हाल ही में, मुझे मेरे मित्र एरलैंड सोमरस्कोग द्वारा एक नई द्वीप चुनौती से परिचित कराया गया था। यह एक सार्वजनिक डेटाबेस फ़ोरम के एक प्रश्न पर आधारित है। प्रसिद्ध तकनीकों का उपयोग करते समय चुनौती को संभालना जटिल नहीं है, जो मुख्य रूप से विंडो फ़ंक्शंस को नियोजित करती है। हालांकि, इन तकनीकों को एक सहायक सूचकांक की उपस्थिति के बावजूद स्पष्ट छँटाई की आवश्यकता होती है। यह समाधानों की मापनीयता और प्रतिक्रिया समय को प्रभावित करता है। चुनौतियों का शौक, मैंने योजना में स्पष्ट सॉर्ट ऑपरेटरों की संख्या को कम करने के लिए एक समाधान खोजने के लिए निर्धारित किया, या बेहतर अभी तक, उन लोगों की आवश्यकता को पूरी तरह से समाप्त कर दिया। और मुझे ऐसा समाधान मिला।
मैं चुनौती का एक सामान्यीकृत रूप प्रस्तुत करके शुरू करूँगा। फिर मैं ज्ञात तकनीकों के आधार पर दो समाधान दिखाऊंगा, उसके बाद नया समाधान। अंत में, मैं विभिन्न समाधानों के प्रदर्शन की तुलना करूँगा।
मेरा सुझाव है कि आप मेरा कार्यान्वयन करने से पहले एक समाधान खोजने का प्रयास करें।
चुनौती
मैं एरलैंड के मूल द्वीप चुनौती का एक सामान्यीकृत रूप प्रस्तुत करूंगा।
T1 नामक तालिका बनाने के लिए निम्न कोड का उपयोग करें और इसे नमूना डेटा के एक छोटे से सेट से भरें:
SET NOCOUNT ON;
USE tempdb;
DROP TABLE IF EXISTS dbo.T1
CREATE TABLE dbo.T1
(
grp VARCHAR(10) NOT NULL,
ord INT NOT NULL,
val VARCHAR(10) NOT NULL,
CONSTRAINT PK_T1 PRIMARY KEY(grp, ord)
);
GO
INSERT INTO dbo.T1(grp, ord, val) VALUES
('Group A', 1002, 'Y'),
('Group A', 1003, 'Y'),
('Group A', 1005, 'Y'),
('Group A', 1007, 'N'),
('Group A', 1011, 'N'),
('Group A', 1013, 'N'),
('Group A', 1017, 'Y'),
('Group A', 1019, 'Y'),
('Group A', 1023, 'N'),
('Group A', 1029, 'N'),
('Group B', 1001, 'X'),
('Group B', 1002, 'X'),
('Group B', 1003, 'Z'),
('Group B', 1005, 'Z'),
('Group B', 1008, 'Z'),
('Group B', 1013, 'Z'),
('Group B', 1021, 'Y'),
('Group B', 1034, 'Y'); चुनौती इस प्रकार है:
कॉलम जीआरपी के आधार पर विभाजन को मानते हुए और कॉलम ऑर्ड के आधार पर ऑर्डर करते हुए, वैल कॉलम में समान मान के साथ पंक्तियों के प्रत्येक लगातार समूह के भीतर 1 से शुरू होने वाली अनुक्रमिक पंक्ति संख्याओं की गणना करें। नमूना डेटा के दिए गए छोटे सेट के लिए वांछित परिणाम निम्नलिखित है:
grp ord val seqno -------- ----- ---- ------ Group A 1002 Y 1 Group A 1003 Y 2 Group A 1005 Y 3 Group A 1007 N 1 Group A 1011 N 2 Group A 1013 N 3 Group A 1017 Y 1 Group A 1019 Y 2 Group A 1023 N 1 Group A 1029 N 2 Group B 1001 X 1 Group B 1002 X 2 Group B 1003 Z 1 Group B 1005 Z 2 Group B 1008 Z 3 Group B 1013 Z 4 Group B 1021 Y 1 Group B 1034 Y 2
समग्र कुंजी (जीआरपी, ऑर्ड) के आधार पर प्राथमिक कुंजी बाधा की परिभाषा पर ध्यान दें, जिसके परिणामस्वरूप एक ही कुंजी के आधार पर क्लस्टर इंडेक्स होता है। यह अनुक्रमणिका जीआरपी द्वारा विभाजित और ऑर्ड द्वारा आदेशित विंडो कार्यों का संभावित रूप से समर्थन कर सकती है।
अपने समाधान के प्रदर्शन का परीक्षण करने के लिए, आपको बड़ी मात्रा में नमूना डेटा के साथ तालिका को पॉप्युलेट करना होगा। हेल्पर फंक्शन GetNums बनाने के लिए निम्नलिखित कोड का उपयोग करें:
CREATE FUNCTION dbo.GetNums(@low AS BIGINT = 1, @high AS BIGINT)
RETURNS TABLE
AS
RETURN
WITH
L0 AS ( SELECT 1 AS c
FROM (VALUES(1),(1),(1),(1),(1),(1),(1),(1),
(1),(1),(1),(1),(1),(1),(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L3 )
SELECT TOP(@high - @low + 1)
rownum AS rn,
@high + 1 - rownum AS op,
@low - 1 + rownum AS n
FROM Nums
ORDER BY rownum;
GO समूहों की संख्या, प्रति समूह पंक्तियों की संख्या और अपनी इच्छानुसार अलग-अलग मानों की संख्या का प्रतिनिधित्व करने वाले मापदंडों को बदलने के बाद, T1 को पॉप्युलेट करने के लिए निम्नलिखित कोड का उपयोग करें:
DECLARE
@numgroups AS INT = 1000,
@rowspergroup AS INT = 10000, -- test with 1000 to 10000 here
@uniquevalues AS INT = 5;
ALTER TABLE dbo.T1 DROP CONSTRAINT PK_T1;
TRUNCATE TABLE dbo.T1;
INSERT INTO dbo.T1 WITH(TABLOCK) (grp, ord, val)
SELECT
CAST(G.n AS VARCHAR(10)) AS grp,
CAST(R.n AS INT) AS ord,
CAST(ABS(CHECKSUM(NEWID())) % @uniquevalues + 1 AS VARCHAR(10)) AS val
FROM dbo.GetNums(1, @numgroups) AS G
CROSS JOIN dbo.GetNums(1, @rowspergroup) AS R;
ALTER TABLE dbo.T1 ADD CONSTRAINT PK_T1 PRIMARY KEY CLUSTERED(grp, ord);
अपने प्रदर्शन परीक्षणों में, मैंने प्रति समूह 1,000 और 10,000 पंक्तियों (इसलिए 1M से 10M पंक्तियों) और 5 अलग-अलग मानों के बीच तालिका को 1,000 समूहों के साथ आबाद किया। मैंने SELECT INTO . का उपयोग किया है एक अस्थायी तालिका में परिणाम लिखने के लिए बयान।
मेरी टेस्ट मशीन में चार लॉजिकल सीपीयू हैं, जो SQL सर्वर 2019 एंटरप्राइज चला रहे हैं।
मुझे लगता है कि आप सीधे पंक्ति स्टोर पर बैच मोड का समर्थन करने के लिए डिज़ाइन किए गए वातावरण का उपयोग कर रहे हैं, उदाहरण के लिए, मेरे जैसे SQL सर्वर 2019 एंटरप्राइज़ संस्करण का उपयोग करना, या परोक्ष रूप से, टेबल पर एक डमी कॉलमस्टोर इंडेक्स बनाकर।
याद रखें, अतिरिक्त अंक यदि आप योजना में स्पष्ट रूप से छाँटने के बिना एक कुशल समाधान के साथ आने का प्रबंधन करते हैं। शुभकामनाएँ!
क्या विंडो फ़ंक्शन के अनुकूलन के लिए सॉर्ट ऑपरेटर की आवश्यकता है?
इससे पहले कि मैं समाधान कवर करूं, थोड़ा अनुकूलन पृष्ठभूमि ताकि आप बाद में क्वेरी योजनाओं में जो देखेंगे वह अधिक समझ में आएगा।
हमारे जैसे द्वीप कार्यों को हल करने के लिए सबसे आम तकनीकों में कुल और/या रैंकिंग विंडो फ़ंक्शंस के कुछ संयोजन का उपयोग करना शामिल है। SQL सर्वर पुराने रो मोड ऑपरेटरों (सेगमेंट, सीक्वेंस प्रोजेक्ट, सेगमेंट, विंडो स्पूल, स्ट्रीम एग्रीगेट) या नए और आमतौर पर अधिक कुशल बैच मोड विंडो एग्रीगेट ऑपरेटर की एक श्रृंखला का उपयोग करके ऐसे विंडो फ़ंक्शन को संसाधित कर सकता है।
दोनों ही मामलों में, विंडो फ़ंक्शन की गणना को संभालने वाले ऑपरेटरों को विंडो विभाजन और ऑर्डरिंग तत्वों द्वारा ऑर्डर किए गए डेटा को निगलना होगा। यदि आपके पास एक सहायक सूचकांक नहीं है, तो स्वाभाविक रूप से SQL सर्वर को योजना में एक सॉर्ट ऑपरेटर पेश करने की आवश्यकता होगी। उदाहरण के लिए, यदि आपके समाधान में विभाजन और क्रम के एक से अधिक अद्वितीय संयोजन के साथ कई विंडो फ़ंक्शन हैं, तो आप योजना में स्पष्ट सॉर्टिंग के लिए बाध्य हैं। लेकिन क्या होगा यदि आपके पास विभाजन और क्रम और एक सहायक अनुक्रमणिका का केवल एक अनूठा संयोजन है?
पुरानी पंक्ति मोड विधि सीरियल और समानांतर मोड दोनों में एक स्पष्ट सॉर्ट ऑपरेटर की आवश्यकता के बिना किसी इंडेक्स से पहले से ऑर्डर किए गए डेटा पर भरोसा कर सकती है। नया बैच मोड ऑपरेटर पुराने रो मोड ऑप्टिमाइज़ेशन की अधिकांश अक्षमताओं को समाप्त करता है और बैच मोड प्रोसेसिंग के अंतर्निहित लाभ रखता है। हालांकि, इसके वर्तमान समानांतर कार्यान्वयन के लिए एक मध्यस्थ बैच मोड समानांतर सॉर्ट ऑपरेटर की आवश्यकता होती है, भले ही एक सहायक सूचकांक मौजूद हो। केवल इसका सीरियल कार्यान्वयन बिना सॉर्ट ऑपरेटर के इंडेक्स ऑर्डर पर भरोसा कर सकता है। यह सब कहने के लिए है जब ऑप्टिमाइज़र को आपके विंडो फ़ंक्शन को संभालने के लिए एक रणनीति चुनने की आवश्यकता होती है, यह मानते हुए कि आपके पास एक सहायक सूचकांक है, यह आम तौर पर निम्नलिखित चार विकल्पों में से एक होगा:
- पंक्ति मोड, धारावाहिक, कोई छँटाई नहीं
- पंक्ति मोड, समानांतर, कोई छँटाई नहीं
- बैच मोड, सीरियल, कोई छँटाई नहीं
- बैच मोड, समानांतर, सॉर्टिंग
न्यूनतम योजना लागत में से जो भी एक परिणाम चुना जाएगा, यह मानते हुए कि समानांतरवाद और बैच मोड के लिए पूर्वापेक्षाएँ उन पर विचार करते समय पूरी होती हैं। आम तौर पर, ऑप्टिमाइज़र के लिए समानांतर योजना को सही ठहराने के लिए, समानांतरवाद के लाभों को थ्रेड सिंक्रोनाइज़ेशन जैसे अतिरिक्त कार्य से आगे निकलने की आवश्यकता होती है। ऊपर दिए गए विकल्प 4 के साथ, समांतरता के लाभों को समानांतरवाद से जुड़े सामान्य अतिरिक्त कार्य, साथ ही अतिरिक्त प्रकार से अधिक होना चाहिए।
हमारी चुनौती के विभिन्न समाधानों के साथ प्रयोग करते समय, मेरे पास ऐसे मामले थे जहां अनुकूलक ने ऊपर विकल्प 2 चुना था। इसने इस तथ्य के बावजूद इसे चुना कि पंक्ति मोड पद्धति में कुछ अक्षमताएं शामिल हैं क्योंकि समानांतरवाद और कोई छँटाई में लाभ के परिणामस्वरूप विकल्पों की तुलना में कम लागत वाली योजना नहीं है। उनमें से कुछ मामलों में, एक संकेत के साथ एक सीरियल योजना को मजबूर करने के परिणामस्वरूप ऊपर विकल्प 3 और बेहतर प्रदर्शन हुआ।
इस पृष्ठभूमि को ध्यान में रखते हुए, आइए समाधान देखें। मैं द्वीप के कार्यों के लिए ज्ञात तकनीकों पर भरोसा करने वाले दो समाधानों के साथ शुरुआत करूंगा जो योजना में स्पष्ट छँटाई से बच नहीं सकते।
ज्ञात तकनीक 1 पर आधारित समाधान
हमारी चुनौती का पहला समाधान निम्नलिखित है, जो एक ऐसी तकनीक पर आधारित है जिसे कुछ समय से जाना जाता है:
WITH C AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) -
ROW_NUMBER() OVER(PARTITION BY grp, val ORDER BY ord) AS island
FROM dbo.T1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, val, island ORDER BY ord) AS seqno
FROM C; मैं इसे ज्ञात समाधान 1 के रूप में संदर्भित करूंगा।
C नामक CTE एक क्वेरी पर आधारित है जो दो पंक्ति संख्याओं की गणना करती है। पहला (मैं इसे rn1 के रूप में संदर्भित करूंगा) को जीआरपी द्वारा विभाजित किया गया है और ऑर्ड द्वारा आदेश दिया गया है। दूसरा (मैं इसे rn2 के रूप में संदर्भित करूंगा) जीआरपी और वैल द्वारा विभाजित किया गया है और ऑर्ड द्वारा आदेश दिया गया है। चूंकि rn1 में एक ही वैल के विभिन्न समूहों के बीच अंतराल है और rn2 नहीं है, rn1 और rn2 (आइलैंड नामक कॉलम) के बीच का अंतर समान जीआरपी और वैल मान वाली सभी पंक्तियों के लिए एक अद्वितीय स्थिर मान है। निम्नलिखित दो-पंक्ति संख्या गणनाओं के परिणामों सहित आंतरिक क्वेरी का परिणाम है, जो अलग-अलग कॉलम के रूप में वापस नहीं किया जाता है:
grp ord val rn1 rn2 island -------- ----- ---- ---- ---- ------- Group A 1002 Y 1 1 0 Group A 1003 Y 2 2 0 Group A 1005 Y 3 3 0 Group A 1007 N 4 1 3 Group A 1011 N 5 2 3 Group A 1013 N 6 3 3 Group A 1017 Y 7 4 3 Group A 1019 Y 8 5 3 Group A 1023 N 9 4 5 Group A 1029 N 10 5 5 Group B 1001 X 1 1 0 Group B 1002 X 2 2 0 Group B 1003 Z 3 1 2 Group B 1005 Z 4 2 2 Group B 1008 Z 5 3 2 Group B 1013 Z 6 4 2 Group B 1021 Y 7 1 6 Group B 1034 Y 8 2 6
बाहरी क्वेरी के लिए जो करना बाकी है, वह है ROW_NUMBER फ़ंक्शन का उपयोग करके परिणाम कॉलम seqno की गणना करना, जिसे grp, val, और द्वीप द्वारा विभाजित किया गया है, और वांछित परिणाम उत्पन्न करते हुए ord द्वारा आदेश दिया गया है।
ध्यान दें कि आप एक ही विभाजन के भीतर विभिन्न वैल मानों के लिए समान द्वीप मान प्राप्त कर सकते हैं, जैसे कि उपरोक्त आउटपुट में। यही कारण है कि खिड़की विभाजन तत्वों के रूप में जीआरपी, वैल और द्वीप का उपयोग करना महत्वपूर्ण है, न कि केवल जीआरपी और द्वीप।
इसी तरह, यदि आप एक द्वीप कार्य के साथ काम कर रहे हैं जिसके लिए आपको द्वीप द्वारा डेटा को समूहित करने और समूह समुच्चय की गणना करने की आवश्यकता है, तो आप पंक्तियों को जीआरपी, वैल और द्वीप द्वारा समूहित करेंगे। लेकिन हमारी चुनौती के साथ ऐसा नहीं है। यहां आपको प्रत्येक द्वीप के लिए स्वतंत्र रूप से पंक्ति संख्याओं की गणना करने का काम सौंपा गया था।
चित्र 1 में डिफ़ॉल्ट योजना है जो मुझे इस समाधान के लिए मेरी मशीन पर 10M पंक्तियों के साथ तालिका को पॉप्युलेट करने के बाद मिली है।
 चित्र 1:ज्ञात समाधान 1 के लिए समानांतर योजना
चित्र 1:ज्ञात समाधान 1 के लिए समानांतर योजना
rn1 की गणना अनुक्रमणिका क्रम पर निर्भर कर सकती है। इसलिए, ऑप्टिमाइज़र ने इसके लिए नो सॉर्ट + पैरेलल रो मोड स्ट्रैटेजी को चुना (प्लान में पहला सेगमेंट और सीक्वेंस प्रोजेक्ट ऑपरेटर)। चूंकि rn2 और seqno दोनों की गणना विभाजन और क्रम तत्वों के अपने स्वयं के अनूठे संयोजनों का उपयोग करती है, इसलिए स्पष्ट छँटाई उन लोगों के लिए अपरिहार्य है जो इस्तेमाल की गई रणनीति के बावजूद हैं। इसलिए, ऑप्टिमाइज़र ने दोनों के लिए सॉर्ट + समानांतर बैच मोड रणनीति को चुना। इस योजना में दो स्पष्ट सॉर्ट ऑपरेटर शामिल हैं।
मेरे प्रदर्शन परीक्षण में, इस समाधान को 1M पंक्तियों के विरुद्ध पूरा करने में 3.68 सेकंड और 10M पंक्तियों के विरुद्ध 43.1 सेकंड का समय लगा।
जैसा कि उल्लेख किया गया है, मैंने एक सीरियल प्लान (MAXDOP 1 संकेत के साथ) को मजबूर करके सभी समाधानों का भी परीक्षण किया। इस समाधान के लिए सीरियल प्लान चित्र 1 में दिखाया गया है।
 चित्र 2:ज्ञात समाधान 1 के लिए सीरियल योजना
चित्र 2:ज्ञात समाधान 1 के लिए सीरियल योजना
जैसा कि अपेक्षित था, इस बार भी rn1 की गणना पूर्ववर्ती सॉर्ट ऑपरेटर के बिना बैच मोड रणनीति का उपयोग करती है, लेकिन योजना में अभी भी बाद की पंक्ति संख्या गणना के लिए दो सॉर्ट ऑपरेटर हैं। सीरियल प्लान ने मेरे द्वारा परीक्षण किए गए सभी इनपुट आकारों के साथ मेरी मशीन पर समानांतर एक से भी बदतर प्रदर्शन किया, जिसमें 1M पंक्तियों के साथ 4.54 सेकंड और 10M पंक्तियों के साथ 61.5 सेकंड का समय लगा।
ज्ञात तकनीक 2 पर आधारित समाधान
दूसरा समाधान जो मैं प्रस्तुत करूंगा, वह द्वीप का पता लगाने के लिए एक शानदार तकनीक पर आधारित है जिसे मैंने कुछ साल पहले पॉल व्हाइट से सीखा था। इस तकनीक पर आधारित संपूर्ण समाधान कोड निम्नलिखित है:
WITH C1 AS
(
SELECT *,
CASE
WHEN val = LAG(val) OVER(PARTITION BY grp ORDER BY ord) THEN 0
ELSE 1
END AS isstart
FROM dbo.T1
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS island
FROM C1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, island ORDER BY ord) AS seqno
FROM C2; मैं इस समाधान को ज्ञात समाधान 2 के रूप में संदर्भित करूंगा।
CTE C1 कंप्यूट को परिभाषित करने वाली क्वेरी isstart नामक परिणाम कॉलम की गणना करने के लिए CASE एक्सप्रेशन और LAG विंडो फ़ंक्शन (grp द्वारा विभाजित और ord द्वारा आदेशित) का उपयोग करती है। इस कॉलम का मान 0 होता है, जब वर्तमान वैल मान पिछले और 1 के समान होता है। दूसरे शब्दों में, यह 1 तब होता है जब किसी द्वीप में पंक्ति पहली होती है और 0 अन्यथा।
C1 को परिभाषित करने वाली क्वेरी का आउटपुट निम्नलिखित है:
grp ord val isstart -------- ----- ---- -------- Group A 1002 Y 1 Group A 1003 Y 0 Group A 1005 Y 0 Group A 1007 N 1 Group A 1011 N 0 Group A 1013 N 0 Group A 1017 Y 1 Group A 1019 Y 0 Group A 1023 N 1 Group A 1029 N 0 Group B 1001 X 1 Group B 1002 X 0 Group B 1003 Z 1 Group B 1005 Z 0 Group B 1008 Z 0 Group B 1013 Z 0 Group B 1021 Y 1 Group B 1034 Y 0
जहां तक द्वीप का पता लगाने का सवाल है तो जादू सीटीई सी2 में होता है। इसे परिभाषित करने वाली क्वेरी isstart कॉलम पर लागू SUM विंडो फ़ंक्शन (जीआरपी द्वारा विभाजित और ऑर्ड द्वारा आदेशित) का उपयोग करके एक द्वीप पहचानकर्ता की गणना करती है। द्वीप पहचानकर्ता के साथ परिणाम स्तंभ को द्वीप कहा जाता है। प्रत्येक विभाजन के भीतर, आपको पहले द्वीप के लिए 1, दूसरे द्वीप के लिए 2, इत्यादि मिलते हैं। इसलिए, कॉलम जीआरपी और द्वीप का संयोजन एक द्वीप पहचानकर्ता है, जिसका उपयोग आप उन द्वीपों के कार्यों में कर सकते हैं जिनमें प्रासंगिक होने पर द्वीप के आधार पर समूह बनाना शामिल है।
C2 को परिभाषित करने वाली क्वेरी का आउटपुट निम्नलिखित है:
grp ord val isstart island -------- ----- ---- -------- ------- Group A 1002 Y 1 1 Group A 1003 Y 0 1 Group A 1005 Y 0 1 Group A 1007 N 1 2 Group A 1011 N 0 2 Group A 1013 N 0 2 Group A 1017 Y 1 3 Group A 1019 Y 0 3 Group A 1023 N 1 4 Group A 1029 N 0 4 Group B 1001 X 1 1 Group B 1002 X 0 1 Group B 1003 Z 1 2 Group B 1005 Z 0 2 Group B 1008 Z 0 2 Group B 1013 Z 0 2 Group B 1021 Y 1 3 Group B 1034 Y 0 3
अंत में, बाहरी क्वेरी वांछित परिणाम कॉलम seqno की गणना ROW_NUMBER फ़ंक्शन के साथ करती है, जिसे जीआरपी और द्वीप द्वारा विभाजित किया जाता है, और ऑर्ड द्वारा आदेश दिया जाता है। ध्यान दें कि विभाजन और क्रम के तत्वों का यह संयोजन पिछले विंडो फ़ंक्शन द्वारा उपयोग किए गए संयोजन से अलग है। जबकि पहले दो विंडो फ़ंक्शंस की गणना संभावित रूप से इंडेक्स ऑर्डर पर निर्भर हो सकती है, अंतिम नहीं।
चित्र 3 में डिफ़ॉल्ट योजना है जो मुझे इस समाधान के लिए मिली है।
 चित्र 3:ज्ञात समाधान 2 के लिए समानांतर योजना
चित्र 3:ज्ञात समाधान 2 के लिए समानांतर योजना
जैसा कि आप योजना में देख सकते हैं, पहले दो विंडो फ़ंक्शंस की गणना नो सॉर्ट + समानांतर पंक्ति मोड रणनीति का उपयोग करती है, और अंतिम की गणना सॉर्ट + समानांतर बैच मोड रणनीति का उपयोग करती है।
इस समाधान के लिए मुझे जो रन टाइम मिला वह 2.57 सेकंड से लेकर 1M पंक्तियों के मुकाबले 10M पंक्तियों के विरुद्ध 46.2 सेकंड तक था।
सीरियल प्रोसेसिंग के लिए मजबूर करते समय, मुझे चित्र 4 में दिखाया गया प्लान मिला।
 चित्र 4:ज्ञात समाधान 2 के लिए सीरियल प्लान
चित्र 4:ज्ञात समाधान 2 के लिए सीरियल प्लान
जैसा कि अपेक्षित था, इस बार सभी विंडो फ़ंक्शन कंप्यूटेशंस बैच मोड रणनीति पर निर्भर हैं। पहले दो बिना पूर्ववर्ती छँटाई के, और अंतिम के साथ। समानांतर योजना और धारावाहिक दोनों में एक स्पष्ट सॉर्ट ऑपरेटर शामिल था। सीरियल प्लान ने मेरे द्वारा परीक्षण किए गए इनपुट आकारों के साथ मेरी मशीन पर समानांतर योजना से बेहतर प्रदर्शन किया। जबरन सीरियल प्लान के लिए मुझे मिला रन टाइम 1.75 सेकंड से लेकर 1M पंक्तियों के मुकाबले 21.7 सेकंड तक 10M पंक्तियों के विरुद्ध था।
नई तकनीक पर आधारित समाधान
जब एरलैंड ने इस चुनौती को एक निजी मंच में पेश किया, तो लोगों को एक प्रश्न के साथ इसे हल करने की संभावना पर संदेह था, जिसे बिना स्पष्ट छँटाई के एक योजना के साथ अनुकूलित किया गया था। मुझे प्रेरित करने के लिए मुझे बस इतना ही सुनना था। तो, यहाँ मैं क्या लेकर आया हूँ:
WITH C1 AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) AS rn,
LAG(val) OVER(PARTITION BY grp ORDER BY ord) AS prev
FROM dbo.T1
),
C2 AS
(
SELECT *,
MAX(CASE WHEN val = prev THEN NULL ELSE rn END)
OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS firstrn
FROM C1
)
SELECT grp, ord, val, rn - firstrn + 1 AS seqno
FROM C2; समाधान तीन विंडो फ़ंक्शंस का उपयोग करता है:LAG, ROW_NUMBER और MAX। यहां महत्वपूर्ण बात यह है कि तीनों जीआरपी विभाजन और क्रम क्रम पर आधारित हैं, जो सहायक सूचकांक कुंजी क्रम के साथ संरेखित है।
CTE C1 को परिभाषित करने वाली क्वेरी पंक्ति संख्या (rn कॉलम) की गणना करने के लिए ROW_NUMBER फ़ंक्शन का उपयोग करती है, और LAG फ़ंक्शन पिछले वैल मान (पिछला कॉलम) को वापस करने के लिए उपयोग करती है।
C1 को परिभाषित करने वाली क्वेरी का आउटपुट यहां दिया गया है:
grp ord val rn prev -------- ----- ---- --- ----- Group A 1002 Y 1 NULL Group A 1003 Y 2 Y Group A 1005 Y 3 Y Group A 1007 N 4 Y Group A 1011 N 5 N Group A 1013 N 6 N Group A 1017 Y 7 N Group A 1019 Y 8 Y Group A 1023 N 9 Y Group A 1029 N 10 N Group B 1001 X 1 NULL Group B 1002 X 2 X Group B 1003 Z 3 X Group B 1005 Z 4 Z Group B 1008 Z 5 Z Group B 1013 Z 6 Z Group B 1021 Y 7 Z Group B 1034 Y 8 Y
ध्यान दें कि जब वैल और प्रीव समान हों, तो यह द्वीप में पहली पंक्ति नहीं है, अन्यथा यह है।
इस तर्क के आधार पर, CTE C2 को परिभाषित करने वाली क्वेरी एक CASE व्यंजक का उपयोग करती है जो rn देता है जब पंक्ति किसी द्वीप में पहली होती है और अन्यथा NULL। कोड तब MAX विंडो फ़ंक्शन को CASE व्यंजक के परिणाम पर लागू करता है, द्वीप के पहले rn (प्रथम स्तंभ) को लौटाता है।
C2 को परिभाषित करने वाली क्वेरी का आउटपुट यहां दिया गया है, जिसमें CASE एक्सप्रेशन का आउटपुट भी शामिल है:
grp ord val rn prev CASE firstrn -------- ----- ---- --- ----- ----- -------- Group A 1002 Y 1 NULL 1 1 Group A 1003 Y 2 Y NULL 1 Group A 1005 Y 3 Y NULL 1 Group A 1007 N 4 Y 4 4 Group A 1011 N 5 N NULL 4 Group A 1013 N 6 N NULL 4 Group A 1017 Y 7 N 7 7 Group A 1019 Y 8 Y NULL 7 Group A 1023 N 9 Y 9 9 Group A 1029 N 10 N NULL 9 Group B 1001 X 1 NULL 1 1 Group B 1002 X 2 X NULL 1 Group B 1003 Z 3 X 3 3 Group B 1005 Z 4 Z NULL 3 Group B 1008 Z 5 Z NULL 3 Group B 1013 Z 6 Z NULL 3 Group B 1021 Y 7 Z 7 7 Group B 1034 Y 8 Y NULL 7
बाहरी क्वेरी के लिए जो बचा है वह वांछित परिणाम कॉलम seqno की गणना rn माइनस फर्स्टरन प्लस 1 के रूप में करना है।
चित्र 5 में डिफ़ॉल्ट समानांतर योजना है जो मुझे इस समाधान के लिए मिली है, जब इसका परीक्षण SELECT INTO स्टेटमेंट का उपयोग करके किया जाता है, तो परिणाम को एक अस्थायी तालिका में लिखा जाता है।
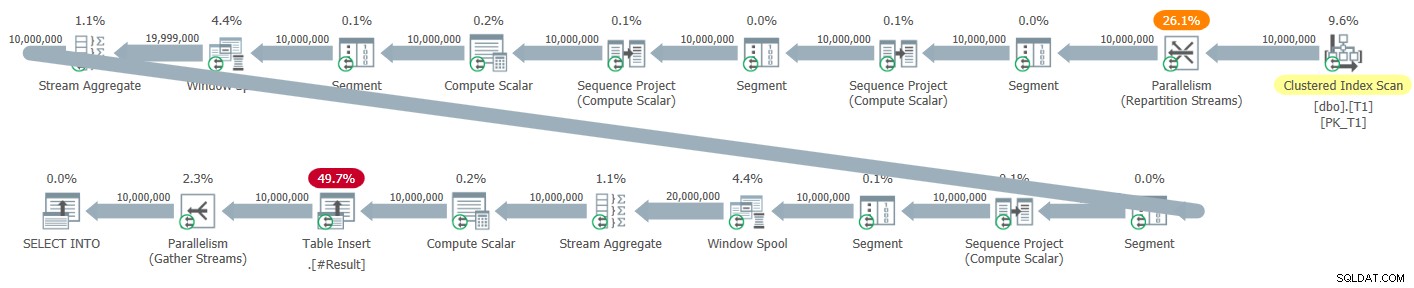 चित्र 5:नए समाधान के लिए समानांतर योजना
चित्र 5:नए समाधान के लिए समानांतर योजना
इस योजना में कोई स्पष्ट सॉर्ट ऑपरेटर नहीं हैं। हालाँकि, सभी तीन विंडो फ़ंक्शंस की गणना नो सॉर्ट + समानांतर पंक्ति मोड रणनीति का उपयोग करके की जाती है, इसलिए हम बैच प्रोसेसिंग के लाभों को याद कर रहे हैं। समानांतर योजना के साथ इस समाधान के लिए मुझे मिला रन टाइम 2.47 सेकंड से 1M पंक्तियों के विरुद्ध और 41.4 10M पंक्तियों के विरुद्ध था।
यहां, बैच प्रोसेसिंग के साथ सीरियल प्लान के लिए काफी बेहतर करने की संभावना है, खासकर जब मशीन में कई सीपीयू नहीं होते हैं। याद रखें कि मैं 4 लॉजिकल सीपीयू वाली मशीन के खिलाफ अपने समाधान का परीक्षण कर रहा हूं। धारावाहिक प्रसंस्करण के लिए मजबूर करते समय चित्र 6 में इस समाधान के लिए मुझे मिली योजना है।
 चित्र 6:एक नए समाधान के लिए सीरियल योजना
चित्र 6:एक नए समाधान के लिए सीरियल योजना
सभी तीन विंडो फ़ंक्शन नो सॉर्ट + सीरियल बैच मोड रणनीति का उपयोग करते हैं। और परिणाम काफी प्रभावशाली हैं। यह समाधान चलाने का समय 0.5 सेकंड से 1M पंक्तियों के विरुद्ध और 5.49 सेकंड 10M पंक्तियों के विरुद्ध था। इस समाधान के बारे में भी उत्सुकता यह है कि जब इसे सामान्य चयन कथन के रूप में परीक्षण किया जाता है (परिणामों को छोड़ दिया जाता है) जैसा कि चयन में कथन के विपरीत होता है, तो SQL सर्वर ने डिफ़ॉल्ट रूप से सीरियल योजना को चुना। अन्य दो समाधानों के साथ, मुझे डिफ़ॉल्ट रूप से SELECT और SELECT INTO दोनों के साथ समानांतर योजना मिली।
संपूर्ण प्रदर्शन परीक्षण परिणामों के लिए अगला भाग देखें।
प्रदर्शन तुलना
यहाँ वह कोड है जिसका उपयोग मैंने तीन समाधानों का परीक्षण करने के लिए किया था, निश्चित रूप से सीरियल योजनाओं का परीक्षण करने के लिए MAXDOP 1 संकेत को अनसुना करना:
-- Test Known Solution 1
DROP TABLE IF EXISTS #Result;
WITH C AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) -
ROW_NUMBER() OVER(PARTITION BY grp, val ORDER BY ord) AS island
FROM dbo.T1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, val, island ORDER BY ord) AS seqno
INTO #Result
FROM C
/* OPTION(MAXDOP 1) */; -- uncomment for serial test
GO
-- Test Known Solution 2
DROP TABLE IF EXISTS #Result;
WITH C1 AS
(
SELECT *,
CASE
WHEN val = LAG(val) OVER(PARTITION BY grp ORDER BY ord) THEN 0
ELSE 1
END AS isstart
FROM dbo.T1
),
C2 AS
(
SELECT *,
SUM(isstart) OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS island
FROM C1
)
SELECT grp, ord, val,
ROW_NUMBER() OVER(PARTITION BY grp, island ORDER BY ord) AS seqno
INTO #Result
FROM C2
/* OPTION(MAXDOP 1) */;
GO
-- Test New Solution
DROP TABLE IF EXISTS #Result;
WITH C1 AS
(
SELECT *,
ROW_NUMBER() OVER(PARTITION BY grp ORDER BY ord) AS rn,
LAG(val) OVER(PARTITION BY grp ORDER BY ord) AS prev
FROM dbo.T1
),
C2 AS
(
SELECT *,
MAX(CASE WHEN val = prev THEN NULL ELSE rn END)
OVER(PARTITION BY grp ORDER BY ord ROWS UNBOUNDED PRECEDING) AS firstrn
FROM C1
)
SELECT grp, ord, val, rn - firstrn + 1 AS seqno
INTO #Result
FROM C2
/* OPTION(MAXDOP 1) */; चित्र 7 में विभिन्न इनपुट आकारों के विरुद्ध सभी समाधानों के लिए समानांतर और धारावाहिक दोनों योजनाओं का रन टाइम है।
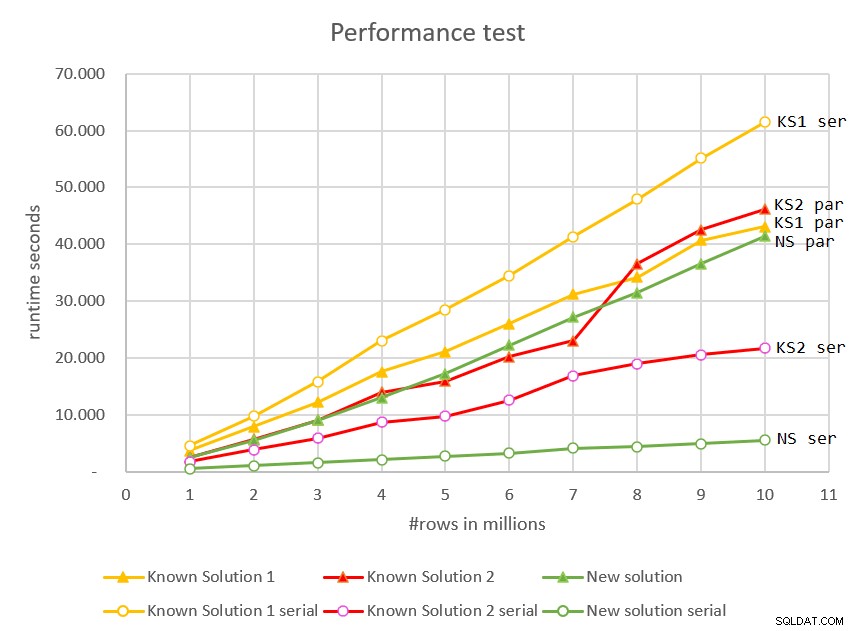 चित्र 7:प्रदर्शन तुलना
चित्र 7:प्रदर्शन तुलना
सीरियल मोड का उपयोग करने वाला नया समाधान स्पष्ट विजेता है। इसमें शानदार प्रदर्शन, रैखिक स्केलिंग और तत्काल प्रतिक्रिया समय है।
निष्कर्ष
वास्तविक जीवन में द्वीप कार्य काफी सामान्य हैं। उनमें से कई में द्वीपों की पहचान करना और द्वीप द्वारा डेटा को समूहबद्ध करना दोनों शामिल हैं। एरलैंड्स आइलैंड्स चैलेंज, जो इस लेख का फोकस था, थोड़ा अधिक अनोखा है क्योंकि इसमें समूहीकरण शामिल नहीं है, बल्कि प्रत्येक द्वीप की पंक्तियों को पंक्ति संख्याओं के साथ अनुक्रमित करना शामिल है।
मैंने द्वीपों की पहचान के लिए ज्ञात तकनीकों के आधार पर दो समाधान प्रस्तुत किए। दोनों के साथ समस्या यह है कि वे स्पष्ट छँटाई वाली योजनाओं में परिणत होते हैं, जो समाधानों के प्रदर्शन, मापनीयता और प्रतिक्रिया समय को नकारात्मक रूप से प्रभावित करता है। मैंने एक नई तकनीक भी प्रस्तुत की जिसके परिणामस्वरूप बिना किसी छँटाई वाली योजना बनाई गई। इस समाधान के लिए सीरियल प्लान, जो बिना सॉर्ट + सीरियल बैच मोड रणनीति का उपयोग करता है, में उत्कृष्ट प्रदर्शन, रैखिक स्केलिंग और तत्काल प्रतिक्रिया समय है। यह दुर्भाग्यपूर्ण है, कम से कम अभी के लिए, हमारे पास विंडो फ़ंक्शंस को संभालने के लिए नो सॉर्ट + समानांतर बैच मोड रणनीति नहीं हो सकती है।