"मैं डेटाबेस के भीतर डुप्लिकेट व्यक्ति-रिकॉर्ड के मिलान के लिए एक विश्वसनीय तरीका खोजने की कोशिश कर रहा हूं।"
काश ऐसी कोई बात नहीं होती। आप जिस अधिक से अधिक उम्मीद कर सकते हैं वह एक ऐसी प्रणाली है जिसमें संदेह के उचित तत्व हैं।
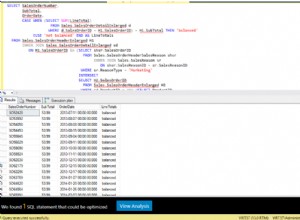
SQL> select n1
, n2
, soundex(n1) as sdx_n1
, soundex(n2) as sdx_n2
, utl_match.edit_distance_similarity(n1, n2) as ed
, utl_match.jaro_winkler_similarity(n1, n2) as jw
from t94
order by n1, n2
/
2 3 4 5 6 7 8 9
N1 N2 SDX_ SDX_ ED JW
-------------------- -------------------- ---- ---- ---------- ----------
MARK MARKIE M620 M620 67 93
MARK MARKS M620 M620 80 96
MARK MARKUS M620 M622 67 93
MARKY MARKIE M620 M620 67 89
MARSK MARKS M620 M620 60 95
MARX AMRX M620 A562 50 91
MARX M4RX M620 M620 75 85
MARX MARKS M620 M620 60 84
MARX MARSK M620 M620 60 84
MARX MAX M620 M200 75 93
MARX MRX M620 M620 75 92
11 rows selected.
SQL> SQL> SQL>
SOUNDEX का बड़ा फायदा यह है कि यह स्ट्रिंग को टोकन देता है। इसका मतलब है कि यह आपको कुछ देता है जिसे अनुक्रमित किया जा सकता है :जब बड़ी मात्रा में डेटा की बात आती है तो यह अविश्वसनीय रूप से मूल्यवान होता है। दूसरी ओर यह पुराना और कच्चा है। आसपास नए एल्गोरिदम हैं, जैसे मेटाफोन और डबल मेटाफोन। आपको Google के माध्यम से उनमें से PL/SQL लागू करने में सक्षम होना चाहिए।
स्कोरिंग का लाभ यह है कि वे कुछ हद तक अस्पष्टता की अनुमति देते हैं; ताकि आप सभी पंक्तियाँ पा सकें where name_score >= 90% . पेराई नुकसान यह है कि स्कोर सापेक्ष हैं और इसलिए आप उन्हें अनुक्रमित नहीं कर सकते। इस तरह की तुलना आपको बड़ी मात्रा में मार देती है।
इसका क्या अर्थ है:
- आपको रणनीतियों का मिश्रण चाहिए। कोई एकल एल्गोरिथम आपकी समस्या का समाधान नहीं करेगा।
- डेटा सफाई उपयोगी है। MARX बनाम MRX और M4RX के स्कोर की तुलना करें:नामों से संख्याओं को अलग करने से हिट दर में सुधार होता है।
- आप जल्दी से बड़ी संख्या में नाम नहीं बना सकते। यदि आप कर सकते हैं तो टोकनिंग और प्री-स्कोरिंग का प्रयोग करें। यदि आपके पास बहुत अधिक मंथन नहीं है तो कैशिंग का उपयोग करें। यदि आप इसे वहन कर सकते हैं तो विभाजन का उपयोग करें।
- उपनामों और विविधताओं का थिसॉरस बनाने के लिए Oracle टेक्स्ट (या समान) का उपयोग करें।
- Oracle 11g ने Oracle टेक्स्ट के लिए विशिष्ट नाम खोज कार्यक्षमता पेश की। और जानें।
- स्कोरिंग के लिए प्रामाणिक नामों की एक तालिका बनाएं और वास्तविक डेटा रिकॉर्ड को उससे लिंक करें।
- अन्य डेटा मानों का उपयोग करें, विशेष रूप से जन्म तिथि जैसे इंडेक्स करने योग्य, बड़ी संख्या में नामों को पूर्व-फ़िल्टर करने या प्रस्तावित मैचों में विश्वास बढ़ाने के लिए।
- ध्यान रखें कि अन्य डेटा मान अपनी समस्याओं के साथ आते हैं:क्या कोई व्यक्ति 31/01/11 को ग्यारह महीने का या अस्सी वर्ष का है?
- याद रखें कि नाम मुश्किल हैं, खासकर जब आपको उन नामों पर विचार करना होता है जिन्हें रोमानीकृत किया गया है:मोअम्मर खदाफी (रोमन वर्णमाला में) की वर्तनी के चार सौ से अधिक विभिन्न तरीके हैं - और यहां तक कि Google भी इस बात पर सहमत नहीं हो सकता है कि कौन सा संस्करण है सबसे प्रामाणिक.
मेरे अनुभव में टोकन को जोड़ना (प्रथम नाम, अंतिम नाम) एक मिश्रित आशीर्वाद है। यह कुछ समस्याओं को हल करता है (जैसे कि क्या सड़क का नाम पता पंक्ति 1 या पता पंक्ति 2 में दिखाई देता है) लेकिन अन्य समस्याओं का कारण बनता है:ओलिवर बनाम ओलिवर, ग्राहम बनाम ग्राहम, ओलिवर बनाम ग्राहम और ग्राहम बनाम ओलिवर स्कोरिंग के खिलाफ ग्राहम ओलिवर बनाम ओलिवर ग्राहम स्कोरिंग पर विचार करें। .
आप जो कुछ भी करते हैं, आप अभी भी झूठी सकारात्मक और छूटे हुए हिट के साथ समाप्त होंगे। टाइपो के खिलाफ कोई एल्गोरिदम सबूत नहीं है (हालांकि जारो विंकलर ने MARX बनाम AMRX के साथ बहुत अच्छा किया)।