हम Oracle डेटाबेस को EC2 इंस्टेंस से प्रबंधित सेवा RDS में माइग्रेट करने की खोज कर रहे हैं। चार लेखों में से पहले में, "AWS EC2 से AWS RDS, भाग 1 में Oracle डेटाबेस माइग्रेट करना," हमने EC2 और RDS पर डेटाबेस इंस्टेंस बनाए। दूसरे लेख में, "AWS EC2 से AWS RDS, भाग 2 में Oracle डेटाबेस माइग्रेट करना," हमने डेटाबेस माइग्रेशन के लिए एक IAM उपयोगकर्ता बनाया और माइग्रेट करने के लिए एक डेटाबेस तालिका भी बनाई। केवल दूसरे लेख में, हमने एक प्रतिकृति उदाहरण और प्रतिकृति समापन बिंदु बनाए। तीसरे लेख में, "AWS EC2 से AWS RDS, भाग 3 में Oracle डेटाबेस माइग्रेट करना," हमने मौजूदा परिवर्तनों को माइग्रेट करने के लिए एक माइग्रेशन टास्क बनाया। इस निरंतरता लेख में, हम चल रहे परिवर्तनों को डेटा में माइग्रेट करेंगे। इस लेख में निम्नलिखित भाग हैं:
- चल रहे परिवर्तनों को माइग्रेट करने के लिए एक प्रतिकृति कार्य बनाना और चलाना
- पूरक लॉगिंग जोड़ना
- EC2 पर Oracle डेटाबेस इंस्टेंस में तालिका जोड़ना
- टेबल डेटा जोड़ना
- प्रतिकृति डेटाबेस तालिका की खोज
- डेटा छोड़ना और फिर से लोड करना
- कार्य को रोकना और शुरू करना
- डेटाबेस हटाना
- निष्कर्ष
चल रहे परिवर्तनों को माइग्रेट करने के लिए एक प्रतिकृति कार्य बनाना और चलाना
निम्नलिखित उप-अनुभागों में, हम चल रहे परिवर्तनों को दोहराने के लिए एक कार्य तैयार करेंगे। चल रहे प्रतिकृति को प्रदर्शित करने के लिए, हम पहले कार्य शुरू करेंगे और बाद में एक तालिका बनाएंगे और डेटा जोड़ेंगे। तालिका छोड़ें DVOHRA.WLSLOG , जैसा कि चित्र एक में दिखाया गया है; हम चल रहे प्रतिकृति को प्रदर्शित करने के लिए उसी तालिका का निर्माण करेंगे।

चित्र 1: ड्रॉपिंग टेबल DVOHRA.WLSLOG
पूरक लॉगिंग जोड़ना
डेटाबेस माइग्रेशन सेवा परिवर्तन डेटा कैप्चर (सीडीसी) को सक्षम करने के लिए पूरक लॉगिंग को सक्षम करने की आवश्यकता है जिसका उपयोग चल रहे परिवर्तनों को दोहराने के लिए किया जाता है। पूरक लॉगिंग जानकारी संग्रहीत करने की प्रक्रिया है जिसके बारे में एक तालिका में डेटा की पंक्तियों में बदलाव आया है। जब भी किसी टेबल पर कोई अपडेट किया जाता है, तो पूरक लॉगिंग फिर से लॉग फ़ाइलों में पूरक या अतिरिक्त कॉलम डेटा जोड़ता है। जो कॉलम बदल गए हैं उन्हें एक पहचान कुंजी के साथ फिर से लॉग फाइलों में पूरक डेटा के रूप में दर्ज किया गया है, जो प्राथमिक कुंजी या अद्वितीय सूचकांक हो सकता है। यदि किसी तालिका में प्राथमिक कुंजी या अद्वितीय अनुक्रमणिका नहीं है, तो डेटा की एक पंक्ति को विशिष्ट रूप से पहचानने के लिए सभी स्केलर कॉलम रीडो लॉग फ़ाइलों में रिकॉर्ड किए जाते हैं, जो रीडो लॉग फ़ाइलों को आकार में बड़ा बना सकता है। Oracle डाटाबेस निम्नलिखित प्रकार के पूरक लॉगिंग का समर्थन करता है:
- न्यूनतम पूरक लॉगिंग: DML परिवर्तनों के लिए LogMiner द्वारा आवश्यक डेटा की केवल न्यूनतम मात्रा रीडो लॉग फ़ाइलों में दर्ज की जाती है।
- डेटाबेस स्तर की पहचान कुंजी लॉगिंग: विभिन्न प्रकार के डेटाबेस स्तर की पहचान कुंजी लॉगिंग समर्थित हैं- सभी, प्राथमिक कुंजी, अद्वितीय और विदेशी कुंजी। ALL स्तर के साथ, सभी कॉलम (LOBs, Longs और ADTs को छोड़कर) को रीडो लॉग फाइल में रिकॉर्ड किया जाता है। प्राथमिक कुंजी के लिए, जब प्राथमिक कुंजी वाली पंक्ति को अद्यतन किया जाता है, तो केवल प्राथमिक कुंजी कॉलम को फिर से लॉग फ़ाइलों में संग्रहीत किया जाता है; यह आवश्यक नहीं है कि प्राथमिक कुंजी कॉलम अपडेट किया जाए। जब कोई भी लाल लॉग फ़ाइल अपडेट की जाती है, तो FOREIGN KEY प्रकार केवल रीडो लॉग फ़ाइलों में एक पंक्ति की विदेशी कुंजियों को संग्रहीत करता है। जब यूनिक कंपोजिट कुंजी या बिटमैप इंडेक्स में कोई भी कॉलम बदल जाता है, तो UNIQUE प्रकार केवल कॉलम को एक यूनिक कंपोजिट की या बिटमैप इंडेक्स में स्टोर करता है।
- तालिका स्तरीय पूरक लॉगिंग: तालिका स्तर पर निर्दिष्ट करता है कि कौन से कॉलम फिर से लॉग फ़ाइलों में संग्रहीत हैं। तालिका-स्तरीय पहचान कुंजी लॉगिंग डेटाबेस-स्तरीय पहचान कुंजी लॉगिंग के समान स्तरों का समर्थन करती है; सभी, प्राथमिक कुंजी, अद्वितीय और विदेशी कुंजी। तालिका स्तर पर, उपयोगकर्ता द्वारा परिभाषित पूरक लॉग समूह भी समर्थित हैं, जो उपयोगकर्ता को यह परिभाषित करने देता है कि कौन से कॉलम पूरक रूप से लॉग किए जाने हैं। उपयोगकर्ता परिभाषित पूरक लॉग समूह सशर्त या बिना शर्त हो सकते हैं।
चल रहे प्रतिकृति के लिए, हमें सभी स्तंभों के लिए न्यूनतम पूरक लॉगिंग और तालिका स्तर के पूरक लॉगिंग सेट करने की आवश्यकता है।
SQL*Plus में, न्यूनतम पूरक लॉगिंग सेट करने के लिए निम्न कथन चलाएँ:
ALTER DATABASE ADD SUPPLEMENTAL LOG DATA;
आउटपुट इस प्रकार है:
SQL> ALTER DATABASE ADD SUPPLEMENTAL LOG DATA; Database altered.
न्यूनतम पूरक लॉगिंग की स्थिति जानने के लिए, निम्न कथन चलाएँ। और, यदि आउटपुट में SUPPLEME कॉलम मान हाँ है, तो न्यूनतम पूरक लॉगिंग सक्षम है।
SQL> SELECT supplemental_log_data_min FROM v$database; SUPPLEME -------- YES
न्यूनतम पूरक लॉगिंग सेट करना और स्थिति आउटपुट सत्यापित करना चित्र 2 में दिखाया गया है।
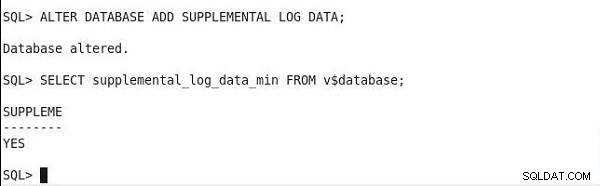
चित्र 2: न्यूनतम पूरक लॉगिंग सेट करना और सत्यापित करना
जब हम कार्य शुरू होने के बाद चल रहे प्रतिकृति को प्रदर्शित करने के लिए तालिका और तालिका डेटा जोड़ते हैं तो हम तालिका-स्तरीय पहचान कुंजी लॉगिंग भी सेट करेंगे। यदि हम कार्य बनाने और शुरू करने से पहले तालिका और तालिका डेटा जोड़ते हैं- हम चल रहे प्रतिकृति को प्रदर्शित करने में सक्षम नहीं होंगे।
चल रहे प्रतिकृति के लिए कार्य बनाने के लिए, कार्य बनाएं क्लिक करें , जैसा कि चित्र 3 में दिखाया गया है।

चित्र 3: कार्य>कार्य बनाएं
कार्य बनाएं . में विज़ार्ड, एक कार्य नाम और विवरण निर्दिष्ट करें, और प्रतिकृति उदाहरण, स्रोत समापन बिंदु और लक्ष्य समापन बिंदु का चयन करें, जैसा कि चित्र 4 में दिखाया गया है। माइग्रेशन प्रकार का चयन करें। के रूप में मौजूदा डेटा माइग्रेट करें और चल रहे परिवर्तनों को दोहराएं ।
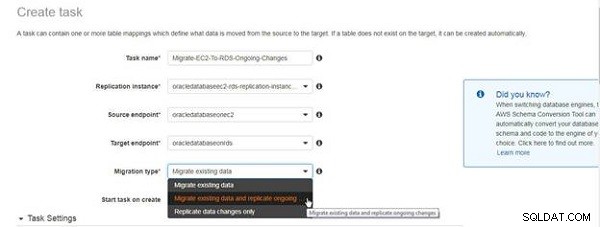
चित्र 4: चल रहे प्रतिकृति के लिए माइग्रेशन प्रकार का चयन करना
चित्र 5 में दिखाया गया एक संदेश इंगित करता है कि चल रहे प्रतिकृति के लिए पूरक लॉगिंग को सक्षम करने की आवश्यकता है। संदेश यह इंगित करने के लिए नहीं है कि पूरक लॉगिंग सक्षम नहीं की गई है, बल्कि केवल एक अनुस्मारक के रूप में है। हमने पहले ही पूरक लॉगिंग सक्षम कर दी है। चेकबॉक्स चुनें बनाने पर कार्य प्रारंभ करें ।
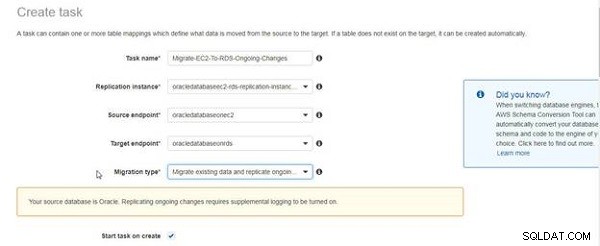
चित्र 5: चल रहे परिवर्तनों को दोहराने के लिए पूरक लॉगिंग आवश्यकता के बारे में संदेश
कार्य सेटिंग केवल मौजूदा डेटा को स्थानांतरित करने के लिए समान हैं (चित्र 6 देखें)।
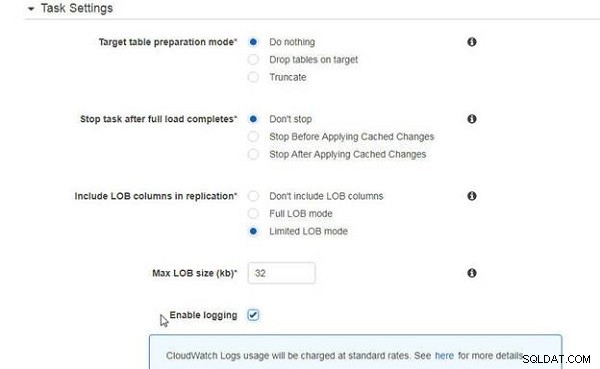
चित्र 6: कार्य सेटिंग
टेबल मैपिंग के लिए, कम से कम एक चयन नियम की आवश्यकता होती है। DVOHRA . में सभी तालिकाओं को शामिल करने के लिए चयन नियम जोड़ें तालिका, जैसा कि चित्र 7 में दिखाया गया है।
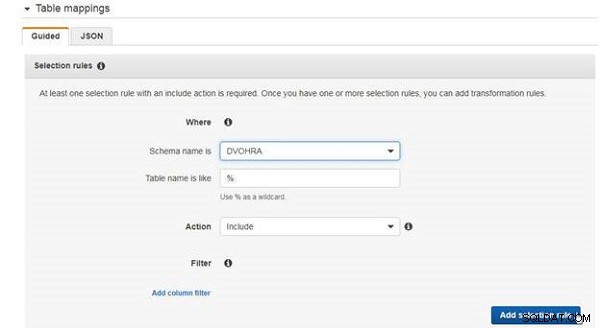
चित्र 7: चयन नियम जोड़ना
जोड़ा गया चयन नियम चित्र 8 में दिखाया गया है।
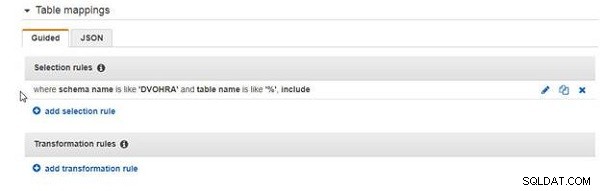
चित्र 8: चयन नियम
कार्य बनाएं क्लिक करें कार्य बनाने के लिए, जैसा कि चित्र 9 में दिखाया गया है।
चित्र 9: कार्य बनाएं
बनाना . के रूप में स्थिति के साथ एक नया कार्य जोड़ा जाता है , जैसा कि चित्र 10 में दिखाया गया है।

चित्र 10: स्थिति बनाने के साथ कार्य जोड़ा गया
जब सभी मौजूदा डेटा के लिए चयन और परिवर्तन नियम लागू कर दिए जाते हैं और डेटा माइग्रेट हो जाता है, तो कार्य की स्थिति लोड पूर्ण, प्रतिकृति जारी हो जाती है। (चित्र 11 देखें)।

चित्र 11: लोड पूर्ण, प्रतिकृति जारी है
तालिका आँकड़े टैब किसी तालिका को माइग्रेट या प्रतिकृति के रूप में सूचीबद्ध नहीं करता है, जैसा कि चित्र 12 में दिखाया गया है।
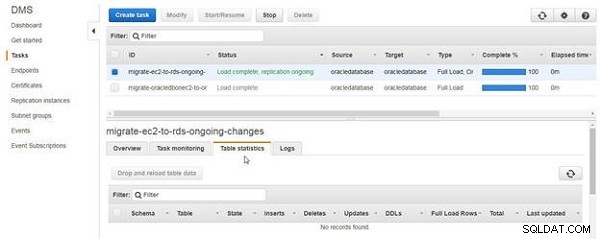
चित्र 12: तालिका आँकड़े
CloudWatch लॉग को एक्सप्लोर करने के लिए, लॉग . क्लिक करें टैब पर क्लिक करें और लिंक पर क्लिक करें, जैसा कि चित्र 13 में दिखाया गया है।
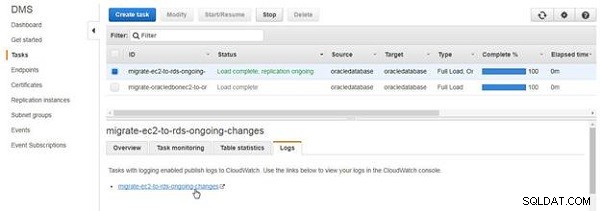
चित्र 13: लॉग्स
CloudWatch लॉग प्रदर्शित होते हैं, जैसा कि चित्र 14 में दिखाया गया है। लॉग में अंतिम प्रविष्टि प्रतिकृति शुरू करने के बारे में है। मौजूदा डेटा, यदि कोई हो, लोड करने के बाद प्रतिकृति चालू कार्य समाप्त नहीं होता है, लेकिन चलता रहता है।
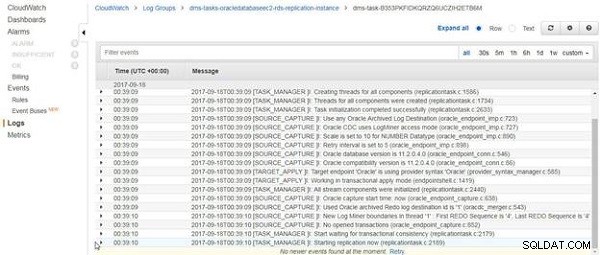
चित्र 14: CloudWatch लॉग
EC2 पर Oracle डेटाबेस इंस्टेंस में तालिका जोड़ना
इसके बाद, एक तालिका बनाएं और चल रहे प्रतिकृति को प्रदर्शित करने के लिए तालिका डेटा जोड़ें। निम्नलिखित दो कथनों को एक साथ चलाएँ ताकि तालिका बनाते समय तालिका स्तर की पूरक लॉगिंग सेट हो जाए। स्कीमा को अलग बनाने के लिए स्क्रिप्ट में बदलाव करें।
CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY, category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns;
तालिका बनाते समय तालिका स्तर की पूरक लॉगिंग सेट हो जाती है।
SQL> CREATE TABLE DVOHRA.wlslog(time_stamp VARCHAR2(255) PRIMARY KEY,category VARCHAR2(255),type VARCHAR2(255),servername VARCHAR2(255),code VARCHAR2(255),msg VARCHAR2(255)); alter table DVOHRA.WLSLOG add supplemental log data (ALL) columns; Table created. SQL> Table altered.
आउटपुट SQL*प्लस में चित्र 15 में दिखाया गया है।
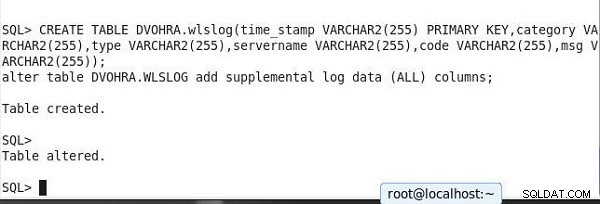
चित्र 15: तालिका बनाना और पूरक लॉगिंग सेट करना
अभी तक, हमने केवल तालिका बनाई है, और कोई तालिका डेटा नहीं जोड़ा है। तालिका के लिए DDL माइग्रेट हो जाता है, जैसा कि चित्र 16 में तालिका आँकड़ों द्वारा दर्शाया गया है।
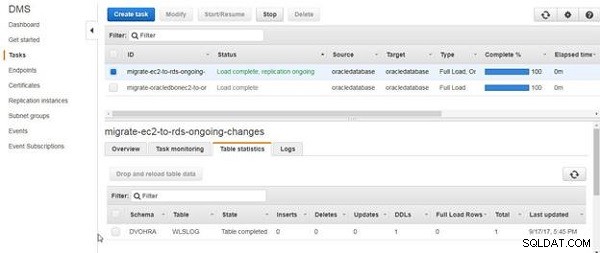
चित्र 16: टेबल माइग्रेट के लिए डीडीएल
टेबल डेटा जोड़ना
इसके बाद, बनाई गई तालिका में डेटा जोड़ने के लिए निम्न SQL स्क्रिप्ट चलाएँ। स्कीमा को अलग बनाने के लिए स्क्रिप्ट में बदलाव करें।
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:16-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000365','Server
state changed to STANDBY');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:17-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to STARTING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,
code,msg) VALUES('Apr-8-2014-7:06:18-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to ADMIN');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:19-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RESUMING');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:20-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000361','Started WebLogic
AdminServer');
INSERT INTO DVOHRA.wlslog(time_stamp,category,type,servername,code,
msg) VALUES('Apr-8-2014-7:06:21-PM-PDT','Notice',
'WebLogicServer','AdminServer','BEA-000365','Server state
changed to RUNNING');
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
SQL>
1 row created.
इसके बाद, कमिट स्टेटमेंट चलाएँ।
SQL> COMMIT; Commit complete.
प्रतिकृति डेटाबेस तालिका को एक्सप्लोर करना
तालिका आँकड़े सम्मिलित डेटा को जोड़े गए डेटा की पंक्तियों की संख्या के रूप में सूचीबद्ध करते हैं, जैसा कि चित्र 17 में दिखाया गया है।
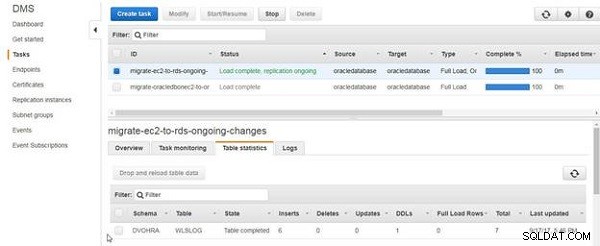
चित्र 17: तालिका आँकड़े सूची 6 निवेशन
चल रहे परिवर्तनों को दोहराने के बाद कार्य चलना जारी है। डेटा की एक और पंक्ति जोड़ें।
SQL> INSERT INTO DVOHRA.wlslog(time_stamp,category,type,
servername,code,msg) VALUES('Apr-8-2014-7:06:22-PM-PDT',
'Notice','WebLogicServer','AdminServer','BEA-000360','Server
started in RUNNING mode');
1 row created.
SQL> COMMIT;
Commit complete.
SQL>
डेटा रीफ़्रेश करें क्लिक करें सर्वर से, जैसा कि चित्र 18 में दिखाया गया है।
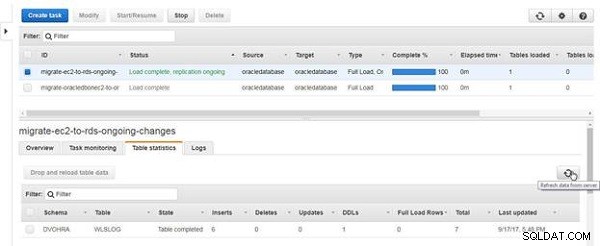
चित्र 18: सर्वर से डेटा ताज़ा करें
तालिका के आंकड़ों में निवेशन की कुल संख्या 7 हो जाती है, जैसा कि चित्र 19 में दिखाया गया है।
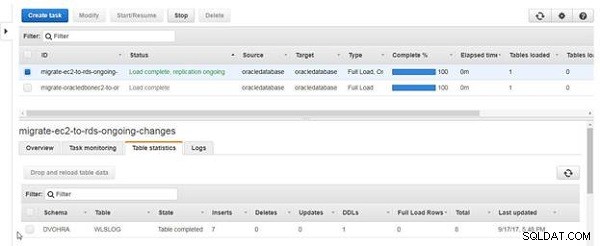
चित्र 19: तालिका आँकड़े 7 के रूप में निवेशन के साथ
डेटा छोड़ना और फिर से लोड करना
तालिका डेटा ड्रॉप और पुनः लोड करने के लिए, तालिका डेटा छोड़ें और पुनः लोड करें click क्लिक करें , जैसा कि चित्र 20 में दिखाया गया है।
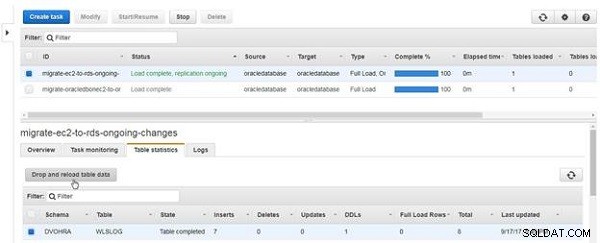
चित्र 20: तालिका डेटा ड्रॉप और पुनः लोड करें
सर्वर से डेटा रीफ़्रेश करें Click क्लिक करें (चित्र 21 देखें)।
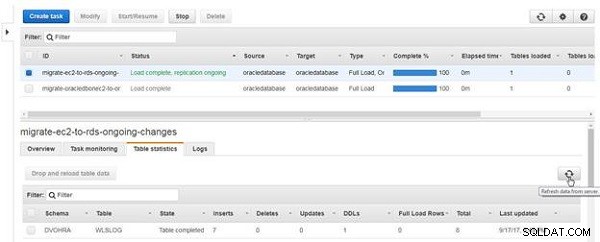
चित्र 21: सर्वर से डेटा ताज़ा करें
आइकन और राज्य तालिका के लिए कॉलम इंगित करता है कि तालिका को पुनः लोड किया जा रहा है, जैसा कि चित्र 22 में दिखाया गया है।
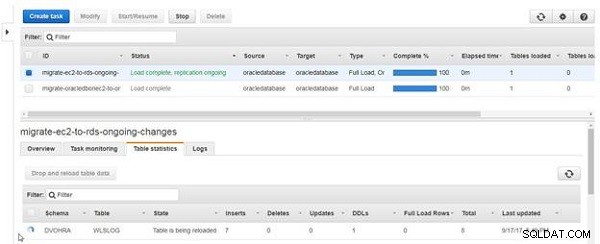
चित्र 22: तालिका पुनः लोड की जा रही है
जब टेबल रीलोड पूरा हो जाता है, तो टेबल स्टेट कॉलम टेबल पूरा हो जाता है , जैसा कि चित्र 23 में दिखाया गया है। तालिका डेटा को पुनः लोड करने के बाद, पूर्ण लोड पंक्तियाँ 7 का मान प्रदर्शित करता है और निवेशन 0 है क्योंकि एक पुनः लोड चल रही प्रतिकृति नहीं है, बल्कि एक पूर्ण भार है।
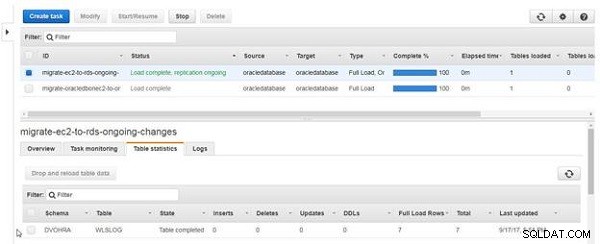
चित्र 23: टेबल रीलोड पूरा हुआ
क्योंकि तालिका डेटा गिरा दिया गया है और पुनः लोड किया गया है और स्रोत तालिका डेटा नहीं बदला है, CloudWatch लॉग में एक संदेश शामिल है "स्रोत डेटाबेस से कुछ परिवर्तनों का लक्ष्य डेटाबेस पर लागू होने पर कोई प्रभाव नहीं पड़ा।", जैसा कि चित्र 24 में दिखाया गया है। पी>
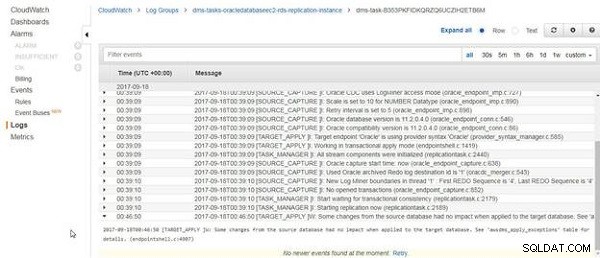
चित्र 24: लक्ष्य डेटाबेस पर लागू होने पर स्रोत डेटाबेस से कुछ परिवर्तनों का कोई प्रभाव नहीं पड़ा
जब DVOHRA.wlslog . का पुनः लोड किया जाता है तालिका पूर्ण हो गई है, संदेश "तालिका DVOHRA.wlslog के लिए लोड समाप्त हो गया है। प्राप्त 7 पंक्तियाँ" प्रदर्शित होती हैं, जैसा कि चित्र 25 में दिखाया गया है।
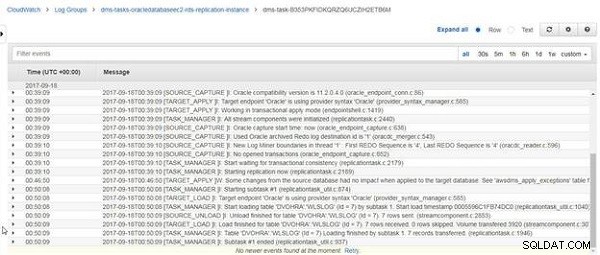
चित्र 25: CloudWatch लॉग संदेश लोड होने के पूरा होने के लिए
कार्य को रोकना और प्रारंभ करना
एक प्रकार का कार्य जिसमें चल रही प्रतिकृति शामिल है, तब तक अपने आप नहीं रुकता जब तक कि कोई त्रुटि न हो। कार्य को रोकने के लिए, रोकें . क्लिक करें (चित्र 26 देखें)।
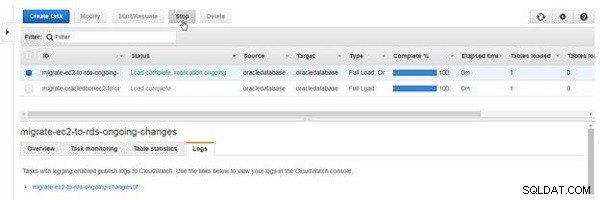
चित्र 26: टास्क रोकना
कार्य रोकें . में संवाद, रोकें . क्लिक करें , जैसा कि चित्र 27 में दिखाया गया है।
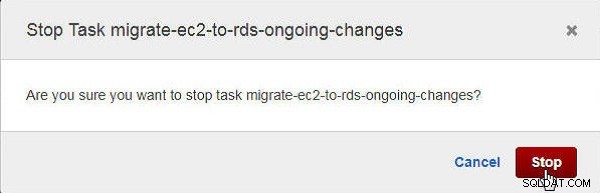
चित्र 27: किसी कार्य को रोकने के लिए पुष्टिकरण संवाद
कार्य की स्थिति रोकना . बन जाती है , जैसा कि चित्र 28 में दिखाया गया है।
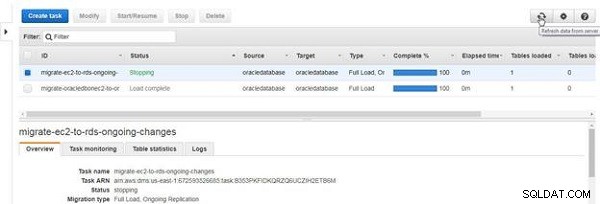
चित्र 28: किसी कार्य को रोकना
जब कोई कार्य रुक जाता है, तो स्थिति रोकी गई . हो जाती है , जैसा कि चित्र 29 में दिखाया गया है।
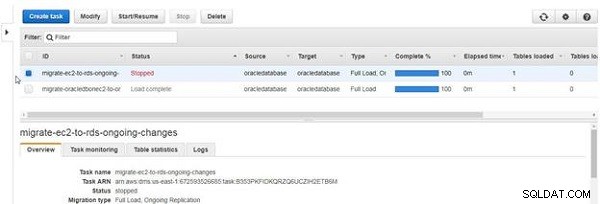
चित्र 29: कार्य रोक दिया गया
रुका हुआ कार्य प्रारंभ करने के लिए, प्रारंभ/फिर से शुरू करें click क्लिक करें , जैसा कि चित्र 30 में दिखाया गया है।
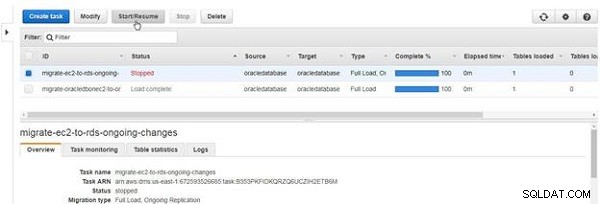
चित्र 30: कार्य शुरू करना या फिर से शुरू करना
कार्य प्रारंभ करें . में संवाद, प्रारंभ करें click क्लिक करें रुके हुए बिंदु से कार्य शुरू करने के लिए (चित्र 31 देखें)। दूसरा विकल्प कार्य को फिर से शुरू करना है।
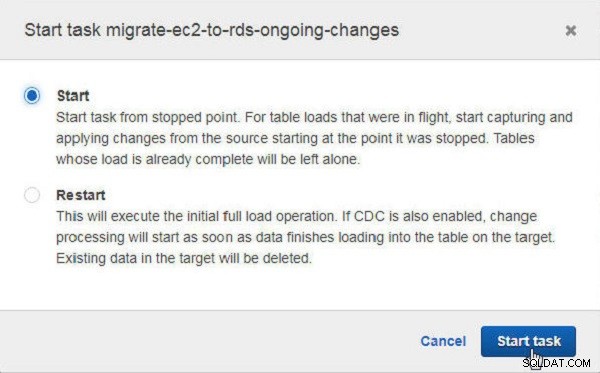
चित्र 31: रुकने के बाद टास्क शुरू करना
कार्य स्थिति प्रारंभ . हो जाती है , जैसा कि चित्र 32 में दिखाया गया है।

चित्र 32: कार्य प्रारंभ करना
जब मौजूदा डेटा का माइग्रेशन पूरा हो जाता है, तो कार्य स्थिति के साथ चलता रहता है जैसे लोड पूर्ण, प्रतिकृति जारी , जैसा कि चित्र 33 में दिखाया गया है।

चित्र 33: लोड पूर्ण, प्रतिकृति जारी है
डेटाबेस हटाना
RDS DB इंस्टेंस को इंस्टेंस एक्शन>डिलीट . के साथ हटाया जा सकता है आज्ञा। EC2 इंस्टेंस पर Oracle डेटाबेस को कार्रवाइयां>इंस्टेंस स्टेट>स्टॉप के साथ रोका जा सकता है , जैसा कि चित्र 34 में दिखाया गया है।

चित्र 34: EC2 इंस्टेंस को रोकना
निष्कर्ष
चार लेखों में, हमने Oracle डेटाबेस को AWS EC2 से AWS RDS में माइग्रेट करने पर चर्चा की।