए विचारों को क्वेरी कर सकते हैं:
SELECT * FROM users;
इसके बाद, आगे बढ़ते हैं और कुछ और दृश्य बनाते हैं।
काफ्का सिंक कैसे बनाएं
सिंक आपको मैटेरियलाइज़ से बाहरी स्रोत पर डेटा भेजने देता है।
इस डेमो के लिए, हम रेडपांडा का उपयोग करेंगे।
रेडपांडा काफ्का एपीआई-संगत है और मैटेरियलाइज इससे डेटा को उसी तरह प्रोसेस कर सकता है जैसे वह काफ्का स्रोत से डेटा को प्रोसेस करता है।
आइए एक भौतिक दृश्य बनाएं, जिसमें सभी उच्च मात्रा में भुगतान न किए गए ऑर्डर होंगे:
CREATE MATERIALIZED VIEW high_value_orders AS
SELECT
users.id,
users.email,
abandoned_orders.revenue,
abandoned_orders.total
FROM users
JOIN abandoned_orders ON abandoned_orders.user_id = users.id
GROUP BY 1,2,3,4
HAVING revenue > 2000;
जैसा कि आप देख सकते हैं, यहां हम वास्तव में users . में शामिल हो रहे हैं देखें जो सीधे हमारे पोस्टग्रेज स्रोत से डेटा अंतर्ग्रहण कर रहा है, और abandond_orders देखें जो रेडपांडा विषय से डेटा को एक साथ अंतर्ग्रहण कर रहा है।
आइए एक सिंक बनाएं जहां हम उपरोक्त भौतिक दृश्य का डेटा भेजेंगे:
CREATE SINK high_value_orders_sink
FROM high_value_orders
INTO KAFKA BROKER 'redpanda:9092' TOPIC 'high-value-orders-sink'
FORMAT AVRO USING
CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
अब अगर आप रेडपांडा कंटेनर से जुड़ते हैं और rpk topic consume . का उपयोग करते हैं आदेश, आप विषय से रिकॉर्ड पढ़ने में सक्षम होंगे।
हालांकि, फिलहाल, हम rpk . के साथ परिणामों का पूर्वावलोकन नहीं कर पाएंगे क्योंकि यह एवरो स्वरूपित है। रेडपांडा भविष्य में इसे लागू करने की सबसे अधिक संभावना है, लेकिन फिलहाल, हम वास्तव में प्रारूप की पुष्टि करने के लिए विषय को वापस मैटेरियलाइज़ में स्ट्रीम कर सकते हैं।
सबसे पहले, उस विषय का नाम प्राप्त करें जो स्वचालित रूप से उत्पन्न हुआ है:
SELECT topic FROM mz_kafka_sinks;
आउटपुट:
topic
-----------------------------------------------------------------
high-volume-orders-sink-u12-1637586945-13670686352905873426
विषय के नाम कैसे उत्पन्न होते हैं, इस बारे में अधिक जानकारी के लिए यहां दस्तावेज़ देखें।
फिर इस Redpanda विषय से एक नया भौतिक स्रोत बनाएँ:
CREATE MATERIALIZED SOURCE high_volume_orders_test
FROM KAFKA BROKER 'redpanda:9092' TOPIC ' high-volume-orders-sink-u12-1637586945-13670686352905873426'
FORMAT AVRO USING CONFLUENT SCHEMA REGISTRY 'https://redpanda:8081';
विषय का नाम तदनुसार बदलना सुनिश्चित करें!
अंत में, इस नए भौतिक दृष्टिकोण को क्वेरी करें:
SELECT * FROM high_volume_orders_test LIMIT 2;
अब जब आपके पास विषय में डेटा है, तो आप अन्य सेवाओं को इससे कनेक्ट कर सकते हैं और इसका उपभोग कर सकते हैं और फिर उदाहरण के लिए ईमेल या अलर्ट ट्रिगर कर सकते हैं।
मेटाबेस कैसे कनेक्ट करें
मेटाबेस इंस्टेंस को एक्सेस करने के लिए https://localhost:3030 . पर जाएं यदि आप स्थानीय रूप से डेमो चला रहे हैं या https://your_server_ip:3030 यदि आप सर्वर पर डेमो चला रहे हैं। फिर मेटाबेस सेटअप को पूरा करने के लिए चरणों का पालन करें।
डेटा के स्रोत के रूप में मटेरियलाइज़ का चयन करना सुनिश्चित करें।
एक बार तैयार हो जाने पर आप अपने डेटा की कल्पना उसी तरह कर पाएंगे जैसे आप एक मानक PostgreSQL डेटाबेस के साथ करते हैं।
डेमो को कैसे रोकें
सभी सेवाओं को रोकने के लिए, निम्न आदेश चलाएँ:
docker-compose down
निष्कर्ष
जैसा कि आप देख सकते हैं, यह एक बहुत ही सरल उदाहरण है कि कैसे मटेरियलाइज़ का उपयोग किया जाए। आप विभिन्न स्रोतों से डेटा को अंतर्ग्रहण करने के लिए मटेरियलाइज़ का उपयोग कर सकते हैं और फिर इसे विभिन्न गंतव्यों पर स्ट्रीम कर सकते हैं।
सहायक संसाधन:
CREATE SOURCE: PostgreSQLCREATE SOURCECREATE VIEWSSELECT