मैं इंडेक्स के लिए क्लस्टरिंग फैक्टर (सीएफ) के बारे में आज एमओएससी मंचों पर एक पोस्ट देख रहा था। सीएफ के बारे में बात करते समय एक बात जो लोग भूल जाते हैं, वह यह है कि जब डीबीए एक इंडेक्स के लिए सीएफ को बेहतर बनाने के लिए कुछ रीऑर्ग गतिविधि कर सकता है, तो यह संभावित रूप से उसी टेबल के लिए एक और इंडेक्स की कीमत पर आएगा। इस उदाहरण पर विचार करें जो मैंने उस सूत्र में प्रदान किया था।
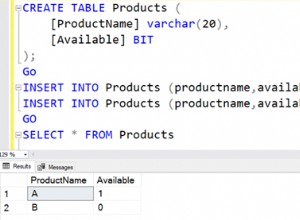
यहां मेरे पास दो इंडेक्स वाली एक टेबल है। यह मेरी स्कीमा में एकमात्र तालिका है। एक इंडेक्स (IDX2) का CF दूसरे (IDX1) की तुलना में बहुत अधिक होता है।
SQL> select index_name,clustering_factor from user_indexes;
INDEX_NAME CLUSTERING_FACTOR --------------- ----------------- MY_TAB_IDX2 135744 MY_TAB_IDX1 2257
डीबीए इस मुद्दे को "ठीक" करना चाहता है। DBA IDX2 के CF को कम करना चाहता है। ऐसा करने का सबसे अच्छा तरीका है कि डेटा को तालिका से बाहर निकालना और फिर वापस सम्मिलित करना, कॉलम के आधार पर क्रमबद्ध IDX2 पर बनाया गया है।
SQL> create table my_tab_temp as select * from my_tab;
Table created.
SQL> truncate table my_tab;
Table truncated.
SQL> insert into my_tab select * from my_tab_temp order by pk_id;
135795 rows created.
SQL> commit;
Commit complete.
SQL> exec dbms_stats.gather_table_stats(ownname=>USER,tabname=>'MY_TAB',cascade=>TRUE);
PL/SQL procedure successfully completed.
SQL> select index_name,clustering_factor from user_indexes;
INDEX_NAME CLUSTERING_FACTOR --------------- ----------------- MY_TAB_IDX2 2537 MY_TAB_IDX1 135747
अब IDX2 के लिए CF में निश्चित रूप से सुधार हुआ है। लेकिन IDX1 पर CF को देखें। यह बहुत खराब हो गया। वास्तव में, ऐसा लगता है कि दो इंडेक्स सीएफ मूल्यों को फ़्लिप कर चुके हैं। अगर मैं इस बार IDX1 कॉलम (स्तंभों) द्वारा ऑर्डर करने के लिए एंथोर रीऑर्ग का प्रयास करता हूं, तो CF मान फिर से फ़्लिप हो जाएंगे।
इस कहानी का नैतिक यह है कि कोई इस बात की गारंटी नहीं दे सकता कि एक इंडेक्स के लिए CF में सुधार करने से उस टेबल के दूसरे इंडेक्स पर नकारात्मक प्रभाव नहीं पड़ेगा।