नोट:यह आलेख दोनों आर्किटेक्चर के परिचय के बाद, वोरसिटी (और इसके शामिल उत्पादों), आईआरआई वर्कबेंच के लिए एक्लिप्स आईडीई का उपयोग करके एक रिलेशनल डेटाबेस (आरडीबी) मॉडल को स्टार स्कीमा में माइग्रेशन दिखाता है। यदि आप अपने आरडीबी या डेटा को डेटा वॉल्ट 2.0 मॉडल में माइग्रेट करने में रुचि रखते हैं, तो मई 2019 में वर्ल्ड वाइड डेटा वॉल्ट कंसोर्टियम में एक नया वर्कबेंच विज़ार्ड शुरू होगा; प्रकाशित होते ही उन चरण-दर-चरण निर्देशों को प्राप्त करने के लिए IRI ब्लॉग की सदस्यता लें!
डेटा वेयरहाउस (DW) एक व्यवसाय में परिचालन या लेन-देन प्रणाली से निकाले गए डेटा का एक संग्रह है, जिसे विसंगतियों को दूर करने के लिए बदल दिया जाता है, और फिर तेजी से विश्लेषण और/या रिपोर्टिंग का समर्थन करने के लिए व्यवस्थित किया जाता है। डीडब्ल्यू को अपने परिचालन डेटाबेस के एक स्कीमा, या तार्किक विवरण और ग्राफिकल प्रतिनिधित्व की आवश्यकता होती है। पारंपरिक रिलेशनल डेटाबेस स्कीमा से स्टार स्कीमा नामक एक लोकप्रिय DW स्कीमा में जाने के लिए कैसे-करें मार्गदर्शिका प्रदान करते हुए यह लेख उन विषयों पर स्पर्श करता है।
स्टार स्कीमा बनाम संबंधपरक
अधिकांश संबंधपरक डेटा संरचनाएं इकाई-संबंध (ईआर) आरेखों में सचित्र हैं। एक ऑनलाइन लेनदेन प्रसंस्करण (ओएलटीपी) डेटाबेस प्रबंधन प्रणाली के लिए वैचारिक मॉडल के विकास में एक ईआर आरेख का उपयोग किया जाता है। यह वह स्रोत है जिससे तालिका संरचना का अनुवाद किया जाता है।
हालांकि, स्टार स्कीमा डेटा वेयरहाउस की अंतर्निहित तालिका संरचना के लिए व्यापक रूप से स्वीकृत मानक है। इसका सरल तारा-आकृति (जब ईआर-आरेखित) केंद्र में तथ्य तालिका (लेन-देन मान या माप युक्त) दिखाता है, और आयाम तालिकाएं (वर्णनात्मक या गुणकारी मान युक्त) इससे निकलती हैं। आमतौर पर, तथ्य तालिका तीसरे-सामान्य रूप (3NF) में होती है, जबकि आयामी तालिकाएं असामान्य होती हैं।
एंटिटी-रिलेशनल (ईआर) मॉडल और स्टार मॉडल के बीच बुनियादी अंतर यह है कि:
- ईआर मॉडल सामान्यीकृत डेटाबेस डिजाइन के लिए तार्किक और भौतिक संरचनाओं का उपयोग करते हैं
- आयाम मॉडल असामान्यीकृत डेटाबेस डिज़ाइन के लिए एक भौतिक संरचना का उपयोग करता है
यह देखने के लिए कि कैसे IRI सॉफ़्टवेयर पंक्ति-स्तंभ पिवटिंग के माध्यम से डेटा को डी/सामान्यीकृत कर सकता है, यहां क्लिक करें।
रूपांतरण प्रक्रिया पृष्ठभूमि
इस लेख में, मैं प्रदर्शित करता हूं कि नौकरियों का उपयोग करके एक रिलेशनल मॉडल से डेटा को स्टार में कैसे परिवर्तित किया जाए, जिसे आपको कम या ज्यादा मैन्युअल रूप से परिभाषित करना चाहिए, लेकिन स्वचालित रूप से बना और चला सकता है, और आसानी से संशोधित कर सकता है।
आप यहां IRI के 4GL डेटा और कार्य विनिर्देश देखेंगे - "SortCL" स्क्रिप्ट में व्यक्त किया गया[1] - जो डेटा को आयाम तालिकाओं में मैप करता है, और डेटा को केंद्रीय तथ्य तालिका में जोड़ता है। SortCL IRI Voracity डेटा प्रबंधन और ETL प्लेटफ़ॉर्म में मुख्य डेटा हेरफेर और मैपिंग प्रोग्राम है। हालांकि, मेरी सॉर्टसीएल नौकरियों में कार्यप्रणाली और मैपिंग को समझना यहां महत्वपूर्ण है, स्क्रिप्टिंग सिंटैक्स नहीं।
यदि आप इसे नहीं करना चाहते हैं तो इन स्क्रिप्ट को स्वचालित रूप से बनाने या संशोधित करने के लिए मुफ़्त एक्लिप्स जीयूआई, आईआरआई वर्कबेंच, सिंटैक्स-जागरूक सॉर्टसीएल संपादक, साथ ही ग्राफिकल रूपरेखा और संवाद, वर्कफ़्लो और मैपिंग आरेख, और सहज ज्ञान युक्त जॉब विजार्ड प्रदान करता है। हाथ से। FYI करें, IRI, DB की रूपरेखा और आरेखण, परीक्षण डेटा जेनरेट करने, ETL करने, रिपोर्ट स्वरूपित करने, PII को छिपाने, परिवर्तित डेटा कैप्चर करने, डेटा माइग्रेट करने और दोहराने, डेटा को साफ़ करने और सत्यापित करने आदि के लिए समान मेटाडेटा और GUI का उपयोग करता है।
कार्यक्षेत्र JDBC पर डेटाबेस से कनेक्ट करने के लिए, और डेटा स्रोत एक्सप्लोरर (DSE) दृश्य में SQL संचालन और IRI मेटाडेटा एक्सचेंज को सक्षम करने के लिए ग्रहण के लिए डेटा टूल प्लेटफ़ॉर्म (DTP) प्लग-इन के एक उन्नत संस्करण का उपयोग करता है। इस मामले में, कार्यक्षेत्र समर्थन कर रहा है:
- सॉर्टसीएल (या इस लेख के अनुसार आईआरआई रोजेन जॉब्स) के माध्यम से बाधित Oracle परीक्षण (स्रोत) तालिकाओं का निर्माण और जनसंख्या
- सॉर्टसीएल के माध्यम से आयाम तालिका में इकाई तालिका डेटा की मैपिंग
- सिद्धांत आयाम तालिका को संबद्ध करने के लिए एन-एरी संबंध के रूप में तथ्य तत्वों का मानचित्रण; यानी फैक्ट टेबल बनाने के लिए SortCL में मल्टी-टेबल जॉइन करना
- सभी लक्ष्य (स्टार स्कीमा) तालिकाओं की जनसंख्या
- स्रोत और लक्ष्य स्कीमा के ईआर आरेख
मेरे मूल संबंधपरक मॉडल में इकाई प्रकार हैं:विभाग, एम्प, परियोजना, श्रेणी, आइटम, Item_Use, और बिक्री:
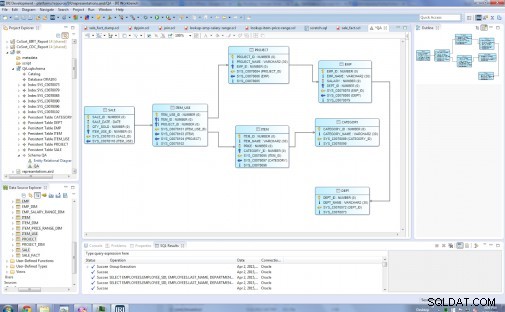
इससे पहले ...
अगला आरेख आठ आयाम तालिकाओं और एक तथ्य तालिका के साथ अंतिम स्टार मॉडल दिखाता है। आयाम तालिकाएं हैं: Dept_Dim, Emp_Dim, Emp_Salary_Range_Dim, Project_Dim, category_Dim, Item_Price_Range_Dim, Item_Dim। केंद्र में तथ्य तालिका Sale_Fact है, जिसमें सभी आयाम तालिकाओं की कुंजियां हैं।

… के बाद
रूपांतरण चरण
- तथ्य तालिका को परिभाषित करें और बनाएं
Sale_Fact तालिका की संरचना इस दस्तावेज़ में दिखाई गई है। प्राथमिक कुंजी बिक्री_आईडी है, और बाकी विशेषताएँ आयाम तालिकाओं से विरासत में मिली विदेशी कुंजियाँ हैं। मैं डेटा परिवर्तन और मानचित्रण के लिए वर्कबेंच डीएसई (जेडीबीसी के माध्यम से) और सॉर्टसीएल से जुड़े ओरेकल डेटाबेस (हालांकि कोई भी आरडीबी काम करता है) का उपयोग कर रहा हूं ( ओडीबीसी के माध्यम से)। मैंने DSE की SQL स्क्रैपबुक में संपादित और कार्यक्षेत्र में निष्पादित SQL स्क्रिप्ट में अपनी तालिकाएँ बनाईं।
- आयाम तालिकाओं को परिभाषित करें और बनाएं
इन आयाम तालिकाओं को बनाने के लिए ऊपर लिंक की गई उसी तकनीक और मेटाडेटा का उपयोग करें, जो अगले चरण में SortCL नौकरियों से मैप किए गए संबंधपरक डेटा प्राप्त करेगी:श्रेणी_डिम तालिका, विभाग से Dept_Dim, प्रोजेक्ट से Project_Dim, आइटम से Item_Dim, और Emp को Emp_Dim। आप टेबल बनाने के लिए एक बार में सभी क्रिएट लॉजिक के साथ उस .SQL प्रोग्राम को चला सकते हैं।
- मूल निकाय तालिका डेटा को आयाम तालिकाओं में ले जाएं
स्टार स्कीमा के लिए डायमेंशन टेबल में रिलेशनल स्कीमा से (RowGen-created test) डेटा को मैप करने के लिए यहां दिखाए गए SortCL जॉब्स को परिभाषित करें और चलाएं। विशेष रूप से, ये स्क्रिप्ट श्रेणी तालिका से श्रेणी_डिम तालिका, विभाग से Dept_Dim, प्रोजेक्ट से Project_Dim, आइटम से Item_Dim, और Emp से Emp_Dim तक डेटा लोड करती हैं।
- तथ्य तालिका तैयार करें
नई Sale_Fact तालिका के लिए डेटा तैयार करने के लिए मूल बिक्री, Emp, प्रोजेक्ट, Item_Use, आइटम, श्रेणी इकाई तालिका से डेटा में शामिल होने के लिए SortCL का उपयोग करें। दूसरी (जॉइन जॉब) स्क्रिप्ट का इस्तेमाल यहां करें।
अपने उदाहरण को बढ़ाने के लिए, हम स्टार स्कीमा में नए आयामी डेटा को पेश करने के लिए सॉर्टसीएल का भी उपयोग करेंगे, जिस पर मेरी फैक्ट टेबल भी निर्भर करेगी। आप ऊपर दिए गए स्टार आरेख में इन अतिरिक्त तालिकाओं को देख सकते हैं जो मेरे संबंधपरक स्कीमा में नहीं थीं:Emp_Salary_Range_Dim और Item_Price_Range_Dim। वे टेबल फैक्ट और अन्य डाइमेंशन टेबल के लिए उसी .SQL फ़ाइल में बनाई गई हैं।
फैक्ट टेबल को इन डायमेंशन टेबल में मानों की रेंज को दर्शाने के लिए इन टेबल से emp_salary_range_id और item_price_range_id डेटा की जरूरत होती है। जब मैं डेटा वेयरहाउस में आयामी मूल्य मान लोड करता हूं, उदाहरण के लिए, मैं उन्हें एक मूल्य सीमा में असाइन करना चाहता हूं:
| Item_Price | Range_Id | Range_Name | Range_End |
|---|---|---|---|
| 1 | निम्न | 1 | 100 |
| 2 | मध्य | 101 | 500 |
| 3 | उच्च | 501 | 999 |
कार्य स्क्रिप्ट में श्रेणी आईडी निर्दिष्ट करने का सबसे आसान तरीका (जो मेरी Sale_Fact तालिका के लिए डेटा तैयार कर रहा है) आउटपुट अनुभाग में IF-THEN-ELSE कथन का उपयोग करना है। पृष्ठभूमि के लिए बकेटिंग मानों पर यह लेख देखें।
वैसे भी, मैंने CoSort New Join Job . के साथ यह संपूर्ण कार्य बनाया है कार्यक्षेत्र में जादूगर। और एक बार जब मैंने इसे चलाया, तो मेरी तथ्य तालिका भर गई:
 IRI कार्यक्षेत्र DSE में Sales_Fact तालिका प्रदर्शन
IRI कार्यक्षेत्र DSE में Sales_Fact तालिका प्रदर्शन
निष्कर्ष
आयामी डेटा प्रतिनिधित्व का प्रमुख लाभ डेटाबेस संरचना की जटिलता को कम करना है। इससे लोगों के लिए तालिकाओं की संख्या को कम करके प्रश्नों को समझना और लिखना आसान हो जाता है, और इसलिए, आवश्यक जुड़ने की संख्या। जैसा कि पहले उल्लेख किया गया है, आयामी मॉडल भी क्वेरी प्रदर्शन को अनुकूलित करते हैं। हालांकि, इसमें कमजोरी भी है और ताकत भी। स्टार स्कीमा की निश्चित संरचना प्रश्नों को सीमित करती है। इसलिए, चूंकि यह सबसे सामान्य प्रश्नों को लिखना आसान बनाता है, यह डेटा के विश्लेषण के तरीके को भी प्रतिबंधित करता है।
वोरासिटी के लिए आईआरआई वर्कबेंच जीयूआई में टूल का एक शक्तिशाली और व्यापक सेट है जो डेटा वेयरहाउस के निर्माण, रखरखाव और विस्तार सहित डेटा एकीकरण को सरल बनाता है। इस सहज ज्ञान युक्त, उपयोग में आसान इंटरफ़ेस के साथ, वोरैसिटी तेजी से, लचीले, एंड-टू-एंड ईटीएल (एक्सट्रैक्ट, ट्रांसफॉर्म, लोड) प्रक्रिया निर्माण की सुविधा देता है जिसमें अलग-अलग प्लेटफॉर्म पर डेटा संरचनाएं शामिल होती हैं।
ईटीएल संचालन में, डेटा को अलग-अलग स्रोतों से निकाला जाता है, अलग-अलग रूपांतरित किया जाता है, और डेटा वेयरहाउस और संभवतः अन्य लक्ष्यों में लोड किया जाता है। ईटीएल प्रक्रिया का निर्माण, संभावित रूप से, गोदाम बनाने के सबसे बड़े कार्यों में से एक है; यह जटिल और समय लेने वाला है। IRI का ETL दृष्टिकोण फ़ाइल सिस्टम में सभी डेटा एकीकरण और स्टेजिंग को निष्पादित करके, अत्यधिक कुशल और डेटाबेस-स्वतंत्र तरीके से इस प्रक्रिया का समर्थन करता है।
[1] यदि आप एक सिंटैक्स हाउंड हैं, तो ध्यान दें कि IRI CoSort उत्पाद या IRI Voracity प्लेटफ़ॉर्म में उपयोग की जाने वाली SortCL स्क्रिप्ट परीक्षण डेटा पीढ़ी के लिए IRI RowGen के समान सिंटैक्स और डेटा परिभाषाओं का समर्थन करती हैं, डेटा माइग्रेशन के लिए IRI NextForm और IRI डेटा मास्किंग के लिए फ़ील्डशील्ड। वे सभी उपकरण आईआरआई वर्कबेंच जीयूआई में समर्थित हैं, और उनके मेटाडेटा को भी साझा किया जा सकता है और क्लाउड में संस्करण नियंत्रण, नौकरी/डेटा वंश और सुरक्षा के लिए टीम प्रबंधित की जा सकती है।
[2] IRI कार्यक्षेत्र में E-R आरेख प्रदर्शित करने के लिए:
- नया IRI प्रोजेक्ट चुनें और एक नया फ़ोल्डर बनाएं
- उस फ़ोल्डर का चयन करें और डेटा स्रोत एक्सप्लोरर में सभी लागू डेटाबेस तालिकाओं को हाइलाइट करें; फिर आईआरआई, न्यू ईआर-आरेख पर राइट क्लिक करें
- एक फ़ाइल (Schema.QA) बनाई जाएगी
- उस फाइल पर राइट क्लिक करें और न्यू रिप्रेजेंटेशन, न्यू एंटिटी रिलेशन डायग्राम चुनें।
[3] ER आरेख के वे तत्व जो ऐसे मॉडलों को दर्शाते हैं, उनमें शामिल हैं:
- परिभाषित इकाई प्रकार
- परिभाषित विशेषताएं
- इकाई प्रकारों के बीच संबंध
- समग्र चित्र, या अवधारणात्मक आरेख
[4] IRI FACT और SQL*Loader क्रमशः बल्क एक्सट्रैक्शन और लोडिंग विकल्प हैं।



