यह काफी आम समस्या है।
सादा B-Tree इस तरह के प्रश्नों के लिए अनुक्रमणिकाएँ अच्छी नहीं हैं:
SELECT measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
दी गई सीमाओं के भीतर मूल्यों को खोजने के लिए एक सूचकांक अच्छा है, जैसे:
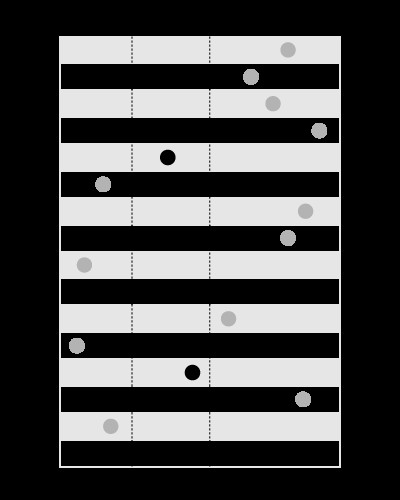
, लेकिन इस तरह दिए गए मान वाली सीमाओं को खोजने के लिए नहीं:
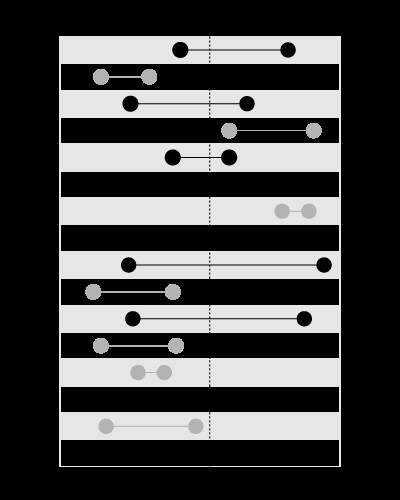
मेरे ब्लॉग का यह लेख समस्या को और विस्तार से बताता है:
(नेस्टेड सेट मॉडल समान प्रकार के विधेय से संबंधित है)।
आप इंडेक्स को time . पर बना सकते हैं , इस तरह intervals शामिल होने में अग्रणी होगा, नेस्टेड लूप के अंदर रेंज किए गए समय का उपयोग किया जाएगा। इसके लिए time . पर छँटाई की आवश्यकता होगी ।
आप intervals . पर एक स्थानिक अनुक्रमणिका बना सकते हैं (MySQL . में उपलब्ध है MyISAM . का उपयोग करना स्टोरेज) जिसमें start . शामिल होगा और end एक ज्यामिति स्तंभ में। इस तरह, measures शामिल होने में नेतृत्व कर सकते हैं और किसी सॉर्टिंग की आवश्यकता नहीं होगी।
हालांकि, स्थानिक सूचकांक अधिक धीमे होते हैं, इसलिए यह केवल तभी प्रभावी होगा जब आपके पास कुछ उपाय होंगे लेकिन कई अंतराल होंगे।
चूंकि आपके पास कुछ अंतराल हैं लेकिन कई उपाय हैं, बस सुनिश्चित करें कि आपके पास measures.time पर एक अनुक्रमणिका है :
CREATE INDEX ix_measures_time ON measures (time)
अपडेट करें:
परीक्षण के लिए यहां एक नमूना स्क्रिप्ट है:
BEGIN
DBMS_RANDOM.seed(20091223);
END;
/
CREATE TABLE intervals (
entry_time NOT NULL,
exit_time NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level,
TO_DATE('23.12.2009', 'dd.mm.yyyy') - level + DBMS_RANDOM.value
FROM dual
CONNECT BY
level <= 1500
/
CREATE UNIQUE INDEX ux_intervals_entry ON intervals (entry_time)
/
CREATE TABLE measures (
time NOT NULL,
measure NOT NULL
)
AS
SELECT TO_DATE('23.12.2009', 'dd.mm.yyyy') - level / 720,
CAST(DBMS_RANDOM.value * 10000 AS NUMBER(18, 2))
FROM dual
CONNECT BY
level <= 1080000
/
ALTER TABLE measures ADD CONSTRAINT pk_measures_time PRIMARY KEY (time)
/
CREATE INDEX ix_measures_time_measure ON measures (time, measure)
/
यह प्रश्न:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_NL(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
NESTED LOOPS . का उपयोग करता है और 1.7 . में लौटता है सेकंड।
यह प्रश्न:
SELECT SUM(measure), AVG(time - TO_DATE('23.12.2009', 'dd.mm.yyyy'))
FROM (
SELECT *
FROM (
SELECT /*+ ORDERED USE_MERGE(intervals measures) */
*
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time
)
WHERE rownum <= 500000
)
MERGE JOIN . का उपयोग करता है और मुझे 5 . के बाद इसे रोकना पड़ा मिनट।
अपडेट 2:
आपको शायद इस तरह के संकेत का उपयोग करके इंजन को सही तालिका क्रम का उपयोग करने के लिए मजबूर करने की आवश्यकता होगी:
SELECT /*+ LEADING (intervals) USE_NL(intervals, measures) */
measures.measure as measure,
measures.time as time,
intervals.entry_time as entry_time,
intervals.exit_time as exit_time
FROM intervals
JOIN measures
ON measures.time BETWEEN intervals.entry_time AND intervals.exit_time
ORDER BY
time ASC
Oracle का ऑप्टिमाइज़र यह देखने के लिए पर्याप्त स्मार्ट नहीं है कि अंतराल प्रतिच्छेद न करें। इसलिए यह संभवत:measures . का उपयोग करेगा एक अग्रणी तालिका के रूप में (जो कि एक बुद्धिमान निर्णय होगा जो अंतराल को प्रतिच्छेद करना चाहिए)।
अपडेट 3:
WITH splits AS
(
SELECT /*+ MATERIALIZE */
entry_range, exit_range,
exit_range - entry_range + 1 AS range_span,
entry_time, exit_time
FROM (
SELECT TRUNC((entry_time - TO_DATE(1, 'J')) * 2) AS entry_range,
TRUNC((exit_time - TO_DATE(1, 'J')) * 2) AS exit_range,
entry_time,
exit_time
FROM intervals
)
),
upper AS
(
SELECT /*+ MATERIALIZE */
MAX(range_span) AS max_range
FROM splits
),
ranges AS
(
SELECT /*+ MATERIALIZE */
level AS chunk
FROM upper
CONNECT BY
level <= max_range
),
tiles AS
(
SELECT /*+ MATERIALIZE USE_MERGE (r s) */
entry_range + chunk - 1 AS tile,
entry_time,
exit_time
FROM ranges r
JOIN splits s
ON chunk <= range_span
)
SELECT /*+ LEADING(t) USE_HASH(m t) */
SUM(LENGTH(stuffing))
FROM tiles t
JOIN measures m
ON TRUNC((m.time - TO_DATE(1, 'J')) * 2) = tile
AND m.time BETWEEN t.entry_time AND t.exit_time
यह क्वेरी समय अक्ष को श्रेणियों में विभाजित करती है और HASH JOIN . का उपयोग करती है बाद में ठीक फ़िल्टरिंग के साथ, श्रेणी मानों पर उपायों और टाइमस्टैम्प में शामिल होने के लिए।
यह कैसे काम करता है, इस बारे में अधिक विस्तृत स्पष्टीकरण के लिए मेरे ब्लॉग में इस लेख को देखें: