आपने "स्प्लिट ब्रेन" शब्द के बारे में सुना होगा। यह क्या है? यह आपके समूहों को कैसे प्रभावित करता है? इस ब्लॉग पोस्ट में हम चर्चा करेंगे कि वास्तव में यह क्या है, यह आपके डेटाबेस के लिए क्या खतरा पैदा कर सकता है, हम इसे कैसे रोक सकते हैं, और अगर सब कुछ गलत हो जाता है, तो इससे कैसे उबरें।
लंबे समय से एकल उदाहरणों के दिन चले गए हैं, आजकल लगभग सभी डेटाबेस प्रतिकृति समूहों या समूहों में चलते हैं। यह उच्च उपलब्धता और मापनीयता के लिए बहुत अच्छा है, लेकिन एक वितरित डेटाबेस नए खतरों और सीमाओं का परिचय देता है। एक मामला जो घातक हो सकता है वह है नेटवर्क स्प्लिट। कई नोड्स के एक समूह की कल्पना करें, जो नेटवर्क समस्याओं के कारण दो भागों में विभाजित हो गया था। स्पष्ट कारणों (डेटा संगतता) के लिए, दोनों भागों को एक ही समय में ट्रैफ़िक को संभालना नहीं चाहिए क्योंकि वे एक-दूसरे से अलग-थलग हैं और उनके बीच डेटा स्थानांतरित नहीं किया जा सकता है। यह एप्लिकेशन के दृष्टिकोण से भी गलत है - भले ही, अंततः, डेटा को सिंक करने का एक तरीका होगा (हालांकि 2 डेटासेट का सामंजस्य तुच्छ नहीं है)। कुछ समय के लिए, एप्लिकेशन का हिस्सा अन्य एप्लिकेशन होस्ट द्वारा किए गए परिवर्तनों से अनजान होगा, जो डेटाबेस क्लस्टर के दूसरे भाग तक पहुंचता है। इससे गंभीर समस्याएं हो सकती हैं।
जिस स्थिति में क्लस्टर को दो या दो से अधिक भागों में विभाजित किया गया है, जो लिखने को स्वीकार करने के लिए तैयार हैं, उसे "स्प्लिट ब्रेन" कहा जाता है।
विभाजित मस्तिष्क के साथ सबसे बड़ी समस्या डेटा बहाव है, जैसा कि क्लस्टर के दोनों हिस्सों पर होता है। MySQL फ्लेवर में से कोई भी डायवर्ज किए गए डेटासेट को मर्ज करने के स्वचालित साधन प्रदान नहीं करता है। आपको MySQL प्रतिकृति, समूह प्रतिकृति या गैलेरा में ऐसी सुविधा नहीं मिलेगी। एक बार डेटा अलग हो जाने के बाद, एकमात्र विकल्प यह है कि या तो क्लस्टर के किसी एक हिस्से को सत्य के स्रोत के रूप में उपयोग किया जाए और दूसरे भाग पर किए गए परिवर्तनों को त्याग दिया जाए - जब तक कि हम डेटा को मर्ज करने के लिए कुछ मैन्युअल प्रक्रिया का पालन नहीं कर सकते।
यही कारण है कि हम शुरू करेंगे कि कैसे विभाजित मस्तिष्क को होने से रोका जाए। किसी भी डेटा विसंगति को ठीक करने की तुलना में यह बहुत आसान है।
विभाजित मस्तिष्क को कैसे रोकें
सटीक समाधान डेटाबेस के प्रकार और पर्यावरण की स्थापना पर निर्भर करता है। हम गैलेरा क्लस्टर और MySQL प्रतिकृति के कुछ सबसे सामान्य मामलों पर एक नज़र डालेंगे।
गैलेरा क्लस्टर
विभाजित मस्तिष्क को संभालने के लिए गैलेरा में एक अंतर्निहित "सर्किट ब्रेकर" है:यह एक कोरम तंत्र पर निर्भर करता है। यदि क्लस्टर में अधिकांश नोड्स (50% + 1) उपलब्ध हैं, तो गैलेरा सामान्य रूप से काम करेगा। यदि बहुमत नहीं है, तो गैलेरा यातायात की सेवा बंद कर देगा और तथाकथित "गैर-प्राथमिक" राज्य में बदल जाएगा। गैलेरा का उपयोग करते समय विभाजित मस्तिष्क की स्थिति से निपटने के लिए आपको बस इतना ही करना होगा। निश्चित रूप से, बहुमत न होने पर भी गैलेरा को "प्राथमिक" स्थिति में मजबूर करने के लिए मैन्युअल तरीके हैं। बात यह है कि, जब तक आप ऐसा नहीं करते, आपको सुरक्षित रहना चाहिए।
जिस तरह से कोरम की गणना की जाती है, उसके महत्वपूर्ण परिणाम होते हैं - एकल डेटासेंटर स्तर पर, आप विषम संख्या में नोड्स रखना चाहते हैं। तीन नोड आपको एक नोड की विफलता के लिए सहनशीलता देते हैं (क्लस्टर में उपलब्ध होने वाले नोड्स के 50% से अधिक की आवश्यकता से 2 नोड्स मेल खाते हैं)। पांच नोड्स आपको दो नोड्स (5 - 2 =3 जो कि 5 नोड्स से 50% से अधिक है) की विफलता के लिए सहिष्णुता प्रदान करेंगे। दूसरी ओर, चार नोड्स का उपयोग करने से तीन नोड क्लस्टर पर आपकी सहनशीलता में सुधार नहीं होगा। यह अभी भी केवल एक नोड (4 - 1 =3, 4 से 50% से अधिक) की विफलता को संभालेगा, जबकि दो नोड्स की विफलता क्लस्टर को अनुपयोगी बना देगी (4 - 2 =2, केवल 50%, अधिक नहीं)।
गैलेरा क्लस्टर को एक ही डेटासेंटर में तैनात करते समय, कृपया ध्यान रखें कि, आदर्श रूप से, आप कई उपलब्धता क्षेत्रों (अलग बिजली स्रोत, नेटवर्क, आदि) में नोड्स वितरित करना चाहेंगे - जब तक कि वे आपके डेटासेंटर में मौजूद हैं, अर्थात . एक साधारण सेटअप नीचे जैसा दिख सकता है:
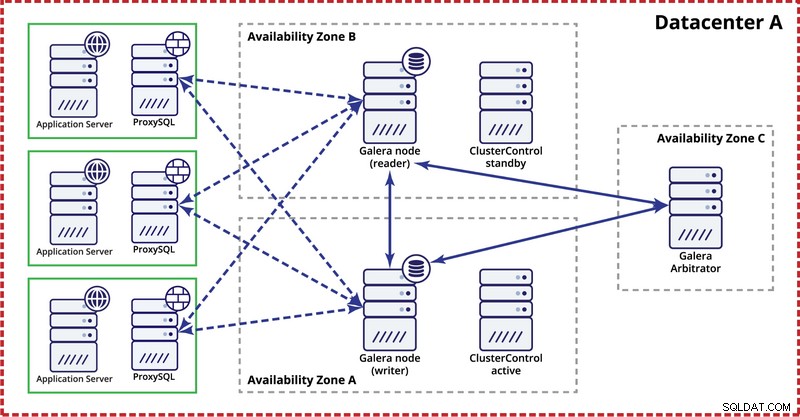
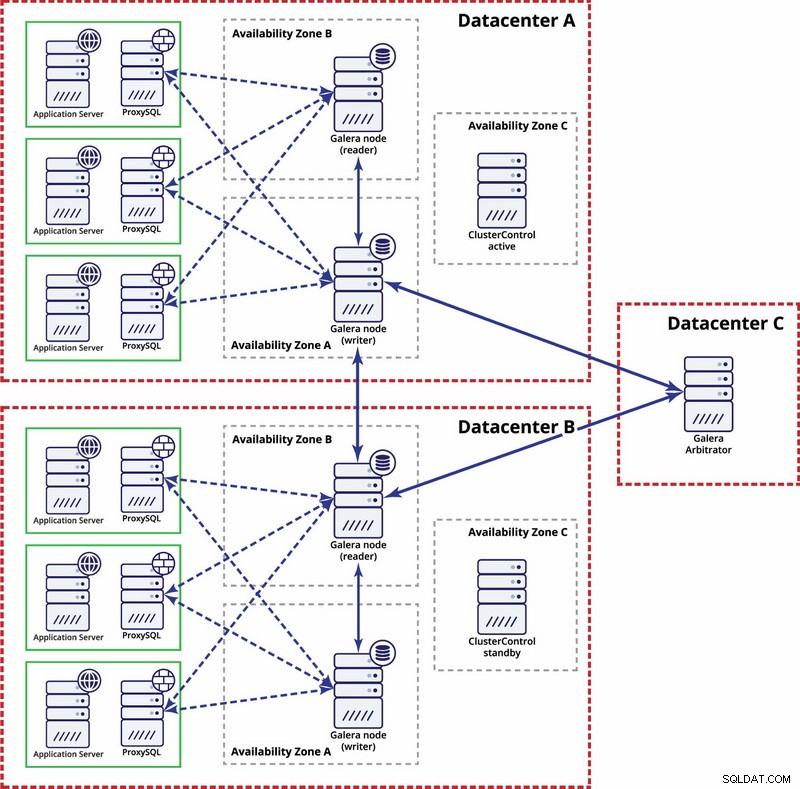
बहु-डेटासेंटर स्तर पर, वे विचार भी लागू होते हैं। यदि आप चाहते हैं कि गैलेरा क्लस्टर स्वचालित रूप से डेटासेंटर विफलताओं को संभाले, तो आपको विषम संख्या में डेटासेंटर का उपयोग करना चाहिए। लागत कम करने के लिए, आप डेटाबेस नोड के बजाय उनमें से किसी एक में गैलेरा मध्यस्थ का उपयोग कर सकते हैं। गैलेरा मध्यस्थ (गारबड) एक प्रक्रिया है जो कोरम गणना में भाग लेती है लेकिन इसमें कोई डेटा नहीं होता है। यह बहुत छोटे उदाहरणों पर भी इसका उपयोग करना संभव बनाता है क्योंकि यह संसाधन-गहन नहीं है - हालाँकि नेटवर्क कनेक्टिविटी को अच्छा होना चाहिए क्योंकि यह सभी प्रतिकृति ट्रैफ़िक को 'देखता' है। उदाहरण सेटअप नीचे दिए गए आरेख की तरह दिख सकता है:
MySQL प्रतिकृति
MySQL प्रतिकृति के साथ सबसे बड़ा मुद्दा यह है कि कोई कोरम तंत्र निर्मित नहीं है, जैसा कि गैलेरा क्लस्टर में है। इसलिए यह सुनिश्चित करने के लिए और कदम उठाने की आवश्यकता है कि आपका सेटअप विभाजित मस्तिष्क से प्रभावित नहीं होगा।
क्रॉस-डेटासेंटर स्वचालित विफलताओं से बचने के लिए एक तरीका है। आप अपने फ़ेलओवर समाधान (यह ClusterControl, या MHA या Orchestrator के माध्यम से हो सकता है) को केवल एकल डेटासेंटर में फ़ेलओवर के लिए कॉन्फ़िगर कर सकते हैं। यदि एक पूर्ण डेटासेंटर आउटेज था, तो यह व्यवस्थापक पर निर्भर करेगा कि वह कैसे फ़ेलओवर करें और कैसे सुनिश्चित करें कि विफल डेटासेंटर में सर्वर का उपयोग नहीं किया जाएगा।
इसे और अधिक स्वचालित बनाने के विकल्प हैं। आप प्रतिकृति सेटअप में नोड्स के बारे में डेटा संग्रहीत करने के लिए कॉन्सल का उपयोग कर सकते हैं, और उनमें से कौन सा मास्टर है। फिर यह इस प्रविष्टि को अद्यतन करने के लिए व्यवस्थापक (या कुछ स्क्रिप्टिंग के माध्यम से) पर निर्भर करेगा और दूसरे डेटासेंटर को लिखता है। आप एक ऑर्केस्ट्रेटर/राफ्ट सेटअप से लाभ उठा सकते हैं जहां ऑर्केस्ट्रेटर नोड्स कई डेटासेंटर में वितरित किए जा सकते हैं और विभाजित मस्तिष्क का पता लगा सकते हैं। इसके आधार पर आप विभिन्न कार्रवाइयां कर सकते हैं जैसे, जैसा कि हमने पहले उल्लेख किया है, हमारे कौंसल या आदि में प्रविष्टियां अपडेट करें। मुद्दा यह है कि यह गैलेरा क्लस्टर की तुलना में सेटअप और स्वचालित करने के लिए एक अधिक जटिल वातावरण है। नीचे आप MySQL प्रतिकृति के लिए बहु-डेटासेंटर सेटअप का उदाहरण पा सकते हैं।
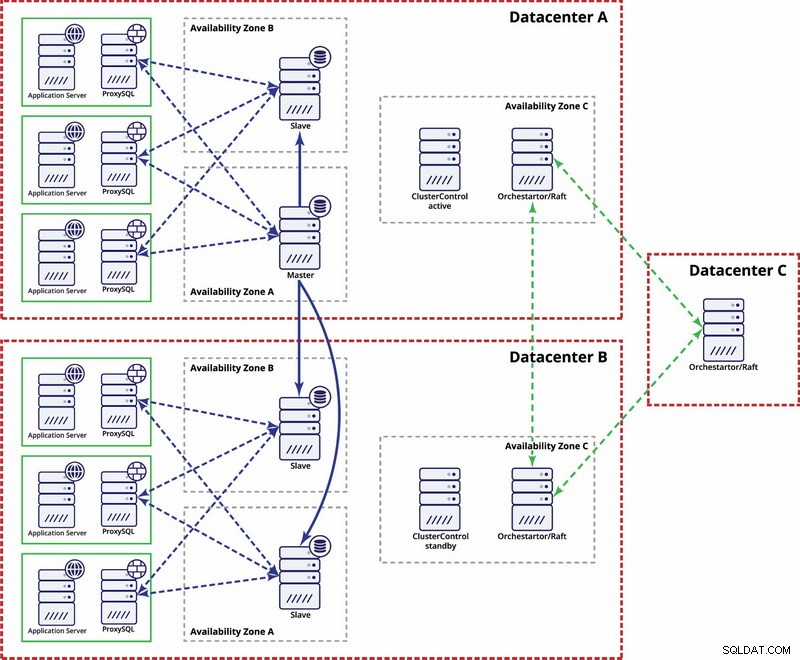
कृपया ध्यान रखें कि आपको इसे काम करने के लिए अभी भी स्क्रिप्ट बनानी होगी, यानी विभाजित मस्तिष्क के लिए ऑर्केस्ट्रेटर नोड्स की निगरानी करें और STONITH को लागू करने के लिए आवश्यक कार्रवाई करें और सुनिश्चित करें कि नेटवर्क के अभिसरण और कनेक्टिविटी के बाद डेटासेंटर A में मास्टर का उपयोग नहीं किया जाएगा। बहाल किया जाए।
स्प्लिट ब्रेन हुआ - आगे क्या करें?
सबसे खराब स्थिति हुई और हमारे पास डेटा बहाव है। हम आपको कुछ संकेत देने की कोशिश करेंगे कि यहां क्या किया जा सकता है। दुर्भाग्य से, सटीक चरण अधिकतर आपके स्कीमा डिज़ाइन पर निर्भर होंगे, इसलिए सटीक कैसे-कैसे मार्गदर्शिका लिखना संभव नहीं होगा।
आपको यह ध्यान में रखना होगा कि अंतिम लक्ष्य एक मास्टर से दूसरे मास्टर में डेटा कॉपी करना और तालिकाओं के बीच सभी संबंधों को फिर से बनाना होगा।
सबसे पहले, आपको यह पहचानना होगा कि कौन सा नोड मास्टर के रूप में डेटा की सेवा जारी रखेगा। यह एक डेटासेट है जिसमें आप अन्य "मास्टर" इंस्टेंस पर संग्रहीत डेटा को मर्ज करेंगे। एक बार यह हो जाने के बाद, आपको पुराने मास्टर के डेटा की पहचान करनी होगी जो वर्तमान मास्टर पर गायब है। यह मैनुअल काम होगा। यदि आपके टेबल में टाइमस्टैम्प हैं, तो आप लापता डेटा को इंगित करने के लिए उनका लाभ उठा सकते हैं। अंततः, बाइनरी लॉग में सभी डेटा संशोधन होंगे ताकि आप उन पर भरोसा कर सकें। आपको डेटा संरचना और तालिकाओं के बीच संबंधों के बारे में अपने ज्ञान पर भी भरोसा करना पड़ सकता है। यदि आपका डेटा सामान्यीकृत है, तो एक तालिका में एक रिकॉर्ड अन्य तालिकाओं के रिकॉर्ड से संबंधित हो सकता है। उदाहरण के लिए, आपका एप्लिकेशन "उपयोगकर्ता" तालिका में डेटा सम्मिलित कर सकता है जो user_id का उपयोग करके "पता" तालिका से संबंधित है। आपको सभी संबंधित पंक्तियों को ढूंढना होगा और उन्हें निकालना होगा।
अगला कदम इस डेटा को नए मास्टर में लोड करना होगा। यहां मुश्किल हिस्सा आता है - यदि आपने अपना सेटअप पहले से तैयार किया है, तो यह केवल कुछ आवेषण चलाने का मामला हो सकता है। यदि नहीं, तो यह बल्कि जटिल हो सकता है। यह प्राथमिक कुंजी और अद्वितीय अनुक्रमणिका मानों के बारे में है। यदि आपके प्राथमिक कुंजी मान किसी प्रकार के यूयूआईडी जनरेटर का उपयोग करके या MySQL में auto_increment_increment और auto_increment_offset सेटिंग्स का उपयोग करके प्रत्येक सर्वर पर अद्वितीय के रूप में उत्पन्न होते हैं, तो आप सुनिश्चित हो सकते हैं कि पुराने मास्टर का डेटा आपको प्राथमिक कुंजी या अद्वितीय नहीं होगा नए मास्टर पर डेटा के साथ महत्वपूर्ण संघर्ष। अन्यथा, आपको पुराने मास्टर से डेटा को मैन्युअल रूप से संशोधित करना पड़ सकता है ताकि यह सुनिश्चित हो सके कि इसे सही तरीके से डाला जा सकता है। यह जटिल लगता है, तो आइए एक उदाहरण देखें।
आइए कल्पना करें कि हम नोड ए पर auto_increment का उपयोग करके पंक्तियों को सम्मिलित करते हैं, जो एक मास्टर है। सादगी के लिए, हम केवल एक पंक्ति पर ध्यान केंद्रित करेंगे। कॉलम 'id' और 'value' हैं।
यदि हम इसे बिना किसी विशेष सेटअप के सम्मिलित करते हैं, तो हमें नीचे की तरह प्रविष्टियाँ दिखाई देंगी:
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’वे दास (बी) को दोहराएंगे। यदि विभाजित मस्तिष्क होता है और पुराने और नए मास्टर दोनों पर लिखा जाता है, तो हम निम्नलिखित स्थिति के साथ समाप्त हो जाएंगे:
ए
1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value4’
1005, ‘some value5’
1006, ‘some value7’1000, ‘some value0’
1001, ‘some value1’
1002, ‘some value2’
1003, ‘some value3’
1004, ‘some value6’
1005, ‘some value8’
1006, ‘some value9’1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’ जब विभाजित मस्तिष्क हुआ, तो यह नीचे जैसा दिखेगा।
नोड ए:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’नोड बी:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1010, ‘some value8’
1012, ‘some value9’अब हम नोड A से लापता डेटा को आसानी से कॉपी कर सकते हैं:
1009, ‘some value4’
1011, ‘some value5’
1013, ‘some value7’और इसे निम्न डेटा सेट के साथ समाप्त होने वाले नोड B पर लोड करें:
1001, ‘some value0’
1003, ‘some value1’
1005, ‘some value2’
1007, ‘some value3’
1008, ‘some value6’
1009, ‘some value4’
1010, ‘some value8’
1011, ‘some value5’
1012, ‘some value9’
1013, ‘some value7’ज़रूर, पंक्तियाँ मूल क्रम में नहीं हैं, लेकिन यह ठीक होना चाहिए। सबसे खराब स्थिति में आपको प्रश्नों में 'मान' कॉलम द्वारा ऑर्डर करना होगा और शायद सॉर्टिंग को तेज़ करने के लिए उस पर एक इंडेक्स जोड़ना होगा।
अब, सैकड़ों या हजारों पंक्तियों और एक अत्यधिक सामान्यीकृत तालिका संरचना की कल्पना करें - एक पंक्ति को पुनर्स्थापित करने का मतलब यह हो सकता है कि आपको उनमें से कई को अतिरिक्त तालिकाओं में पुनर्स्थापित करना होगा। सभी संबंधित पंक्तियों में आईडी (क्योंकि आपके पास सुरक्षात्मक सेटिंग्स नहीं थी) को बदलने की आवश्यकता के साथ और यह सब मैनुअल काम होने के कारण, आप कल्पना कर सकते हैं कि यह सबसे अच्छी स्थिति नहीं है। इसे ठीक होने में समय लगता है और यह एक त्रुटि-प्रवण प्रक्रिया है। सौभाग्य से, जैसा कि हमने शुरुआत में चर्चा की थी, इस संभावना को कम करने के साधन हैं कि विभाजित मस्तिष्क आपके सिस्टम को प्रभावित करेगा या उस काम को कम करने के लिए जो आपके नोड्स को वापस सिंक करने के लिए किए जाने की आवश्यकता है। सुनिश्चित करें कि आप उनका उपयोग करते हैं और तैयार रहें।