सामान्य MySQL DBA अपने दैनिक दिनचर्या के हिस्से के रूप में OLTP (ऑनलाइन ट्रांजेक्शन प्रोसेसिंग) डेटाबेस को काम करने और प्रबंधित करने से परिचित हो सकता है। आप इससे परिचित हो सकते हैं कि यह कैसे काम करता है और जटिल कार्यों का प्रबंधन कैसे किया जाता है। जबकि डिफ़ॉल्ट स्टोरेज इंजन जो MySQL शिप करता है, OLAP (ऑनलाइन एनालिटिकल प्रोसेसिंग) के लिए काफी अच्छा है, यह काफी सरल है, खासकर वे जो आर्टिफिशियल इंटेलिजेंस सीखना चाहते हैं या जो पूर्वानुमान, डेटा माइनिंग, डेटा एनालिटिक्स से निपटते हैं।
इस ब्लॉग में, हम MariaDB ColumnStore पर चर्चा करने जा रहे हैं। सामग्री को MySQL DBA के लाभ के लिए तैयार किया जाएगा, जिन्हें ColumnStore के साथ कम समझ हो सकती है और यह OLAP (ऑनलाइन एनालिटिकल प्रोसेसिंग) अनुप्रयोगों के लिए कैसे लागू हो सकता है।
OLTP बनाम OLAP
OLTP
संबंधित संसाधन मारियाडीबी एएक्स के साथ एनालिटिक्स - ओपन सोर्स कॉलमनर डेटास्टोर समय सीरीज डेटाबेस का परिचय एसिंक्रोनस स्लेव्स का उपयोग करके गैलेरा क्लस्टर में हाइब्रिड ओएलटीपी/एनालिटिक्स डेटाबेस वर्कलोडइस प्रकार के डेटा से निपटने के लिए सामान्य MySQL DBA गतिविधि OLTP (ऑनलाइन लेनदेन प्रसंस्करण) का उपयोग कर रही है। OLTP को बड़े डेटाबेस लेनदेन द्वारा सम्मिलित, अद्यतन या हटाते हुए विशेषता है। ओएलटीपी-प्रकार के डेटाबेस तेजी से क्वेरी प्रसंस्करण और कई वातावरणों में एक्सेस किए जाने के दौरान डेटा अखंडता बनाए रखने के लिए विशिष्ट हैं। इसकी प्रभावशीलता प्रति सेकंड लेनदेन की संख्या (टीपीएस) द्वारा मापी जाती है। माता-पिता-बच्चे संबंध तालिकाओं (सामान्यीकरण प्रपत्र के कार्यान्वयन के बाद) के लिए तालिका में अनावश्यक डेटा को कम करना काफी सामान्य है।
एक तालिका में रिकॉर्ड्स को आमतौर पर एक पंक्ति-उन्मुख तरीके से क्रमिक रूप से संसाधित और संग्रहीत किया जाता है और डेटा पुनर्प्राप्ति या लिखने को अनुकूलित करने के लिए अद्वितीय कुंजियों के साथ अत्यधिक अनुक्रमित किया जाता है। यह MySQL के लिए भी सामान्य है, खासकर जब बड़े इंसर्ट या उच्च समवर्ती राइट्स या बल्क इंसर्ट से निपटते हैं। मारियाडीबी द्वारा समर्थित अधिकांश स्टोरेज इंजन ओएलटीपी अनुप्रयोगों के लिए लागू होते हैं - इनो डीबी (10.2 के बाद से डिफ़ॉल्ट स्टोरेज इंजन), एक्स्ट्राडीबी, टोकुडीबी, मायरॉक्स, या माईसाम/एरिया।
सीएमएस, फिनटेक, वेब ऐप्स जैसे एप्लिकेशन अक्सर भारी लिखने और पढ़ने से निपटते हैं और अक्सर उच्च थ्रूपुट की आवश्यकता होती है। इन अनुप्रयोगों को काम करने के लिए अक्सर उच्च उपलब्धता, अतिरेक, लचीलापन और पुनर्प्राप्ति में गहरी विशेषज्ञता की आवश्यकता होती है।
OLAP
OLAP OLTP जैसी ही चुनौतियों से निपटता है, लेकिन एक अलग दृष्टिकोण का उपयोग करता है (विशेषकर डेटा पुनर्प्राप्ति के साथ काम करते समय।) OLAP बड़े डेटासेट से संबंधित है और डेटा वेयरहाउसिंग के लिए सामान्य है, जिसे अक्सर व्यावसायिक खुफिया प्रकार के अनुप्रयोगों के लिए उपयोग किया जाता है। यह आमतौर पर व्यावसायिक प्रदर्शन प्रबंधन, योजना, बजट, पूर्वानुमान, वित्तीय रिपोर्टिंग, विश्लेषण, सिमुलेशन मॉडल, ज्ञान की खोज और डेटा वेयरहाउस रिपोर्टिंग के लिए उपयोग किया जाता है।
OLAP में संग्रहीत डेटा आमतौर पर उतना महत्वपूर्ण नहीं होता जितना कि OLTP में संग्रहीत होता है। ऐसा इसलिए है क्योंकि अधिकांश डेटा OLTP से आने वाले सिम्युलेटेड हो सकते हैं और फिर आपके OLAP डेटाबेस में फीड किए जा सकते हैं। यह डेटा आमतौर पर बल्क लोडिंग के लिए उपयोग किया जाता है, जिसे अक्सर व्यावसायिक विश्लेषण के लिए आवश्यक होता है जिसे अंततः विज़ुअल ग्राफ़ में प्रस्तुत किया जाता है। OLAP व्यावसायिक डेटा का बहुआयामी विश्लेषण भी करता है और ऐसे परिणाम देता है जिनका उपयोग जटिल गणना, प्रवृत्ति विश्लेषण या परिष्कृत डेटा मॉडलिंग के लिए किया जा सकता है।
OLAP आमतौर पर एक स्तंभ प्रारूप का उपयोग करके डेटा को लगातार संग्रहीत करता है। हालांकि, MariaDB ColumnStore में, इसके कॉलम के आधार पर रिकॉर्ड्स को तोड़ दिया जाता है और एक फाइल में अलग से स्टोर किया जाता है। इस तरह डेटा पुनर्प्राप्ति बहुत कुशल है, क्योंकि यह केवल आपके SELECT स्टेटमेंट क्वेरी में संदर्भित प्रासंगिक कॉलम को स्कैन करता है।
इसे इस तरह से सोचें, OLTP प्रसंस्करण आपके दैनिक और महत्वपूर्ण डेटा लेनदेन को संभालता है जो आपके व्यावसायिक अनुप्रयोग को चलाता है, जबकि OLAP आपको अपने उत्पाद का प्रबंधन, भविष्यवाणी, विश्लेषण और बेहतर विपणन करने में मदद करता है - एक व्यावसायिक अनुप्रयोग होने के निर्माण खंड।
MariaDB ColumnStore क्या है?
मारियाडीबी कॉलमस्टोर एक प्लग करने योग्य कॉलम स्टोरेज इंजन है जो मारियाडीबी सर्वर पर चलता है। मारियाडीबी सर्वर पोर्टफोलियो में उपयोग किए जाने वाले समान एएनएसआई एसक्यूएल इंटरफेस को रखते हुए यह समानांतर वितरित डेटा आर्किटेक्चर का उपयोग करता है। यह स्टोरेज इंजन कुछ समय के लिए आसपास रहा है, क्योंकि इसे मूल रूप से InfiniDB (अब एक निष्क्रिय कोड जो अभी भी github पर उपलब्ध है) से पोर्ट किया गया था। इसे बड़े डेटा स्केलिंग (डेटा के पेटबाइट्स को संसाधित करने के लिए), रैखिक मापनीयता और वास्तविक के लिए डिज़ाइन किया गया है। - विश्लेषिकी प्रश्नों के लिए समय की प्रतिक्रिया। यह स्तंभ भंडारण के I/O लाभों का लाभ उठाता है; बड़े डेटा सेट का विश्लेषण करते समय जबरदस्त प्रदर्शन देने के लिए संपीड़न, समय-समय पर प्रक्षेपण, और क्षैतिज और लंबवत विभाजन।
अंत में, MariaDB ColumnStore इस तकनीक द्वारा उपयोग किए जाने वाले मुख्य भंडारण इंजन के रूप में उनके MariaDB AX उत्पाद की रीढ़ है।
MariaDB ColumnStore InnoDB से किस प्रकार भिन्न है?
InnoDB OLTP प्रोसेसिंग के लिए लागू होता है जिसके लिए आपके एप्लिकेशन को सबसे तेज़ तरीके से प्रतिक्रिया करने की आवश्यकता होती है। यह उपयोगी है यदि आपका आवेदन उस प्रकृति से निपट रहा है। दूसरी ओर, मारियाडीबी कॉलमस्टोर बड़े डेटा लेनदेन या बड़े डेटा सेट के प्रबंधन के लिए एक उपयुक्त विकल्प है जिसमें जटिल जोड़, आयाम पदानुक्रम के विभिन्न स्तरों पर एकत्रीकरण, वर्षों की एक विस्तृत श्रृंखला के लिए वित्तीय कुल प्रोजेक्ट, या समानता और श्रेणी चयन का उपयोग करना शामिल है। . ColumnStore का उपयोग करने वाले इन तरीकों के लिए आपको इन क्षेत्रों को अनुक्रमित करने की आवश्यकता नहीं है, क्योंकि यह पर्याप्त रूप से तेज़ प्रदर्शन कर सकता है। InnoDB वास्तव में इस प्रकार के प्रदर्शन को संभाल नहीं सकता है, हालाँकि आपको यह कोशिश करने से कोई रोक नहीं सकता है जैसा कि InnoDB के साथ किया जा सकता है, लेकिन एक कीमत पर। इसके लिए आपको अनुक्रमणिका जोड़ने की आवश्यकता होती है, जो आपके डिस्क संग्रहण में बड़ी मात्रा में डेटा जोड़ता है। इसका मतलब है कि आपकी क्वेरी को समाप्त करने में अधिक समय लग सकता है, और यदि यह टाइम-लूप में फंस जाता है तो यह बिल्कुल भी समाप्त नहीं हो सकता है।
MariaDB ColumnStore आर्किटेक्चर
आइए नीचे दिए गए MariaDB ColumStore आर्किटेक्चर को देखें:
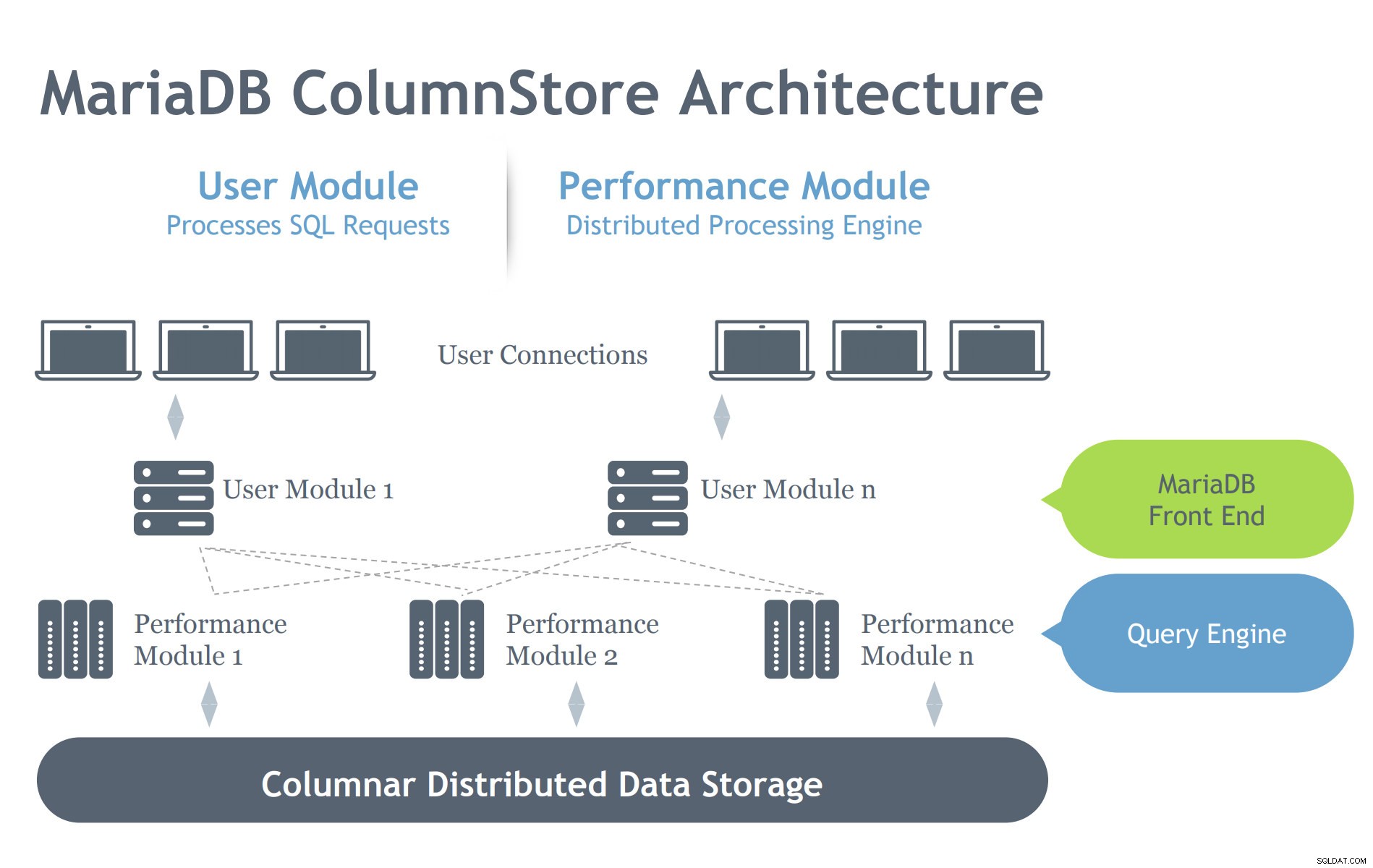 मारियाडीबी कॉलमस्टोर प्रस्तुति की छवि सौजन्य
मारियाडीबी कॉलमस्टोर प्रस्तुति की छवि सौजन्य InnoDB आर्किटेक्चर के विपरीत, ColumnStore में दो मॉड्यूल होते हैं जो दर्शाता है कि इसका इरादा एक वितरित वास्तुशिल्प वातावरण पर कुशलता से काम करना है। InnoDB का उद्देश्य सर्वर पर स्केल करना है, लेकिन क्लस्टर सेटअप के आधार पर कई-इंटरकनेक्टेड नोड्स पर फैला है। इसलिए, ColumnStore में कई स्तर के घटक हैं जो MariaDB सर्वर से अनुरोधित प्रक्रियाओं का ध्यान रखते हैं। आइए नीचे इन घटकों के बारे में जानें:
- उपयोगकर्ता मॉड्यूल (यूएम):यूएम एसक्यूएल अनुरोधों को एक या अधिक पीएम सर्वरों द्वारा निष्पादित आदिम नौकरी चरणों के अनुकूलित सेट में पार्स करने के लिए जिम्मेदार है। इस प्रकार UM क्वेरी ऑप्टिमाइज़ेशन और PM सर्वर द्वारा क्वेरी निष्पादन के ऑर्केस्ट्रेशन के लिए ज़िम्मेदार है। जबकि एक बहु-सर्वर परिनियोजन में एकाधिक UM इंस्टेंसेस को परिनियोजित किया जा सकता है, एक एकल UM प्रत्येक व्यक्तिगत क्वेरी के लिए ज़िम्मेदार होता है। एक डेटाबेस लोड बैलेंसर, जैसे मारियाडीबी मैक्सस्केल, को अलग-अलग यूएम सर्वरों के खिलाफ बाहरी अनुरोधों को उचित रूप से संतुलित करने के लिए तैनात किया जा सकता है।
- प्रदर्शन मॉड्यूल (पीएम):पीएम बहु-थ्रेडेड तरीके से यूएम से प्राप्त दानेदार नौकरी के चरणों को निष्पादित करता है। ColumnStore कई प्रदर्शन मॉड्यूल में काम के वितरण की अनुमति देता है। UM, MariaDB mysqld प्रक्रिया और ExeMgr प्रक्रिया से बना है।
- विस्तार मानचित्र:ColumnStore एक साझा वितरित वस्तु में प्रत्येक स्तंभ के बारे में मेटाडेटा रखता है जिसे विस्तार मानचित्र कहा जाता है। PM सर्वर पढ़ने के लिए सही डिस्क ब्लॉक की पहचान करने के लिए एक्स्टेंट मैप का संदर्भ देता है। प्रत्येक स्तंभ एक या अधिक फ़ाइलों से बना होता है और प्रत्येक फ़ाइल में कई विस्तार हो सकते हैं। सिस्टम पढ़ने के प्रदर्शन को बेहतर बनाने के लिए सन्निहित भौतिक भंडारण आवंटित करने का यथासंभव प्रयास करता है।
- भंडारण:ColumnStore डेटा स्टोर करने के लिए स्थानीय भंडारण या साझा भंडारण (जैसे SAN या EBS) का उपयोग कर सकता है। शेयर्ड स्टोरेज का उपयोग करने से डेटा प्रोसेसिंग एक पीएम सर्वर के विफल होने की स्थिति में स्वचालित रूप से दूसरे नोड पर विफल हो जाती है।
नीचे बताया गया है कि कैसे मारियाडीबी कॉलमस्टोर क्वेरी को संसाधित करता है,
- ग्राहक उपयोगकर्ता मॉड्यूल पर चल रहे मारियाडीबी सर्वर के लिए एक प्रश्न जारी करते हैं। सर्वर अनुरोध को पूरा करने के लिए आवश्यक सभी तालिकाओं के लिए एक टेबल ऑपरेशन करता है और प्रारंभिक क्वेरी निष्पादन योजना प्राप्त करता है।
- MariaDB स्टोरेज इंजन इंटरफ़ेस का उपयोग करते हुए, ColumnStore सर्वर टेबल ऑब्जेक्ट को ColumnStore ऑब्जेक्ट में कनवर्ट करता है। इन वस्तुओं को तब उपयोगकर्ता मॉड्यूल प्रक्रियाओं में भेजा जाता है।
- उपयोगकर्ता मॉड्यूल मारियाडीबी निष्पादन योजना को परिवर्तित करता है और दिए गए ऑब्जेक्ट को कॉलमस्टोर निष्पादन योजना में अनुकूलित करता है। यह तब क्वेरी को चलाने के लिए आवश्यक चरणों और उन्हें चलाने के लिए आवश्यक क्रम निर्धारित करता है।
- उपयोगकर्ता मॉड्यूल तब एक्स्टेंट मैप से परामर्श करता है ताकि यह निर्धारित किया जा सके कि कौन से प्रदर्शन मॉड्यूल को डेटा की आवश्यकता के लिए परामर्श करना है, फिर यह सूची से किसी भी प्रदर्शन मॉड्यूल को समाप्त करते हुए सीमा उन्मूलन करता है जिसमें केवल क्वेरी की आवश्यकता की सीमा के बाहर डेटा होता है।
- उपयोगकर्ता मॉड्यूल तब ब्लॉक I/O संचालन करने के लिए एक या अधिक प्रदर्शन मॉड्यूल को आदेश भेजता है।
- प्रदर्शन मॉड्यूल या मॉड्यूल विधेय फ़िल्टरिंग करते हैं, प्रसंस्करण में शामिल होते हैं, स्थानीय या बाहरी संग्रहण से डेटा का प्रारंभिक एकत्रीकरण करते हैं, फिर डेटा को उपयोगकर्ता मॉड्यूल में वापस भेजते हैं।
- उपयोगकर्ता मॉड्यूल अंतिम परिणाम-सेट एकत्रीकरण करता है और क्वेरी के लिए परिणाम-सेट तैयार करता है।
- उपयोगकर्ता मॉड्यूल / ExeMgr किसी भी विंडो फ़ंक्शन गणना, साथ ही परिणाम-सेट पर किसी भी आवश्यक सॉर्टिंग को लागू करता है। यह तब सर्वर पर परिणाम-सेट लौटाता है।
- MariaDB सर्वर परिणाम-सेट पर कोई भी चुनिंदा सूची कार्य, ORDER BY और LIMIT संचालन करता है।
- MariaDB सर्वर क्लाइंट को परिणाम-सेट लौटाता है।
क्वेरी निष्पादन प्रतिमान
आइए थोड़ा और जानें कि ColumnStore क्वेरी को कैसे निष्पादित करता है और यह कब प्रभावित होता है।
ColumnStore मानक MySQL/MariaDB स्टोरेज इंजन जैसे InnoDB से भिन्न है क्योंकि ColumnStore केवल आवश्यक कॉलम स्कैन करके, सिस्टम मेंटेन किए गए विभाजन का उपयोग करके, और क्वेरी प्रतिक्रिया समय को स्केल करने के लिए कई थ्रेड्स और सर्वरों का उपयोग करके प्रदर्शन प्राप्त करता है। प्रदर्शन तब लाभान्वित होता है जब आप केवल उन स्तंभों को शामिल करते हैं जो आपके डेटा पुनर्प्राप्ति के लिए आवश्यक होते हैं। इसका मतलब है कि आपकी चयनित क्वेरी में लालची तारक (*) का चयन
InnoDB और अन्य स्टोरेज इंजनों की तरह ही, डेटा प्रकार का भी आपके द्वारा उपयोग किए जाने वाले प्रदर्शन में महत्व है। यदि कहें कि आपके पास एक कॉलम है जिसमें केवल 0 से 100 मान हो सकते हैं तो इसे एक छोटे से के रूप में घोषित करें क्योंकि इसे int के लिए 4 बाइट्स के बजाय 1 बाइट के साथ दर्शाया जाएगा। इससे I/O लागत 4 गुना कम हो जाएगी। स्ट्रिंग प्रकारों के लिए एक महत्वपूर्ण दहलीज चार (9) और वर्कर (8) या अधिक है। प्रत्येक स्तंभ संग्रहण फ़ाइल प्रति मान बाइट्स की एक निश्चित संख्या का उपयोग करती है। यह पंक्ति बनाने के लिए अन्य स्तंभों के तेजी से स्थितीय लुकअप को सक्षम बनाता है। वर्तमान में स्तंभ डेटा संग्रहण की ऊपरी सीमा 8 बाइट्स है। तो इससे अधिक लंबे तार के लिए सिस्टम एक अतिरिक्त 'शब्दकोश' सीमा बनाए रखता है जहां मान संग्रहीत होते हैं। स्तंभ सीमा फ़ाइल तब एक सूचक को शब्दकोश में संग्रहीत करती है। इसलिए उदाहरण के लिए चार (8) कॉलम की तुलना में वर्चर (8) कॉलम को पढ़ना और संसाधित करना अधिक महंगा है। तो जहां संभव हो आपको बेहतर प्रदर्शन मिलेगा यदि आप छोटे तारों का उपयोग कर सकते हैं, खासकर यदि आप डिक्शनरी लुकअप से बचते हैं। 1.1 के बाद के सभी टेक्स्ट/ब्लॉब डेटा प्रकार एक डिक्शनरी का उपयोग करते हैं और यदि आवश्यक हो तो उस डेटा को पुनः प्राप्त करने के लिए एक से अधिक ब्लॉक 8KB लुकअप करते हैं, जितना अधिक डेटा अधिक ब्लॉक पुनर्प्राप्त किया जाता है और एक संभावित प्रदर्शन प्रभाव जितना अधिक होता है।
एक पंक्ति आधारित प्रणाली में अनावश्यक कॉलम जोड़ने से समग्र क्वेरी लागत में वृद्धि होती है, लेकिन एक कॉलम सिस्टम में एक लागत केवल तभी होती है जब कॉलम को संदर्भित किया जाता है। इसलिए विभिन्न पहुंच पथों का समर्थन करने के लिए अतिरिक्त कॉलम बनाए जाने चाहिए। उदाहरण के लिए, तेजी से लुकअप की अनुमति देने के लिए किसी फ़ील्ड के एक प्रमुख भाग को एक कॉलम में स्टोर करें, लेकिन इसके अलावा लॉन्ग फॉर्म वैल्यू को दूसरे कॉलम के रूप में स्टोर करें। छोटे कोड या प्रमुख हिस्से वाले कॉलम पर स्कैन तेजी से होंगे।
क्वेरी जॉइन बड़े पैमाने पर जुड़ने के लिए अनुकूलित-तैयार हैं और इंडेक्स और नेस्टेड लूप प्रोसेसिंग के ओवरहेड की आवश्यकता से बचते हैं। ColumnStore तालिका के आँकड़े रखता है ताकि इष्टतम जुड़ाव क्रम निर्धारित किया जा सके। समान दृष्टिकोण InnoDB के साथ साझा करता है जैसे कि यदि UM मेमोरी के लिए जुड़ाव बहुत बड़ा है, तो यह क्वेरी को पूरा करने के लिए डिस्क-आधारित जुड़ाव का उपयोग करता है।
एकत्रीकरण के लिए, ColumnStore यथासंभव समग्र मूल्यांकन वितरित करता है। इसका मतलब यह है कि यह विशेष रूप से या कुल कॉलम (स्तंभों) में बहुत बड़ी संख्या में प्रश्नों को संभालने के लिए यूएम और पीएम में साझा करता है। तालिका में बाइट संग्रहण की न्यूनतम संख्या चुनने के लिए चयन गिनती (*) आंतरिक रूप से अनुकूलित है। इसका मतलब है कि यह INT कॉलम के ऊपर CHAR(1) कॉलम (1 बाइट का उपयोग करता है) चुनेंगे जो 4 बाइट्स लेता है। कार्यान्वयन अभी भी उस चुनिंदा गिनती (*) में एएनएसआई शब्दार्थ का सम्मान करता है, जिसमें एक स्पष्ट चयन (COL-N) के विपरीत कुल संख्या में नल शामिल होंगे, जो गिनती में नल को बाहर करता है।
अस्थायी परिणाम सेट तालिका पर मारियाडब सर्वर प्रक्रिया द्वारा वर्तमान में आदेश और सीमा को बहुत अंत में लागू किया गया है। ColumnStore क्वेरी को कैसे प्रोसेस करता है, इस पर चरण #9 में इसका उल्लेख किया गया है। इसलिए तकनीकी रूप से, डेटा को सॉर्ट करने के लिए परिणाम मारियाडीबी सर्वर को पास कर दिए जाते हैं।
सबक्वेरी का उपयोग करने वाले जटिल प्रश्नों के लिए, यह मूल रूप से वही तरीका है जहां अनुक्रम में निष्पादित किया जाता है और UM द्वारा प्रबंधित किया जाता है, ठीक वैसे ही जैसे विंडो फ़ंक्शंस को UM द्वारा नियंत्रित किया जाता है, लेकिन यह एक समर्पित तेज़ सॉर्ट प्रक्रिया का उपयोग करता है, इसलिए यह मूल रूप से तेज़ है।
आपके डेटा का विभाजन ColumnStore द्वारा प्रदान किया जाता है, जो यह एक्स्टेंट मैप्स का उपयोग करता है जो कॉलम डेटा के न्यूनतम/अधिकतम मानों को बनाए रखता है और विभाजन के लिए एक तार्किक सीमा प्रदान करता है और अनुक्रमण की आवश्यकता को दूर करता है। एक्स्टेंट मैप्स मैनुअल टेबल विभाजन, भौतिक दृश्य, सारांश टेबल और अन्य संरचनाएं और ऑब्जेक्ट भी प्रदान करता है जो पंक्ति-आधारित डेटाबेस को क्वेरी प्रदर्शन के लिए लागू करना चाहिए। स्तंभित मानों के लिए कुछ लाभ होते हैं जब वे क्रम में या अर्ध-क्रम में होते हैं क्योंकि यह बहुत प्रभावी डेटा विभाजन की अनुमति देता है। न्यूनतम और अधिकतम मानों के साथ, फ़िल्टर और बहिष्करण के बाद के संपूर्ण मानचित्रों को हटा दिया जाएगा। एक्स्टेंट एलिमिनेशन के बारे में उनके मैनुअल में इस पेज को देखें। यह आम तौर पर समय-श्रृंखला डेटा या समय के साथ बढ़ने वाले समान मूल्यों के लिए विशेष रूप से अच्छी तरह से काम करता है।
MariaDB ColumnStore इंस्टाल करना
मारियाडीबी कॉलमस्टोर को स्थापित करना सरल और सीधा हो सकता है। मारियाडीबी के पास यहां नोट्स की एक श्रृंखला है जिसका आप उल्लेख कर सकते हैं। इस ब्लॉग के लिए, हमारा इंस्टॉलेशन लक्ष्य वातावरण CentOS 7 है। आप इस लिंक https://downloads.mariadb.com/ColumnStore/1.2.4/ पर जा सकते हैं और अपने OS परिवेश के आधार पर पैकेज देख सकते हैं। गति बढ़ाने में आपकी सहायता के लिए नीचे दिए गए विस्तृत चरण देखें:
### Note: The installation details is ideal for root user installation
cd /root/
wget https://downloads.mariadb.com/ColumnStore/1.2.4/centos/x86_64/7/mariadb-columnstore-1.2.4-1-centos7.x86_64.rpm.tar.gz
tar xzf mariadb-columnstore-1.0.7-1-centos7.x86_64.rpm.tar.gz
sudo yum -y install boost expect perl perl-DBI openssl zlib snappy libaio perl-DBD-MySQL net-tools wget jemalloc
sudo rpm -ivh mariadb-columnstore*.rpm
एक बार हो जाने के बाद, आपको postConfigure run चलाना होगा अंत में अपने MariaDB ColumnStore को स्थापित और सेटअप करने का आदेश दें। इस नमूना स्थापना में, मेरे पास दो नोड हैं जो योनि मशीन पर चल रहे हैं:
csnode1:192.168.2.10
csnode2:192.168.2.20
इन दोनों नोड्स को इसके संबंधित / etc / मेजबानों में परिभाषित किया गया है और दोनों नोड्स को लक्षित किया गया है ताकि इसके उपयोगकर्ता और प्रदर्शन मॉड्यूल दोनों मेजबानों में संयुक्त हों। स्थापना पहली बार में थोड़ी तुच्छ है। इसलिए, हम साझा करते हैं कि आप इसे कैसे कॉन्फ़िगर कर सकते हैं ताकि आपके पास आधार हो। नमूना स्थापना प्रक्रिया के लिए नीचे विवरण देखें:
[example@sqldat.com ~]# /usr/local/mariadb/columnstore/bin/postConfigure -d
This is the MariaDB ColumnStore System Configuration and Installation tool.
It will Configure the MariaDB ColumnStore System and will perform a Package
Installation of all of the Servers within the System that is being configured.
IMPORTANT: This tool requires to run on the Performance Module #1
Prompting instructions:
Press 'enter' to accept a value in (), if available or
Enter one of the options within [], if available, or
Enter a new value
===== Setup System Server Type Configuration =====
There are 2 options when configuring the System Server Type: single and multi
'single' - Single-Server install is used when there will only be 1 server configured
on the system. It can also be used for production systems, if the plan is
to stay single-server.
'multi' - Multi-Server install is used when you want to configure multiple servers now or
in the future. With Multi-Server install, you can still configure just 1 server
now and add on addition servers/modules in the future.
Select the type of System Server install [1=single, 2=multi] (2) >
===== Setup System Module Type Configuration =====
There are 2 options when configuring the System Module Type: separate and combined
'separate' - User and Performance functionality on separate servers.
'combined' - User and Performance functionality on the same server
Select the type of System Module Install [1=separate, 2=combined] (1) > 2
Combined Server Installation will be performed.
The Server will be configured as a Performance Module.
All MariaDB ColumnStore Processes will run on the Performance Modules.
NOTE: The MariaDB ColumnStore Schema Sync feature will replicate all of the
schemas and InnoDB tables across the User Module nodes. This feature can be enabled
or disabled, for example, if you wish to configure your own replication post installation.
MariaDB ColumnStore Schema Sync feature, do you want to enable? [y,n] (y) >
NOTE: MariaDB ColumnStore Replication Feature is enabled
Enter System Name (columnstore-1) >
===== Setup Storage Configuration =====
----- Setup Performance Module DBRoot Data Storage Mount Configuration -----
There are 2 options when configuring the storage: internal or external
'internal' - This is specified when a local disk is used for the DBRoot storage.
High Availability Server Failover is not Supported in this mode
'external' - This is specified when the DBRoot directories are mounted.
High Availability Server Failover is Supported in this mode.
Select the type of Data Storage [1=internal, 2=external] (1) >
===== Setup Memory Configuration =====
NOTE: Setting 'NumBlocksPct' to 50%
Setting 'TotalUmMemory' to 25%
===== Setup the Module Configuration =====
----- Performance Module Configuration -----
Enter number of Performance Modules [1,1024] (1) > 2
*** Parent OAM Module Performance Module #1 Configuration ***
Enter Nic Interface #1 Host Name (csnode1) >
Enter Nic Interface #1 IP Address or hostname of csnode1 (unassigned) > 192.168.2.10
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm1' (1) >
*** Performance Module #2 Configuration ***
Enter Nic Interface #1 Host Name (unassigned) > csnode2
Enter Nic Interface #1 IP Address or hostname of csnode2 (192.168.2.20) >
Enter Nic Interface #2 Host Name (unassigned) >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () >
Enter the list (Nx,Ny,Nz) or range (Nx-Nz) of DBRoot IDs assigned to module 'pm2' () > 2
===== Running the MariaDB ColumnStore MariaDB Server setup scripts =====
post-mysqld-install Successfully Completed
post-mysql-install Successfully Completed
Next step is to enter the password to access the other Servers.
This is either user password or you can default to using a ssh key
If using a user password, the password needs to be the same on all Servers.
Enter password, hit 'enter' to default to using a ssh key, or 'exit' >
===== System Installation =====
System Configuration is complete.
Performing System Installation.
Performing a MariaDB ColumnStore System install using RPM packages
located in the /root directory.
----- Performing Install on 'pm2 / csnode2' -----
Install log file is located here: /tmp/columnstore_tmp_files/pm2_rpm_install.log
MariaDB ColumnStore Package being installed, please wait ... DONE
===== Checking MariaDB ColumnStore System Logging Functionality =====
The MariaDB ColumnStore system logging is setup and working on local server
===== MariaDB ColumnStore System Startup =====
System Configuration is complete.
Performing System Installation.
----- Starting MariaDB ColumnStore on local server -----
MariaDB ColumnStore successfully started
MariaDB ColumnStore Database Platform Starting, please wait .......... DONE
System Catalog Successfully Created
Run MariaDB ColumnStore Replication Setup.. DONE
MariaDB ColumnStore Install Successfully Completed, System is Active
Enter the following command to define MariaDB ColumnStore Alias Commands
. /etc/profile.d/columnstoreAlias.sh
Enter 'mcsmysql' to access the MariaDB ColumnStore SQL console
Enter 'mcsadmin' to access the MariaDB ColumnStore Admin console
NOTE: The MariaDB ColumnStore Alias Commands are in /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]# . /etc/profile.d/columnstoreAlias.sh
[example@sqldat.com ~]#एक बार इंस्टॉलेशन और सेटअप हो जाने के बाद, मारियाडीबी इसके लिए एक मास्टर/स्लेव सेटअप तैयार करेगा, इसलिए हमने जो कुछ भी csnode1 से लोड किया है, उसे csnode2 में दोहराया जाएगा।
अपना बड़ा डेटा डंप करना
आपकी स्थापना के बाद, आपके पास कोशिश करने के लिए कोई नमूना डेटा नहीं हो सकता है। आईएमडीबी ने एक नमूना डेटा साझा किया है जिसे आप उनकी साइट https://www.imdb.com/interfaces/ पर डाउनलोड कर सकते हैं। इस ब्लॉग के लिए, मैंने एक स्क्रिप्ट बनाई है जो आपके लिए सब कुछ करती है। इसे यहां देखें https://github.com/paulnamuag/columnstore-imdb-data-load। बस इसे निष्पादन योग्य बनाएं, फिर स्क्रिप्ट चलाएँ। यह फाइलों को डाउनलोड करके, स्कीमा बनाकर, फिर डेटाबेस में डेटा लोड करके आपके लिए सब कुछ करेगा। यह इतना आसान है।
अपनी नमूना क्वेरी चलाना
अब, कुछ नमूना क्वेरी चलाने का प्रयास करते हैं।
MariaDB [imdb]> select count(1), 'title_akas' table_name from title_akas union all select count(1), 'name_basics' as table_name from name_basics union all select count(1), 'title_crew' as table_name from title_crew union all select count(1), 'title_episode' as table_name from title_episode union all select count(1), 'title_ratings' as table_name from title_ratings order by 1 asc;
+----------+---------------+
| count(1) | table_name |
+----------+---------------+
| 945057 | title_ratings |
| 3797618 | title_akas |
| 4136880 | title_episode |
| 5953930 | title_crew |
| 9403540 | name_basics |
+----------+---------------+
5 rows in set (0.162 sec)MariaDB [imdb]> select count(*), 'title_akas' table_name from title_akas union all select count(*), 'name_basics' as table_name from name_basics union all select count(*), 'title_crew' as table_name from title_crew union all select count(*), 'title_episode' as table_name from title_episode union all select count(*), 'title_ratings' as table_name from title_ratings order by 2;
+----------+---------------+
| count(*) | table_name |
+----------+---------------+
| 9405192 | name_basics |
| 3797618 | title_akas |
| 5953930 | title_crew |
| 4136880 | title_episode |
| 945057 | title_ratings |
+----------+---------------+
5 rows in set (0.371 sec)मूल रूप से, यह तेज़ और तेज़ है। ऐसे प्रश्न हैं जिन्हें आप संसाधित नहीं कर सकते हैं जो आप अन्य स्टोरेज इंजनों के साथ चलाते हैं, जैसे कि InnoDB। उदाहरण के लिए, मैंने इधर-उधर खेलने की कोशिश की और कुछ मूर्खतापूर्ण प्रश्न किए और देखा कि यह कैसे प्रतिक्रिया करता है और इसका परिणाम होता है:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select a.titleId from title_akas) limit 25;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'title_akas' are not joined.इसलिए, मुझे MCOL-1620 और MCOL-131 मिला और यह infinidb_vtable_mode चर सेट करने की ओर इशारा करता है। नीचे देखें:
MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
ERROR 1815 (HY000): Internal error: IDB-1000: 'a' and 'b, sub-query' are not joined.लेकिन सेटिंग infinidb_vtable_mode=0 , जिसका अर्थ है कि यह क्वेरी को सामान्य और अत्यधिक संगत पंक्ति-दर-पंक्ति प्रसंस्करण मोड के रूप में मानता है। कुछ WHERE क्लॉज कंपोनेंट्स को ColumnStore द्वारा प्रोसेस किया जा सकता है, लेकिन जॉइन को नेस्टेड-लूप जॉइन मैकेनिज्म का उपयोग करके पूरी तरह से mysqld द्वारा प्रोसेस किया जाता है। नीचे देखें:
MariaDB [imdb]> set infinidb_vtable_mode=0;
Query OK, 0 rows affected (0.000 sec)MariaDB [imdb]> select a.titleId, a.title, a.region, b.id, b.primaryName, b.profession from title_akas a join name_basics b where b.knownForTitles in (select c.titleId from title_akas c) limit 2;
+-----------+---------------+--------+-----------+-------------+---------------+
| titleId | title | region | id | primaryName | profession |
+-----------+---------------+--------+-----------+-------------+---------------+
| tt0082880 | Vaticano Show | ES | nm0594213 | Velda Mitzi | miscellaneous |
| tt0082880 | Il pap'occhio | IT | nm0594213 | Velda Mitzi | miscellaneous |
+-----------+---------------+--------+-----------+-------------+---------------+
2 rows in set (13.789 sec)हालांकि इसमें कुछ समय लगा क्योंकि यह बताता है कि यह पूरी तरह से mysqld द्वारा संसाधित है। फिर भी, अच्छे प्रश्नों को अनुकूलित करना और लिखना अभी भी सबसे अच्छा तरीका है और ColumnStore को सब कुछ नहीं सौंपना।
इसके अतिरिक्त, आपको सिलेक्ट कैलसेटट्रेस(1); जैसे कमांड चलाकर अपने प्रश्नों का विश्लेषण करने में कुछ मदद मिलती है। या calGetStats() चुनें; . आप कमांड के इन सेट का उपयोग कर सकते हैं, उदाहरण के लिए, निम्न और खराब प्रश्नों को अनुकूलित करें या इसकी क्वेरी योजना देखें। प्रश्नों के विश्लेषण के बारे में अधिक जानकारी के लिए इसे यहां देखें।
कॉलमस्टोर का व्यवस्थापन
एक बार जब आप MariaDB ColumnStore को पूरी तरह से सेटअप कर लेते हैं, तो यह mcsadmin नाम के अपने टूल के साथ शिप हो जाता है, जिसके लिए आप कुछ प्रशासनिक कार्यों को करने के लिए उपयोग कर सकते हैं। आप इस टूल का उपयोग किसी अन्य मॉड्यूल को जोड़ने, PM से PM तक DBroots को असाइन करने या स्थानांतरित करने आदि के लिए भी कर सकते हैं। इस टूल के बारे में उनका मैनुअल देखें।
मूल रूप से, आप निम्न कार्य कर सकते हैं, उदाहरण के लिए, सिस्टम जानकारी की जाँच करना:
mcsadmin> getSystemi
getsysteminfo Mon Jun 24 12:55:25 2019
System columnstore-1
System and Module statuses
Component Status Last Status Change
------------ -------------------------- ------------------------
System ACTIVE Fri Jun 21 21:40:56 2019
Module pm1 ACTIVE Fri Jun 21 21:40:54 2019
Module pm2 ACTIVE Fri Jun 21 21:40:50 2019
Active Parent OAM Performance Module is 'pm1'
Primary Front-End MariaDB ColumnStore Module is 'pm1'
MariaDB ColumnStore Replication Feature is enabled
MariaDB ColumnStore set for Distributed Install
MariaDB ColumnStore Process statuses
Process Module Status Last Status Change Process ID
------------------ ------ --------------- ------------------------ ----------
ProcessMonitor pm1 ACTIVE Thu Jun 20 17:36:27 2019 6026
ProcessManager pm1 ACTIVE Thu Jun 20 17:36:33 2019 6165
DBRMControllerNode pm1 ACTIVE Fri Jun 21 21:40:31 2019 19890
ServerMonitor pm1 ACTIVE Fri Jun 21 21:40:33 2019 19955
DBRMWorkerNode pm1 ACTIVE Fri Jun 21 21:40:33 2019 20003
PrimProc pm1 ACTIVE Fri Jun 21 21:40:37 2019 20137
ExeMgr pm1 ACTIVE Fri Jun 21 21:40:42 2019 20541
WriteEngineServer pm1 ACTIVE Fri Jun 21 21:40:47 2019 20660
DDLProc pm1 ACTIVE Fri Jun 21 21:40:51 2019 20810
DMLProc pm1 ACTIVE Fri Jun 21 21:40:55 2019 20956
mysqld pm1 ACTIVE Fri Jun 21 21:40:41 2019 19778
ProcessMonitor pm2 ACTIVE Thu Jun 20 17:37:16 2019 9728
ProcessManager pm2 HOT_STANDBY Fri Jun 21 21:40:26 2019 25211
DBRMControllerNode pm2 COLD_STANDBY Fri Jun 21 21:40:32 2019
ServerMonitor pm2 ACTIVE Fri Jun 21 21:40:35 2019 25560
DBRMWorkerNode pm2 ACTIVE Fri Jun 21 21:40:36 2019 25593
PrimProc pm2 ACTIVE Fri Jun 21 21:40:40 2019 25642
ExeMgr pm2 ACTIVE Fri Jun 21 21:40:44 2019 25715
WriteEngineServer pm2 ACTIVE Fri Jun 21 21:40:48 2019 25768
DDLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
DMLProc pm2 COLD_STANDBY Fri Jun 21 21:40:50 2019
mysqld pm2 ACTIVE Fri Jun 21 21:40:32 2019 25467
Active Alarm Counts: Critical = 1, Major = 0, Minor = 0, Warning = 0, Info = 0निष्कर्ष
MariaDB ColumnStore आपके OLAP और बड़े डेटा प्रोसेसिंग के लिए एक बहुत शक्तिशाली स्टोरेज इंजन है। यह पूरी तरह से खुला स्रोत है जो बाजार में उपलब्ध मालिकाना और महंगे OLAP डेटाबेस का उपयोग करने की तुलना में उपयोग करने के लिए बहुत फायदेमंद है। फिर भी, कोशिश करने के लिए अन्य विकल्प भी हैं जैसे ClickHouse, Apache HBase, या साइटस डेटा का cstore_fdw। हालांकि, इनमें से कोई भी MySQL/MariaDB का उपयोग नहीं कर रहा है, इसलिए यदि आप MySQL/MariaDB वेरिएंट पर बने रहना चुनते हैं तो यह आपके लिए व्यवहार्य विकल्प नहीं हो सकता है।