स्पार्क ने 2009 में कैलिफोर्निया विश्वविद्यालय, बर्कले में AMPLab के भीतर एक परियोजना के रूप में जीवन शुरू किया। अधिक विशेष रूप से, यह मेसोस की अवधारणा को साबित करने की आवश्यकता से पैदा हुआ था, जिसे एएमपीलैब में भी बनाया गया था। स्पार्क पर सबसे पहले मेसोस श्वेत पत्र में चर्चा की गई थी जिसका शीर्षक था मेसोस:ए प्लेटफॉर्म फॉर फाइन-ग्रेन रिसोर्स शेयरिंग इन डेटा सेंटर, विशेष रूप से बेंजामिन हिंदमैन और माटेई ज़हरिया द्वारा लिखा गया था।
यह बड़े पैमाने पर डेटा का जटिल विश्लेषण करने के लिए एक तेज़ और सुविधाजनक समाधान के रूप में उभरा। स्पार्क बड़े डेटा के लिए एक नए प्रसंस्करण ढांचे के रूप में विकसित हुआ, जो MapReduce मॉडल की कई कमियों को दूर करता है। यह बड़े पैमाने पर डेटा विश्लेषण के लिए समर्थन करता है, और डेटा विभिन्न स्रोतों से हो सकता है जैसे वास्तविक समय, छवियों, ग्रंथों, ग्राफ़ और कई अन्य प्रारूपों में बैच प्रसंस्करण। अपने अपाचे स्पार्क कोर के अलावा, यह बड़े डेटा विश्लेषण के लिए कुछ उपयोगी पुस्तकालय भी प्रदान करता है।
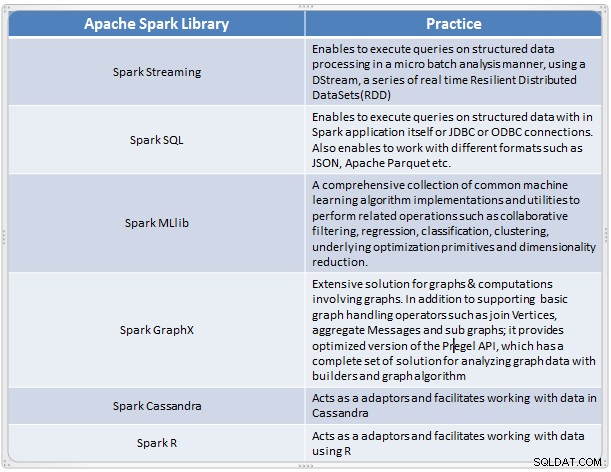
स्पार्क घटकों का अवलोकन
<मजबूत> 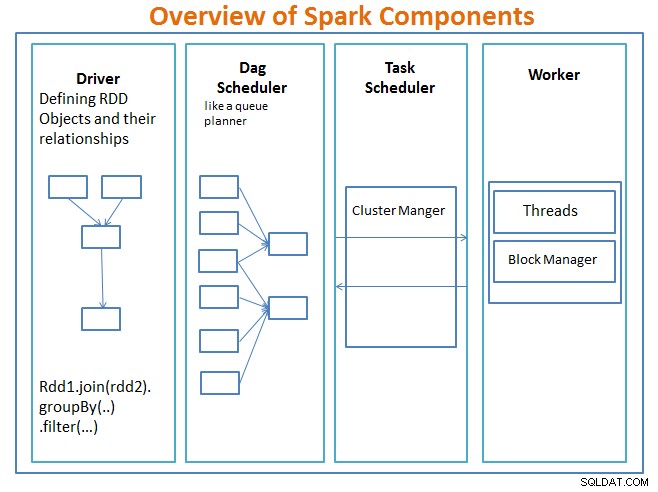
ड्राइवर वह कोड है जिसमें मुख्य कार्य शामिल है और लचीला वितरित डेटासेट (आरडीडी) और उनके परिवर्तनों को परिभाषित करता है। RDD मुख्य डेटा संरचनाएं हैं जिनका उपयोग हमारे स्पार्क कार्यक्रमों में किया जाएगा।
RDD पर समानांतर संचालन DAG अनुसूचक को भेजे जाते हैं , जो कोड को ऑप्टिमाइज़ करेगा और एक कुशल डीएजी तक पहुंचेगा जो एप्लिकेशन में डेटा प्रोसेसिंग चरणों का प्रतिनिधित्व करता है।
परिणामी डीएजी को क्लस्टर मैनेजर को भेजा जाता है। और क्लस्टर प्रबंधक के पास श्रमिकों, असाइन किए गए थ्रेड्स और डेटा ब्लॉकों के स्थान के बारे में जानकारी होती है और वह श्रमिकों को विशिष्ट प्रसंस्करण कार्य सौंपने के लिए जिम्मेदार होता है। यह कार्यकर्ता की विफलता के मामले में भी वापस संभालता है। क्लस्टर प्रबंधक YARN, Mesos, Spark का क्लस्टर प्रबंधक हो सकता है।
कार्यकर्ता प्रबंधन के लिए कार्य और डेटा की इकाइयाँ प्राप्त करता है और कार्यकर्ता संपूर्ण DAG की जानकारी के बिना अपने विशिष्ट कार्य को निष्पादित करता है और इसके परिणाम ड्राइवर अनुप्रयोगों को वापस भेजे जाते हैं।
स्पार्क, अन्य बड़े डेटा टूल की तरह, शक्तिशाली, सक्षम और है डेटा चुनौतियों की एक श्रृंखला से निपटने के लिए अच्छी तरह से अनुकूल है। स्पार्क, अन्य बड़ी डेटा तकनीकों की तरह, जरूरी नहीं कि प्रत्येक डेटा प्रोसेसिंग कार्य के लिए सबसे अच्छा विकल्प हो। , और उदाहरण के साथ स्पार्क का उपयोग करने के लाभ और स्पार्क का उपयोग कब करना है।
संदर्भ:
एकोडेमी और हडूप एप्लिकेशन आर्किटेक्चर द्वारा एक दिन में स्पार्क सीखें।



